Cypher语言基础
一、概述
Cypher 是 Neo4j 图数据库专用的查询语言,其语法直观清晰,设计风格与 SQL 类似,专门用于高效处理图数据。它通过高度可读的声明式语法,简化了图数据的创建、查询、更新与删除(CRUD)操作,尤其擅长表达复杂的图模式匹配。
除了基础操作,Cypher 还支持子查询、聚合计算、条件过滤以及集合操作等高级功能,是图数据库领域最核心的查询工具之一。
二、图数据模型
Cypher 基于 Neo4j 的图数据模型进行设计,该模型由以下三种基本元素组成:
- 节点(Node)
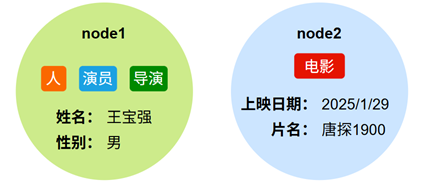
节点代表图中的实体对象,如“人”、“公司”、“电影”等。每个节点:
- 拥有一个或多个标签(Labels)(可选)
- 包含若干属性(Properties)(可选)
如下图所示:
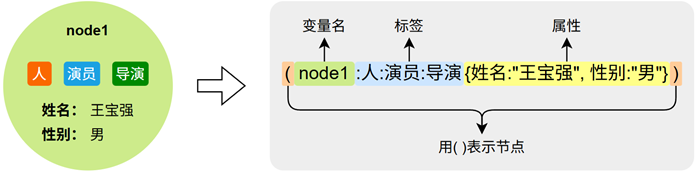
Cypher中用 ( ) 声明一个节点,具体语法如下图所示:
- 关系(Relationship)
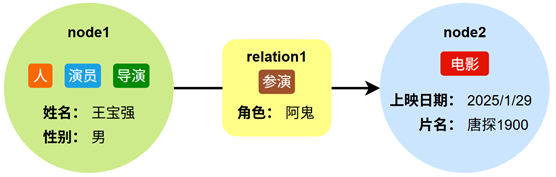
关系用于连接两个节点,表示它们之间的有向连接,如“人 电影”,“人 电影”。每个关系:
- 拥有一个类型(Type)(必须)
- 包含若干个属性(Propertie)(可选)
如下图所示:

Cypher中用 -[ ]-> 声明一个关系,具体语法如下图所示:
- 路径(Path)
路径是由一系列节点和关系连接构成的结构,代表图中实体间的关联链条,是图查询的核心。
三、写入节点
在 Cypher 中,使用 CREATE 语句创建图中的节点。每个节点可以携带一个或多个标签(如 Person、Actor)和一组属性(如 name、gender),这些标签和属性用来标识节点的类型和具体信息。
CREATE (n1:Person:Actor:Director {name: '王宝强', gender: '男'})
CREATE (n2:Movie {title: '唐探1900', released: '2025-01-29'})
四、查询节点
在 Cypher 中,使用 MATCH 语句可以查找图中的节点。但实际上,MATCH 的作用不仅仅是“查询节点”,它的本质是匹配图中符合特定结构(Pattern)的数据。
所谓结构(Pattern),是由节点、关系、路径等组成的图形模板。通过在 MATCH 中描述这个结构,我们可以匹配到图中已有的节点、关系或路径等信息。
- 查询所有节点
MATCH (n)
RETURN n
- 按标签筛选特定的节点
MATCH(n:Person)
RETURN n
- 按标签和属性筛选特定的节点
MATCH (n:Person {name: '王宝强'})
RETURN n;
五、写入关系
通过 CREATE 语句也可以在两个节点之间创建关系。关系必须指定类型,也可以带上属性(例如角色名),用来表示两个实体之间的具体连接方式。
MATCH (n1:Person {name: '王宝强'}), (n2:Movie {title: '唐探1900'})
CREATE (n1)-[:ACTED_IN {role: '阿鬼'}]->(n2)
六、查询关系
在 Cypher 中,使用 MATCH 可以查找图中节点之间的关系。就像查询节点一样,我们通过编写一个图结构模式(pattern)来描述希望匹配的关系结构。
关系模式通常包括起始节点、关系方向和类型、以及目标节点。Cypher 会根据这个结构,从图中找出所有符合条件的关系。
MATCH (n1:Person {name: '王宝强'})-[r]->(n2:Movie {title: '唐探1900'})
RETURN r
七、写入路径
在 Cypher 中,除了可以分别创建节点和关系,还可以通过一条语句同时创建多个节点和它们之间的连接关系,即写入一条完整的路径。
路径结构由节点 ( ) 和关系 -[ ]-> 组合而成,语法直观,能够更高效地表达图中的连接数据。
CREATE (n1:Person:Actor:Singer {name: '刘德华', gender: '男'})- [:ACTED_IN {roles: ['刘建明']}]-> (n2:Movie {title: '无间道', released: '2002-12-12'})
八、查询路径
使用 MATCH 语句也可以查询图中的完整路径结构,返回由多个节点和关系组成的连接链条。在 Cypher 中,可以使用变量(如 path)来表示路径。
MATCH path = (n1:Person)-[r:ACTED_IN]->(n2:Movie) RETURN path
九、修改数据
在 Cypher 中,可以使用 SET 和 REMOVE 对图中的节点或关系进行修改。SET 用于添加或更新属性,也可以为节点添加新的标签;REMOVE 用于删除属性或移除已有的标签。
- 为节点添加属性和标签
MATCH (n1:Person {name: '王宝强'})
SET n1.birth = '1984-05-29', n1: Singer
- 为关系删除和添加属性
MATCH (n1:Person {name: '王宝强'})-[r:ACTED_IN]->(n2:Movie {title: '唐探1900'})
REMOVE r.role
SET r.roles = ['阿鬼']
十、删除数据
使用 DELETE 可以删除节点和关系。在执行删除操作前,通常需要先通过 MATCH 找到对应的节点和关系。如果一个节点还有未删除的关系,必须先删除关系,才能成功删除该节点。
MATCH (n1:Person {name: '王宝强'})-[r:ACTED_IN]->(n2:Movie {title: '唐探1900'})
DELETE n1, r, n2
十一、合并操作
Merge(合并)操作相当于Match和Create操作的一个组合,其会先匹配目标节点或关系是否存在,如果不存在,则创建目标节点,如果存在则不执行任何操作。
- MERGE 节点
// Merge电影节点 MERGE (n2:Movie {title: '唐探1900', released: '2025-01-29'}); // Merge演员节点 MERGE (n1:Person:Actor:Director {name: '王宝强', gender: '男'}) ON CREATE SET n1.create_time = datetime() // 创建时设置创建时间(可选操作) ON MATCH SET n1.update_time = datetime() // 匹配时设置更新时间(可选操作)
- MERGE 关系
// Merge关系 MERGE (n1:Person {name: '王宝强'})-[r:ACTED_IN {roles: ['阿鬼']}]->(n2:Movie {title: '唐探1900'})

 浙公网安备 33010602011771号
浙公网安备 33010602011771号