ChromiumPage(一)
一、ChromiumPage是什么?
ChromiumPage对象和WebPage对象的 d 模式,可操控浏览器。ChromiumPage是 Chromium 内核浏览器的页面,它用 POM 方式封装了操控网页所需的属性和方法。使用它,我们可与网页进行交互,如调整窗口大小、滚动页面、操作弹出框等等。通过从中获取的元素对象,我们还可以跟页面中的元素进行交互,如输入文字、点击按钮、选择下拉菜单等等。甚至,我们可以在页面或元素上运行 JavaScript 代码、修改元素属性、增删元素等。操控浏览器的绝大部分操作,都可以由ChromiumPage及其衍生的对象完成,而它们的功能,还在不断增加。除了与页面和元素的交互,ChromiumPage还扮演着浏览器控制器的角色,一个ChromiumPage对象,就是一个浏览器。可以对标签页进行管理,可以对下载任务进行控制。可以为每个标签页生成独立的页面对象(ChromiumTab),以实现多标签页同时操作,而无需切入切出。随着 3.0 版本脱离对Selenium WebDriver 的依赖,开始为ChromiumPage添加各种各样的功能,
下面通过一个简单的例子,来说明ChromiumPage的工作方式。
# 导入 from DrissionPage import ChromiumPage # 创建对象 page = ChromiumPage() # 访问网页 page.get("https://www.baidu.com") # 搜索框输入内容 page("#kw").input("DrissionPage") # 点击 按钮 page("#su").click() # 等待页面跳转 page.wait.load_start() # 获取要页面跳转 links = page.eles("tag:h3") # 遍历并打印结果 for link in links: print(link.text)
输出如下:
爬虫基础之自动化工具DrissionPage的使用 🚤 页面交互 |DrissionPage官网 g1879/DrissionPage- GitHub 📒 v4.x |DrissionPage官网 DrissionPage(自动化框架)_drissionpage文档-CSDN博客 🔦 行为模式 |DrissionPage官网 DrissionPage· PyPI 【0基础学爬虫】爬虫基础之自动化工具DrissionPage的使... 自动化工具DrissionPage的使用(-) - 知乎 DrissionPage: 基于python的网页自动化工具。既能控制浏览...
二、启动或接管浏览器
ChromiumPage对象和WebPage对象的 d 模式都能控制浏览器,用ChromiumPage()创建页面对象。根据不同的配置,可以接管已打开的浏览器,也可以启动新的浏览器。
- 程序结束时,被打开的浏览器不会主动关闭,以便下次运行程序时使用(由 VSCode 启动的会被关闭)。
- 新手在使用无头模式时需注意,程序关闭后其实浏览器进程还在,只是看不见。
ChromiumPage和WebPage对象为单例,每个浏览器只能有一个该对象。对同一个浏览器重复使用ChromiumPage获取的都是同一个对象。
2.1.ChromiumPage初始化参数
| 初始化参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
addr_or_opts |
strintChromiumOptions |
None |
浏览器启动配置或接管信息。 传入 'ip: port' 字符串、端口数字或 ChromiumOptions对象时按配置启动或接管浏览器;为 None时使用配置文件配置启动浏览器 |
tab_id |
str |
None |
要控制的标签页 id,为None则控制激活的标签页 |
timeout |
float |
None |
整体超时时间,为None则从配置文件中读取,默认10 |
2.2.直接创建
2.2.1.默认方式
下面代码会使用默认配置,自动生成页面对象。
from DrissionPage import ChromiumPage page = ChromiumPage()
创建ChromiumPage对象时会在指定端口启动浏览器,或接管该端口已有浏览器。
- 默认情况下,程序使用 9222 端口,浏览器可执行文件路径为'chrome'。
- 如路径中没找到浏览器可执行文件,Windows 系统下程序会在注册表中查找路径。
- 如果都没找到,则要用下文介绍的手动配置方法。
- 直接创建时,程序默认读取 ini 文件配置,如 ini 文件不存在,会使用内置配置。
可以修改配置文件中的内容,实现所有程序都按的需要进行启动
2.2.2.指定端口或地址
创建ChromiumPage对象时向addr_or_opts参数传入端口号或地址,可接管指定端口浏览器,若端口空闲,使用默认配置在该端口启动一个浏览器。
传入端口时用int类型,传入地址时用'address:port'格式。
# 接管9333端口的浏览器,如该端口空闲,启动一个浏览器 page = ChromiumPage(9333) page = ChromiumPage('127.0.0.1:9333')
2.3.通过配置信息创建
ChromiumOptions专门用于设置浏览器初始状态的类,内置了常用的配置
2.3.1.使用方法
ChromiumOptions用于管理创建浏览器时的配置,内置了常用的配置,并能实现链式操作。
| 初始化参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
read_file |
bool |
True |
是否从 ini 文件中读取配置信息,如果为False则用默认配置创建 |
ini_path |
str |
None |
文件路径,为None则读取默认 ini 文件 |
- 配置对象只有在启动浏览器时生效。
- 浏览器创建后再修改这个配置是没有效果的。
- 接管已打开的浏览器配置也不会生效。
# 导入 ChromiumOptions from DrissionPage import ChromiumPage, ChromiumOptions # 创建浏览器配置对象,指定浏览器路径 co = ChromiumOptions().set_browser_path(r"C:\Program Files\Google\Chrome\Application\chrome.exe") # 用该配置创建页面对象 page = ChromiumPage(addr_or_opts=co) page.get("https://www.baidu.com")
2.3.2.直接指定地址创建
ChromiumPage可以直接接收浏览器地址来创建,格式为 'ip:port'。
使用这种方式时,如果浏览器已存在,程序会直接接管;如不存在,程序会读取默认配置文件配置,在指定端口启动浏览器。
page = ChromiumPage(addr_or_opts='127.0.0.1:9333')
2.3.3.使用指定 ini 文件创建
以上方法是使用默认 ini 文件中保存的配置信息创建对象,你可以保存一个 ini 文件到别的地方,并在创建对象时指定使用它。
准备config.ini文件内容如下:
# 路径相关配置 [paths] # 下载文件保存的目录 download_path = # 存储临时文件的目录 tmp_path = # Chromium 浏览器选项 [chromium_options] # 远程调试协议的地址和端口 address = 127.0.0.1:9222 # Chromium 或 Chrome 可执行文件的路径 browser_path = chrome # 启动浏览器时传递的命令行参数 arguments = ['--no-default-browser-check', '--disable-suggestions-ui', '--no-first-run', '--disable-infobars', '--disable-popup-blocking', '--hide-crash-restore-bubble', '--disable-features=PrivacySandboxSettings4'] # 要加载的 Chrome 扩展列表 extensions = [] # 自定义浏览器行为的首选项(例如弹出窗口、通知) prefs = {'profile.default_content_settings.popups': 0, 'profile.default_content_setting_values': {'notifications': 2}} # 额外的配置标志 flags = {} # 浏览器的加载模式(例如:正常、隐身) load_mode = normal # 要使用的用户配置文件(例如:Default) user = Default # 是否使用自动分配的端口 auto_port = False # 是否使用系统用户配置文件路径 system_user_path = False # 是否仅使用现有的浏览器会话 existing_only = False # 会话相关选项 [session_options] # 请求中包含的 HTTP 头部 headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/603.3.8 (KHTML, like Gecko) Version/10.1.2 Safari/603.3.8', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'connection': 'keep-alive', 'accept-charset': 'GB2312,utf-8;q=0.7,*;q=0.7'} # 超时设置 [timeouts] # 操作的基础超时时间(秒) base = 10 # 页面加载操作的超时时间(秒) page_load = 30 # 脚本执行的超时时间(秒) script = 30 # 代理设置 [proxies] # HTTP 代理地址(如果不使用代理,可以留空) http = # HTTPS 代理地址(如果不使用代理,可以留空) https = # 其他配置 [others] # 失败操作的重试次数 retry_times = 3 # 重试之间的间隔时间(秒) retry_interval = 2
根据上面的配置文件打开浏览器:
from DrissionPage import ChromiumPage, ChromiumOptions # 创建配置对象时指定要读取的ini文件路径 co = ChromiumOptions(ini_path="config.ini") page = ChromiumPage(addr_or_opts=co)
2.4.多浏览器共存
如果想要同时操作多个浏览器,或者自己在使用其中一个上网,同时控制另外几个跑自动化,就需要给这些被程序控制的浏览器设置单独的端口和用户文件夹,否则会造成冲突。
2.4.1.指定独立端口和数据文件夹
每个要启动的浏览器使用一个独立的ChromiumOptions对象进行设置:
from DrissionPage import ChromiumPage, ChromiumOptions # 创建多个配置对象,每个指定不同的端口号和用户文件夹路径 co1 = ChromiumOptions().set_paths(local_port=9111, user_data_path=r"D:\data1") co2 = ChromiumOptions().set_paths(local_port=9222, user_data_path=r"D:\data2") # 创建多个页面对象 page1 = ChromiumPage(addr_or_opts=co1) page2 = ChromiumPage(addr_or_opts=co2) # 每个页面对象控制一个浏览器 page1.get("https://www.baidu.com") page2.get("https://www.bing.com")
注意
- 每个浏览器都要设置独立的端口号和用户文件夹,二者缺一不可。
2.4.2.auto_port()方法
ChromiumOptions对象的auto_port()方法,可以指定程序每次使用空闲的端口和临时用户文件夹创建浏览器。也是每个浏览器要使用独立的ChromiumOptions对象。但这种方法创建的浏览器不能重复使用。
注意:
- auto_port()支持多线程,但不支持多进程。
- 多进程使用时,可用scope参数指定每个进程使用的端口范围,以免发生冲突。
from DrissionPage import ChromiumPage, ChromiumOptions co1 = ChromiumOptions().auto_port() co2 = ChromiumOptions().auto_port() page1 = ChromiumPage(addr_or_opts=co1) page2 = ChromiumPage(addr_or_opts=co2) page1.get("https://www.baidu.com") page2.get("https://www.bing.com")
2.5.创建全新的浏览器
默认情况下,程序会复用之前用过的浏览器用户数据,因此可能带有登录数据、历史记录等。
如果想打开全新的浏览器,可用以下方法:
2.5.1.使用auto_port()
上文提过的auto_port()方法,设置后每次打开的浏览器都是全新的。示例见上文。
2.5.2.手动指定端口和路径
给浏览器用户文件夹路径指定空的路径,以及指定一个空闲的端口,即可打开全新浏览器。
# 从 DrissionPage 库中导入 ChromiumPage 和 ChromiumOptions 类 from DrissionPage import ChromiumPage, ChromiumOptions # 创建一个 ChromiumOptions 对象,配置浏览器的启动选项 co = ChromiumOptions()\ # 设置本地端口为 9333,用于远程调试 .set_local_port(9333)\ # 设置用户数据路径,用于存储浏览器的用户数据(例如配置文件、缓存等) .set_user_data_path(r"D:\tmp") # 使用配置好的 ChromiumOptions 对象创建一个 ChromiumPage 实例 # 这将启动 Chromium 浏览器并应用配置中的选项 page = ChromiumPage(addr_or_opts=co) # 使用 ChromiumPage 实例访问指定的 URL,这里是百度的首页 page.get("https://www.baidu.com")
三、访问网页
ChromiumPage对象和WebPage对象的 d 模式都能控制浏览器访问网页。这里只对ChromiumPage进行说明,后面章节再单独介绍WebPage。
3.1.get()
该方法用于跳转到一个网址。当连接失败时,程序会进行重试。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
url |
str |
必填 | 目标 url,可指向本地文件路径 |
show_errmsg |
bool |
False |
连接出错时是否显示和抛出异常 |
retry |
int |
None |
重试次数,为None时使用页面参数,默认 3 |
interval |
float |
None |
重试间隔(秒),为None时使用页面参数,默认 2 |
timeout |
float |
None |
加载超时时间(秒) |
返回值:
| 返回类型 | 说明 |
|---|---|
bool |
是否连接成功 |
from DrissionPage import ChromiumPage page = ChromiumPage() page.get('https://www.baidu.com')
3.2.设置超时和重试
网络不稳定时,访问页面不一定成功,get()方法内置了超时和重试功能。通过retry、interval、timeout三个参数进行设置。其中,如不指定timeout参数,该参数会使用ChromiumPage的timeouts属性的page_load参数中的值。
# 从 DrissionPage 库中导入 ChromiumPage 类 from DrissionPage import ChromiumPage # 创建一个 ChromiumPage 实例,启动 Chromium 浏览器 page = ChromiumPage() # 使用 ChromiumPage 实例访问指定的 URL # 访问过程中设置了重试次数、重试间隔时间和超时时间 page.get("https://www.baidu.com", retry=1, interval=1, timeout=1.5)
说明:
page.get("https://www.baidu.com"):使用ChromiumPage实例的get方法访问指定的 URL(这里是百度的首页)。get方法用于在浏览器中加载指定的网页。retry=1:设置访问失败时的重试次数为 1 次。如果访问失败,浏览器将尝试重新加载网页一次。interval=1:设置每次重试之间的间隔时间为 1 秒。这是重试操作之间的等待时间。timeout=1.5:设置加载网页的超时时间为 1.5 秒。如果在 1.5 秒内没有加载完成,操作将超时并失败。
3.3.加载模式
3.3.1.概述
加载模式是指程序在页面加载阶段的行为模式,有以下三种:
- normal():常规模式,会等待页面加载完毕,超时自动重试或停止,默认使用此模式
- eager():加载完 DOM 或超时即停止加载,不加载页面资源
- none():超时也不会自动停止,除非加载完成
前两种模式下,页面加载过程会阻塞程序,直到加载完毕才执行后面的操作。
none()模式下,只在连接阶段阻塞程序,加载阶段可自行根据情况执行stop_loading()停止加载。
这样提供给用户非常大的自由度,可等到关键数据包或元素出现就主动停止页面加载,大幅提升执行效率。
注意
- 加载完成是指主文档完成,并不包括由 js 触发的加载和重定向的加载。 当文档加载完成,程序就判断加载完毕,此后发生的重定向或 js 加载数据需用其它逻辑处理。
可通过 ini 文件、ChromiumOptions对象和页面对象的set.load_mode.****()方法进行设置。
from DrissionPage import ChromiumPage page = ChromiumPage() page.set.load_mode.eager() # 设置为eager模式 page.get("https://DrissionPage.cn")
由于eager模式不会加载页面资源,所以页面会乱码
3.3.2.none模式技巧
示例 1,配合监听器
跟监听器配合,可在获取到需要的数据包时,主动停止加载。访问hao123页面监听"api/getkeydata"URL地址的请求是否加载完成,加载完成后获取数据

from DrissionPage import ChromiumPage page = ChromiumPage() page.set.load_mode.none() # 设置加载模式为none page.listen.start("api/getkeydata") # 指定监听目标并启动监听 page.get('http://www.hao123.com/') # 访问网站 packet = page.listen.wait() # 等待数据包 page.stop_loading() # 主动停止加载 print(packet.response.body) # 打印数据包正文
输出:
{'hao123.new.shishi.bangdan.recom': [{'pure_title': '中国艺术体操夺金俄美女外教火了', 'index': '1'}, {'pure_title': '有人宁可损失4万中断日本游飞回国', 'index': '2'}, {'pure_title': '中央救灾物资被倒卖已涉嫌多个罪名', 'index': '3'}, {'pure_title': '岸田文雄称放弃选举将辞任首相', 'index': '4'}, {'pure_title': '14岁少女遭教官3次侵犯嫌犯被刑拘', 'index': '5'}, {'pure_title': '加沙男子正办出生证明妻儿被炸死', 'index': '6'}, {'pure_title': '医生提醒夏季玩水警惕泳池病', 'index': '7', 'url': 'https://www.piyao.org.cn/20240814/cb83bade64b141a0bb8382f82b3cb685/c.html'}]}
示例 2,配合元素查找
跟元素查找配合,可在获取到某个指定元素时,主动停止加载。
from DrissionPage import ChromiumPage page = ChromiumPage() page.set.load_mode.none() # 设置加载模式为none page.get('http://www.hao123.com/') # 访问网站 ele = page.ele("@href=http://www.sina.com.cn/") # 查找@href=http://www.sina.com.cn/的元素 page.stop_loading() # 主动停止加载 print(ele.text) # 输出文本信息
示例 3,配合页面特征
可等待到页面到达某种状态时,主动停止加载。比如多级跳转的登录,可等待 title 变化到最终目标网址时停止。
from DrissionPage import ChromiumPage page = ChromiumPage() page.set.load_mode.none() # 设置加载模式为none page.get("https://www.hao123.com/") # 访问网站 page.wait.title_change("hao123") # 等待title变化出现目标文本 page.stop_loading() # 主动停止加载
四、获取网页信息
成功访问网页后,可使用ChromiumPage自身属性和方法获取页面信息。
操控浏览器除了ChromiumPage,还有ChromiumTab和ChromiumFrame两种页面对象分别对应于标签页对象和<iframe>元素对象,后面会有单独章节介绍。
4.1.页面信息
📌html
此属性返回当前页面 html 文本。
注意
- html 文本不包含<iframe>元素内容。
返回类型:str
📌 json
此属性把请求内容解析成 json。
- 假如用浏览器访问会返回 *.json 文件的 url,浏览器会把 json 数据显示出来,这个参数可以把这些数据转换为dict格式。
- 如果是API返回的json字符串,请使用 SessionPage 对象而不是 ChromiumPage。
返回类型:dict
📌 title
此属性返回当前页面title文本。
返回类型:str
📌 user_agent
此属性返回当前页面 user agent 信息。
返回类型:str
📌 browser_version
此属性返回当前浏览器版本号。
返回类型:str
📌 save()
把当前页面保存为文件,同时返回保存的内容。
- 如果path和name参数都为None,只返回内容,不保存文件。
- Page 对象和 Tab 对象有这个方法。
参数:
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
path |
strPath |
None |
保存路径,为None且name不为None时保存到当前路径 |
name |
str |
None |
保存的文件名,为None且path不为None时使用 title 值 |
as_pdf |
bool |
False |
为Ture保存为 pdf,否则保存为 mhtml 且忽略kwargs参数 |
**kwargs |
多种 | 无 | pdf 生成参数 |
返回值:
| 返回类型 | 说明 |
|---|---|
str |
as_pdf为False时返回 mhtml 文本 |
bytes |
as_pdf为True时返回文件字节数据 |
📌 完整案例
from DrissionPage import ChromiumPage # 创建一个 ChromiumPage 实例,启动 Chromium 浏览器 page = ChromiumPage() # 使用 ChromiumPage 实例访问指定的 URL page.get("https://www.baidu.com") # 获取当前页面的 HTML 文本 html_text = page.html print("页面 HTML 文本:") print(html_text[:500]) # 打印前 500 个字符以避免输出过长 # 获取当前页面的 JSON 内容(如果当前页面返回 JSON 数据) # 假设该页面返回 JSON 数据,示例中实际页面返回的是 HTML,所以返回的是空字典 try: json_data = page.json print("页面 JSON 数据:") print(json_data) except Exception as e: print(f"无法获取 JSON 数据:{e}") # 获取当前页面的标题 page_title = page.title print(f"页面标题:{page_title}") # 获取当前页面的 User-Agent 信息 user_agent = page.user_agent print(f"User-Agent 信息:{user_agent}") # 获取当前浏览器的版本号 browser_version = page.browser_version print(f"浏览器版本号:{browser_version}") # 保存当前页面为文件 # 保存为 mhtml 格式,文件名为 page_title.mhtml,路径为当前目录 file_content = page.save(name=f"{page_title}.mhtml") print("页面已保存为 mhtml 格式。") # 如果需要保存为 PDF 格式,可以设置 as_pdf=True # 例如,将页面保存为 PDF 格式,文件名为 page_title.pdf,路径为当前目录 pdf_content = page.save(name=f"{page_title}.pdf", as_pdf=True) print("页面已保存为 PDF 格式。") # 打印保存的内容类型 if isinstance(file_content, str): print("保存的内容类型:mhtml") elif isinstance(file_content, bytes): print("保存的内容类型:PDF")
说明:
- 创建
ChromiumPage实例: 启动 Chromium 浏览器并创建一个ChromiumPage实例。 - 访问指定的 URL: 使用
page.get()方法访问指定的网页。 - 获取 HTML 文本: 使用
page.html获取当前页面的 HTML 文本。 - 获取 JSON 数据: 使用
page.json获取当前页面的 JSON 数据(如果页面返回 JSON 数据)。请注意,如果页面返回 HTML,而非 JSON 数据,则该调用会失败。 - 获取页面标题: 使用
page.title获取当前页面的标题。 - 获取 User-Agent 信息: 使用
page.user_agent获取当前页面的 User-Agent 信息。 - 获取浏览器版本号: 使用
page.browser_version获取当前浏览器的版本号。 - 保存页面: 使用
page.save()方法将当前页面保存为文件。可以选择保存为 mhtml 格式或 PDF 格式,通过设置as_pdf=True来保存为 PDF 格式。保存的文件名由name参数指定,保存路径由path参数指定。
4.2.窗口信息
📌 rect.size
以tuple返回页面大小,格式:(宽, 高)。
返回类型:Tuple[int, int]
📌 rect.window_size
此属性以tuple返回窗口大小,格式:(宽, 高)。
返回类型:Tuple[int, int]
📌 rect.window_location
此属性以tuple返回窗口在屏幕上的坐标,左上角为(0, 0)。
返回类型:Tuple[int, int]
📌 rect.window_state
此属性以返回窗口当前状态,有'normal'、'fullscreen'、'maximized'、 'minimized'几种。
返回类型:str
📌 rect.viewport_size
此属性以tuple返回视口大小,不含滚动条,格式:(宽, 高)。
返回类型:Tuple[int, int]
📌 rect.viewport_size_with_scrollbar
此属性以tuple返回浏览器窗口大小,含滚动条,格式:(宽, 高)。
返回类型:Tuple[int, int]
📌 rect.page_location
此属性以tuple返回页面左上角在屏幕中坐标,左上角为(0, 0)。
返回类型:Tuple[int, int]
📌 rect.viewport_location
此属性以tuple返回视口在屏幕中坐标,左上角为(0, 0)。
返回类型:Tuple[int, int]
📌 完整案例
from DrissionPage import ChromiumPage import time # 创建一个 ChromiumPage 实例,启动 Chromium 浏览器 page = ChromiumPage() # 访问一个示例 URL page.get("https://www.baidu.com") # 确保页面加载完成 time.sleep(3) # 等待 3 秒以确保页面完全加载 # 获取页面大小(包括滚动条) page_size = page.rect.size print(f"页面大小(包括滚动条):宽 = {page_size[0]}, 高 = {page_size[1]}") # 获取窗口大小 window_size = page.rect.window_size print(f"窗口大小:宽 = {window_size[0]}, 高 = {window_size[1]}") # 获取窗口在屏幕上的位置 window_location = page.rect.window_location print(f"窗口位置:左上角坐标 = ({window_location[0]}, {window_location[1]})") # 获取窗口当前状态 window_state = page.rect.window_state print(f"窗口状态:{window_state}") # 获取视口大小(不含滚动条) viewport_size = page.rect.viewport_size print(f"视口大小(不含滚动条):宽 = {viewport_size[0]}, 高 = {viewport_size[1]}") # 获取包含滚动条的浏览器窗口大小 viewport_size_with_scrollbar = page.rect.viewport_size_with_scrollbar print(f"视口大小(含滚动条):宽 = {viewport_size_with_scrollbar[0]}, 高 = {viewport_size_with_scrollbar[1]}") # 获取页面左上角在屏幕中的坐标 page_location = page.rect.page_location print(f"页面左上角在屏幕中的坐标:左上角坐标 = ({page_location[0]}, {page_location[1]})") # 获取视口在屏幕中的坐标 viewport_location = page.rect.viewport_location print(f"视口在屏幕中的坐标:左上角坐标 = ({viewport_location[0]}, {viewport_location[1]})") # 关闭浏览器 page.quit()
输出如下:
页面大小(包括滚动条):宽 = 1893, 高 = 960 窗口大小:宽 = 1261, 高 = 680 窗口位置:左上角坐标 = (28, 0) 窗口状态:minimized 视口大小(不含滚动条):宽 = 1893, 高 = 960 视口大小(含滚动条):宽 = 1262, 高 = 640 页面左上角在屏幕中的坐标:左上角坐标 = (27, 40) 视口在屏幕中的坐标:左上角坐标 = (27, 40)
五、页面交互
一个 Tab 对象(ChromiumTab和MixTab)控制一个浏览器的标签页,是页面控制的主要单位。ChromiumPage和WebPage也控制一个标签页,只是它们增加了一些浏览器总体控制功能。
5.1.页面跳转
DrissionPage 库的 ChromiumPage 类来进行页面跳转、后退、前进、刷新、停止加载和设置被忽略的 URL 等操作。
📌 get()
该方法用于跳转到一个网址。当连接失败时,程序会进行重试。
page.get('https://www.baidu.com')
📌 back()
此方法用于在浏览历史中后退若干步。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
steps |
int |
1 |
后退步数 |
返回:None
page.back(2) # 后退两个网页
📌 forward()
此方法用于在浏览历史中前进若干步。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
steps |
int |
1 |
前进步数 |
返回:None
page.forward(2) # 前进两步
📌 refresh()
此方法用于刷新当前页面。
page.refresh() # 刷新页面
📌 stop_loading()
此方法用于强制停止当前页面加载。
📌 set.blocked_urls()
此方法用于设置忽略的连接。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
urls |
strlisttupleNone |
必填 | 要忽略的 url,可传入多个,可用'*'通配符,传入None时清空已设置的项 |
示例:
page.set.blocked_urls('*.css*') # 设置不加载css文件
📌 完整案例
from DrissionPage import ChromiumPage import time # 创建一个 ChromiumPage 实例,启动 Chromium 浏览器 page = ChromiumPage() # 访问一个示例 URL print("访问百度首页...") page.get("https://www.baidu.com") print("页面已加载。") # 访问另一个示例 URL print("访问 DrissionPage...") page.get("https://www.drissionpage.cn/") print("DrissionPage 页面已加载。") # 在浏览历史中后退一步 print("后退一步到百度首页...") page.back(1) print("已回到百度首页。") time.sleep(5) # 在浏览历史中前进一步 print("后退一步到DrissionPage首页...") page.forward(1) print("已回到DrissionPage首页。") # 刷新当前页面 print("刷新 DrissionPage 首页...") page.forward(1) print("DrissionPage 页面已经刷新。") # 设置忽略特定的 URL print("设置忽略 CSS 文件的加载...") page.set.blocked_urls("*.css") print("已设置忽略 CSS 文件。")
5.2.元素管理
5.2.1.add_ele() 方法
作用: 用于在页面中添加一个新的元素。可以选择将元素插入到 DOM 中或仅创建一个不插入 DOM 的元素。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
html_or_info |
strTuple[str, dict] |
必填 | 新元素的 html 文本或信息;为tuple可新建不加入到 DOM 的元素 |
insert_to |
strChromiumElementTuple[str, str] |
None |
插入到哪个元素中,可接收元素对象和定位符;如为None,html_or_info是str时添加到 body,否则不添加到 DOM |
before |
strChromiumElementTuple[str, str] |
None |
在哪个子节点前面插入,可接收对象和定位符,为None插入到父元素末尾 |
返回值:
| 返回类型 | 说明 |
|---|---|
ChromiumElement |
新建的元素对 |
添加一个可见的元素:
from DrissionPage import ChromiumPage page = ChromiumPage() page.get("https://www.baidu.com") html = '<a href="https://DrissionPage.cn" target="blank">DrissionPage </a>' # 插入到导航栏 ele = page.add_ele(html, "#s-top-left", "新闻") ele.click()
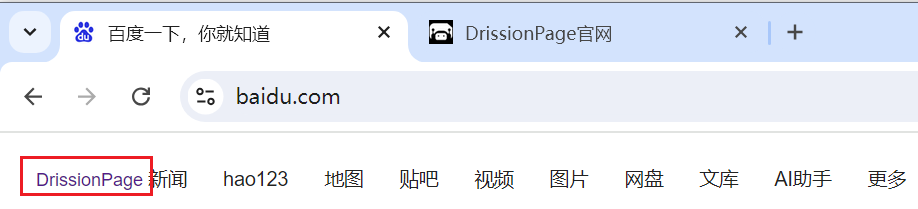
添加一个不可见的元素:
from DrissionPage import ChromiumPage page = ChromiumPage() """ 定义一个元素信息,表示一个链接 使用一个元组 info 来描述一个 HTML 元素。元组的第一个元素 'a' 表示要创建一个 <a> 标签(即链接)。第二个元素是一个字典,包含了该链接的属性,如: 'innerText': 链接的文本内容。 'href': 链接的目标 URL。 'target': 链接的目标窗口属性('blank' 表示在新窗口打开链接 """ info = ('a', {'innerText': 'DrissionPage', 'href': 'https://DrissionPage.cn', 'target': 'blank'}) # 创建一个元素,但不插入到 DOM 中 ele = page.add_ele(info) print(ele) ele.click('js') # 需用js点击
5.2.2.remove_ele()
用于从页面上删除一个元素。 说明作用和含义
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
loc_or_ele |
strTuple[str, str]ChromiumElement |
必填 | 要删除的元素,可以是元素或定 |
from DrissionPage import ChromiumPage # 创建一个 ChromiumPage 实例,启动 Chromium 浏览器 page = ChromiumPage() # 访问一个网页 page.get('https://www.baidu.com') # 添加一个临时元素 html = '<div id="temp-element">This is a temporary element</div>' temp_element = page.add_ele(html) # 删除刚刚添加的临时元素 page.remove_ele(temp_element) # 验证元素是否被删除(可选) if not page.ele('#temp-element'): print("元素已成功删除。") else: print("元素仍然存在。") # 关闭浏览器 page.quit()
5.3.执行js脚本
run_js()
此方法用于执行 js 脚本。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
script |
str |
必填 | js 脚本文本或脚本文件路径 |
*args |
- | 无 | 传入的参数,按顺序在js文本中对应arguments[0]、arguments[1]... |
as_expr |
bool |
False |
是否作为表达式运行,为True时args参数无效 |
timetout |
float |
None |
js 超时时间,为None则使用页面timeouts.script设置 |
返回值
| 返回类型 | 说明 |
|---|---|
Any |
脚本执行结果 |
# 用传入参数的方式执行 js 脚本显示弹出框显示 Hello world! page.run_js('alert(arguments[0]+arguments[1]);', 'Hello', ' world!')
5.3.窗口管理
窗口管理功能藏在set.window属性中。
📌 set.window.max()
此方法用于使窗口最大化。
page.set.window.max()
📌 set.window.mini()
此方法用于使窗口最小化。
📌 set.window.full()
此方法用于使窗口切换到全屏模式。
📌 set.window.normal()
此方法用于使窗口切换到普通模式。
📌 set.window.size()
此方法用于设置窗口大小。只传入一个参数时另一个参数不会变化。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
width |
int |
None |
窗口宽度 |
height |
int |
None |
窗口高度 |
示例:
page.set.window.size(500, 500)
📌 set.window.location()
此方法用于设置窗口位置。只传入一个参数时另一个参数不会变化。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
x |
int |
None |
距离顶部距离 |
y |
int |
None |
距离左边距离 |
示例:
page.set.window.location(500, 500)
📌 set.window.hide()
此方法用于隐藏浏览器窗口。
与 headless 模式不一样,这个方法是直接隐藏浏览器进程。在任务栏上也会消失。只支持 Windows 系统,并且必需已安装 pypiwin32 库才可使用。不过,窗口隐藏后,如果有新窗口出现,整个浏览器又会显现出来。
page.set.window.hide()
注意
- 浏览器隐藏后并没有关闭,下次运行程序还会接管已隐藏的浏览器
- 浏览器隐藏后,如果有新建标签页,会自行显示出来
📌 set.window.show()
此方法用于显示当前浏览器窗口。
📌 完整案例
from DrissionPage import ChromiumPage import time # 创建一个 ChromiumPage 实例,启动 Chromium 浏览器 page = ChromiumPage() # 访问一个网页 page.get("https://www.baidu.com") # 创建最大化 page.set.window.max() time.sleep(2) # 等待2秒以便观察效果 # 使窗口最小化 page.set.window.mini() time.sleep(2) # 等待2秒以便观察效果 # 使窗口切换到全屏模式 page.set.window.full() time.sleep(2) # 等待2秒以便观察效果 # 使窗口切换到普通模式 page.set.window.normal() time.sleep(2) # 等待2秒以便观察效果 # 设置窗口大小 page.set.window.size(800, 600) time.sleep(2) # 等待2秒以便观察效果 # 设置窗口位置 page.set.window.location(200, 200) time.sleep(2) # 等待2秒以便观察效果 # 隐藏窗口 page.set.window.hide() time.sleep(2) # 等待2秒以便观察效果 # 显示窗口 page.set.window.show() time.sleep(2) # 等待2秒以便观察效果
5.4.页面滚动
页面滚动的功能藏在scroll属性中。
📌 scroll.to_top()
此方法用于滚动页面到顶部,水平位置不变。
page.scroll.to_top()
📌 scroll.to_bottom()
此方法用于滚动页面到底部,水平位置不变。
📌 scroll.to_half()
此方法用于滚动页面到垂直中间位置,水平位置不变。
📌 scroll.to_rightmost()
此方法用于滚动页面到最右边,垂直位置不变。
📌 scroll.to_leftmost()
此方法用于滚动页面到最左边,垂直位置不变。
📌 scroll.to_location()
此方法用于滚动页面到滚动到指定位置。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
x |
int |
None |
距离顶部距离 |
y |
int |
None |
距离左边距离 |
示例:
page.scroll.to_location(300, 50)
📌 scroll.up()
此方法用于使页面向上滚动若干像素,水平位置不变。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
pixel |
int |
必填 | 滚动的像素 |
示例:
page.scroll.up(30)
📌 scroll.down()
此方法用于使页面向下滚动若干像素,水平位置不变。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
pixel |
int |
必填 | 滚动的像素 |
📌 scroll.right()
此方法用于使页面向右滚动若干像素,垂直位置不变。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
pixel |
int |
必填 | 滚动的像素 |
📌 scroll.left()
此方法用于使页面向左滚动若干像素,垂直位置不变。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
pixel |
int |
必填 | 滚动的像素 |
📌 scroll.to_see()
此方法用于滚动页面直到元素可见。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
loc_or_ele |
strtupleChromiumElement |
必填 | 元素的定位信息,可以是元素、定位符 |
center |
boolNone |
None |
是否尽量滚动到页面正中,为None时如果被遮挡,则滚动到页面正中 |
示例:
# 滚动到某个已获取到的元素 ele = page.ele('tag:div') page.scroll.to_see(ele) # 滚动到按定位符查找到的元素 page.scroll.to_see('tag:div')
📌 完整案例
from DrissionPage import ChromiumPage import time # 创建一个 ChromiumPage 实例,启动 Chromium 浏览器 page = ChromiumPage() # 访问一个网页 page.get("https://www.baidu.com") # 输入内容 page("#kw").input("DrissionPage") page("#su").click() # 设置窗口大小 page.set.window.size(800, 600) time.sleep(2) # 等待2秒以便观察效果 # 滚动到页面底部 page.scroll.to_bottom() time.sleep(2) # 等待2秒以便观察效果 # 滚动到页面顶部 page.scroll.to_top() time.sleep(2) # 等待2秒以便观察效果 # 滚动到页面的垂直中间位置 page.scroll.to_half() time.sleep(2) # 等待2秒以便观察效果 # 滚动到页面的最右边 page.scroll.to_rightmost() time.sleep(2) # 等待2秒以便观察效果 # 滚动到页面的最左边 page.scroll.to_leftmost() time.sleep(2) # 等待2秒以便观察效果 # 示例:滚动到指定位置(例如:水平位置300像素,垂直位置50像素) page.scroll.to_location(300, 50) time.sleep(2) # 等待2秒以便观察效果 # 向上滚动30像素 page.scroll.up(30) time.sleep(2) # 等待2秒以便观察效果 # 向下滚动30像素 page.scroll.down(30) time.sleep(2) # 等待2秒以便观察效果 # 向右滚动30像素 page.scroll.right(30) time.sleep(2) # 等待2秒以便观察效果 # 向左滚动30像素 page.scroll.left(30) time.sleep(2) # 等待2秒以便观察效果 # 示例:滚动到某个已获取到的元素(例如:搜索框) search_box = page.ele('#kw') page.scroll.to_see(search_box) time.sleep(2) # 等待2秒以便观察效果
5.5.滚动设置
页面滚动有两种方式,
- 第一种是滚动时直接跳到目标位置,
- 第二种是平滑滚动,需要一定时间。后者滚动时间难以确定,容易导致程序不稳定,点击不准确的问题。
一些网站会在 css 设置中指定网站使用平滑滚动,这是我们不希望的,该库没有强制修改,而是提供两项设置供开发者选择。
📌 set.scroll.smooth()
此方法设置网站是否开启平滑滚动。建议用此方法为网页关闭平滑滚动。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
on_off |
bool |
True |
bool表示开或关 |
示例:
page.set.scroll.smooth(on_off=False)
📌 set.scroll.wait_complete()
此方法用于设置滚动后是否等待滚动结束。在不想关闭网页平滑滚动功能时,可开启此设置以保障滚动结束后才执行后面的步骤
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
on_off |
bool |
True |
bool表示开或关 |
示例:
page.set.scroll.wait_complete(on_off=True)
5.6.js弹窗处理
📌 handle_alert()
此方法用于处理提示框。
- 它能够设置等待时间,等待提示框出现才进行处理,若超时没等到提示框,返回False。
- 也可只获取提示框文本而不处理提示框。 还可以处理下一个出现的提示框,这在处理离开页面时触发的弹窗非常有用。
注意
- 程序无法接管一个已经弹出了提示框的浏览器或标签页。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
accept |
boolNone |
True |
True表示确认,False表示取消,None不会按按钮但依然返回文本值 |
send |
str |
None |
处理 prompt 提示框时可输入文本 |
timeout |
float |
None |
等待提示框出现的超时时间,为None时使用页面整体超时时间 |
next_one |
bool |
False |
是否处理下一个出现的弹窗,为True时timeout参数无效 |
返回值:
| 返回类型 | 说明 |
|---|---|
str |
提示框内容文本 |
False |
未等到提示框则返回False |
示例:
准备html代码如下:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="x-ua-compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>alert</title> </head> <body> <input type="button" id="alertButton" value="alert" onclick="alertButton()"> <input type="button" id="confirmButton" value="confirm" onclick="confirmButton()"> <input type="button" id="promptButton" value="prompt" onclick="promptButton()"> <script> function alertButton() { alert('我是普通的alert提示框'); }; function confirmButton() { var msg = confirm('点击[确定]或者[取消]按钮'); if (msg) { alert('你点击的是[确定按钮]'); } else { alert('你点击的是[取消按钮]'); } }; function promptButton() { var msg = prompt('输入一个值:', '我是默认值'); if (msg) { alert('输入的值为:\n' + msg); } else { alert('输入值为空'); } }; </script> </body> </html>
python代码如下:
import os import time from DrissionPage import ChromiumPage page = ChromiumPage() file_path = 'file:///' + os.path.abspath('filetest.html') # 打开页面 page.get(file_path) # 点击出现弹窗 page("#promptButton").click() time.sleep(2) # 等待2秒以便观察效果 # prompt 提示框输入文本并点击确定 page.handle_alert(accept=False, send="hello") time.sleep(2) # 等待2秒以便观察效果 # 确认提示框并获取提示框文本,但是我的案例中连续有两个弹窗,这里并不能处理 txt = page.handle_alert() # 不处理提示框,只获取提示框文本 # txt = page.handle_alert(accept=None)
📌 自动处理
标签页对象可使用set.auto_handle_alert()方法设置自动处理该 tab 的提示框,使提示框不会弹窗而直接被处理掉。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
on_off |
bool |
True |
开或关 |
accept |
bool |
True |
确定还是取消 |
示例:
from DrissionPage import ChromiumPage p = ChromiumPage() p.set.auto_handle_alert() # 这之后出现的弹窗都会自动确认
准备完整案例
import os import time from DrissionPage import ChromiumPage page = ChromiumPage() # 设置自动处理该 tab 的提示框,使提示框不会弹窗而直接被处理掉。 page.set.auto_handle_alert() file_path = 'file:///' + os.path.abspath('filetest.html') # 打开页面 page.get(file_path) # 点击出现弹窗 page("#promptButton").click() time.sleep(2) # 等待2秒以便观察效果 # prompt 提示框输入文本并点击确定 page.handle_alert(accept=False, send="hello") time.sleep(2) # 等待2秒以便观察效果
📌 全局自动处理
Page 对象的set.auto_handle_alert()方法比 Tab 对象的多一个all_tabs参数,可用于指定是否全局设置自动处理。设置后,所有 tab 的弹窗都会根据设置自动处理。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
on_off |
bool |
True |
开或关 |
accept |
bool |
True |
确定还是取消 |
all_tabs |
bool |
False |
是否为全局设置 |
示例:
from DrissionPage import ChromiumPage p = ChromiumPage() p.set.auto_handle_alert(all_tabs=True) # 这之后出现的弹窗都会自动确认
5.7.关闭浏览器
quit():此方法用于关闭浏览器。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
timeout |
float |
5 |
等待浏览器关闭超时时间(秒) |
force |
bool |
True |
关闭超时是否强制终止进程 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号