查找元素(一)
一、基本用法
所有页面对象和元素对象(包括<iframe>和 shadow-root),都可以在自己内部查找元素。元素对象还能以自己为基准,相对定位其它元素。定位元素大致有以下几种方法,将在后续小节中详细说明。
- 在页面或元素内查找子元素
- 根据 DOM 结构相对定位
- 根据视觉位置相对定位
所有的查找元素方法,都可以使用DrissionPage自创的查找语法、xpath、css selector和 selenium 的定位符元组,去查找元素。假设有这样一个页面:
<html> <body> <div id="one"> <p class="p_cls" name="row1">第一行</p> <p class="p_cls" name="row2">第二行</p> <p class="p_cls">第三行</p> </div> <div id="two"> helloworld </div> </body> </html>
用页面对象去获取其中的元素:
div1 = tab.ele('#one') # 获取 id 为 one 的元素 p1 = tab.ele('@name=row1') # 获取 name 属性为 row1 的元素 div2 = tab.ele('helloworld') # 获取包含"hellworld"文本的元素 div_list = tab.eles('tag:div') # 获取所有div元素
也可以获取到一个元素,然后在它里面或周围查找元素:
div1 = tab.ele('#one') # 获取到一个元素div1 p_list = div1.eles('tag:p') # 在div1内查找所有p元素 div2 = div1.next() # 获取div1后面一个元素
案例如下:
from DrissionPage import SessionPage # 创建页面对象,SessionPage 是用于创建和管理页面会话的类 page = SessionPage() # 使用页面对象访问指定的 URL,这里是 Gitee 的 Explore 页面 page.get("https://gitee.com/explore/all") # 在页面中查找所有 <h3> 元素,t:h3 是选择器,t 表示标签,h3 是标签名 items = page.eles("t:h3") # 遍历所有找到的 <h3> 元素,排除最后一个元素 for item in items[:-1]: # 获取当前 <h3> 元素下的 <a> 标签元素,'tag:a' 是选择器,tag 表示标签,a 是标签名 lnk = item('tag:a') # 输出 <a> 标签的文本内容和链接地址 print(lnk.text, lnk.link)
输出如下:
广州中科云飞科技创新有限公司/InnoFlight-MSDK https://gitee.com/qw1357802/innoflight-msdk 沉默王二/paicoding https://gitee.com/itwanger/paicoding 深圳高通半导体有限公司/GT-HMI Builder https://gitee.com/genitop/GT-HMI-Builder 舒登登/PclCSharp https://gitee.com/shudengdeng/pcl-csharp Ascend/cann-hccl https://gitee.com/ascend/cann-hccl Cambricon/mlu-ops https://gitee.com/cambricon/mlu-ops Cambricon/cnindex https://gitee.com/cambricon/cnindex godo/godoos https://gitee.com/ruitao_admin/godoos 秦派软件/AtomUI https://gitee.com/pulsarware/atomui dromara/dax-pay https://gitee.com/dromara/dax-pay DENGCHOW/XhngGPU https://gitee.com/dengchow/XhngGPU Vue.js/core https://gitee.com/vuejs/core 裴云飞/桃夭 https://gitee.com/zhongte/taoyao Ericple/log4a https://gitee.com/ericple/log4a deepflowio/deepflow https://gitee.com/deepflowio/deepflow
二、定位语法
下面介绍DrissionPage 自创的查找元素语法。
- 查找语法能用于指明以哪种方式去查找指定元素,定位语法简洁明了,熟练使用可大幅提高程序可读性。
- 所有涉及获取元素的操作都可以使用定位语法,如
ele()、actions.move_to()、wait.eles_loaded()、get_frame()等等。 - 查找语法用于简化代码,提高可读性,但并不覆盖所有复杂场景。很复杂的场景可直接用 xpath 查找。
<html> <body> <div id="one"> <p class="p_cls" id="row1" data="a">第一行</p> <p class="p_cls" id="row2" data="b">第二行</p> <p class="p_cls">第三行</p> </div> <div id="two"> 第二个div </div> </body> </html>
2.1.基本概念
| 写法 | 说明 | 示例 |
|---|---|---|
@tag() |
标签名 | 即<div id="one">中的div |
@**** |
标签体中的属性 | 如<div id="one">中的id,写作'@id' |
@text() |
元素文本 | 即<p class="p_cls">第三行</p>中的'第三行' |
@tag()和@text()后面加上'()',是为了避免和普通属性冲突。
tab.ele('@id=one') # 获取第一个id为one的元素 tab.ele('@tag()=div') # 获取第一个div元素 tab.ele('@text()=第一行') # 获取第一个文本为“第一行”的元素
2.2.基本逻辑
DrissionPage 查找元素的语法可以帮助你通过各种属性组合来精确地定位 HTML 元素。以下是常用的查找语法和方法:
2.2.1.单属性匹配符 @
用法: @属性名=属性值
说明: 查找具有指定属性名和属性值的元素。
ele = tab.ele('@id=one') # 查找 id 属性为 'one' 的元素2. 多属性匹配符 @@
2.2.2.多属性与匹配符 @@
用法: @@属性1=值1@@属性2=值2
说明: 查找同时满足多个属性值的元素。
ele = tab.ele('@@class=p_cls@@text()=第二行') # 查找 class 为 'p_cls' 且文本为 '第二行' 的元素
2.2.3.多属性或匹配符 @|
用法: @|属性1=值1@|属性2=值2
说明: 查找满足任一属性条件的元素。
eles = tab.eles('@|id=row1@|id=row2') # 查找 id 为 'row1' 或 'row2' 的元素
2.2.4.否定匹配符 @!
用法: @!属性名=属性值 或 @!属性名
说明: 查找不满足指定条件的元素。
ele = tab.ele('@!id=row1') # 查找 id 不等于 'row1' 的元素 ele = tab.ele('@!class') # 查找没有 class 属性的元素
2.2.5.混合使用
@@和@|不能同时出现的查找语句中,即一个查找语句只能是与关系或者或关系。
@!则可与两者混合使用。混用时,与还是或关系视@@还是@|而定。
- 当语句中有多个
tag()时,如果全部都没有被@!修饰,它们是与关系;如有任一个被@!修饰,它们是或关系。tag()与其他属性之间是与关系。
# 匹配class等于p_cls且id不等于row1的元素 tab.ele('@@class=p_cls@!id=row1') # 匹配class等于p_cls或id不等于row1的元素 tab.ele('@|class=p_cls@!id=row1')
2.3.匹配模式
匹配模式指某个查询中匹配条件的方式,有精确匹配、模糊匹配、匹配开头、匹配结尾四种。
注意
- tag()属性无论用哪种匹配模式,都会视作=。
2.3.1.精确匹配 =
表示精确匹配,匹配完全符合的文本或属性。
ele = tab.ele('@id=row1') # 获取id属性为'row1'的元素
2.3.2.模糊匹配 :
表示模糊匹配,匹配含有指定字符串的文本或属性。
ele = tab.ele('@id:ow') # 获取id属性包含'ow'的元素
2.3.3.匹配开头 ^
表示匹配开头,匹配开头为指定字符串的文本或属性。
ele = tab.ele('@id^row') # 获取id属性以'row'开头的元素
2.3.4.匹配结尾 $
表示匹配结尾,匹配结尾为指定字符串的文本或属性。
ele = tab.ele('@id$w1') # 获取id属性以'w1'结尾的元素
2.4.常用语法
基于上述基本逻辑,本库提供了一些更已于使用和阅读的语法。
2.4.1.id 匹配符 #
用于匹配id属性,只在语句最前面且单独使用时生效。相当于单属性查找@id=****。可与匹配模式配合使用。
ele = tab.ele('#one') # 查找id为one的元素 ele = tab.ele('#=one') # 和上面一行一致 ele = tab.ele('#:ne') # 查找id属性包含ne的元素 ele = tab.ele('#^on') # 查找id属性以on开头的元素 ele = tab.ele('#$ne') # 查找id属性以ne结尾的元素
2.4.2.class 匹配符 .
用于匹配class属性,只在语句最前面且单独使用时生效,相当于单属性查找@class=****。可配合匹配模式使用。
说明
- 在面对多个 class 的元素时,DrissionPage 与 selenium 处理方式不一样,无需将空格替换成'.'。 而是将整个 class 视作普通字符串,空格视作普通字符对待,会比较直观。
ele = tab.ele('.p_cls') # 查找class属性为p_cls的元素 ele = tab.ele('.=p_cls') # 与上一行一致 ele = tab.ele('.:_cls') # 查找class属性包含_cls的元素 ele = tab.ele('.^p_') # 查找class属性以p_开头的元素 ele = tab.ele('.$_cls') # 查找class属性以_cls结尾的元素
2.4.3.文本匹配符 text
用于匹配元素文本。只在语句最前面且单独使用时生效,相当于单属性查找@text()=****。可配合匹配模式使用。
- 如果元素内有多个直接的文本节点,精确查找时可匹配所有文本节点拼成的字符串,模糊查找时可匹配每个文本节点。
- 如果查找语句没有任何本节介绍的匹配符,默认模糊匹配文本。即ele('第三行')相当于ele('text:第三行')。
注意
- 如果要匹配的文本包含特殊字符(如' '、'>'),需将其转换为十六进制形式,详见《语法速查表》一节。
是一种 HTML 实体,用于表示不间断空格(non-breaking space)。它的作用是在网页中插入一个空格符号,该空格不会被浏览器自动移除或换行。
ele = tab.ele('text=第二行') # 查找文本为“第二行”的元素 ele = tab.ele('text:第二') # 查找文本包含“第二”的元素 ele = tab.ele('第二') # 与上一行一致 ele = tab.ele('第\u00A0二') # 匹配包含 文本的元素,需将 转为\u00A0
若要查找的文本包含text: ,可下面这样写,即第一个text: 为关键字,第二个是要查找的内容:
ele2 = tab.ele('text:text:')
2.4.4.类型匹配符 tag
用于匹配某类型元素。只在语句最前面且单独使用时生效,相当于单属性查找@tag()=****。
可与单属性查找或多属性配合使用。tag:与tag=效果一致,没有tag^和tag$语法。
ele = tab.ele('tag:div') # 查找第一个div元素 ele = tab.ele('tag:p@class=p_cls') # 与单属性查找配合使用 ele = tab.ele('tag:p@@class=p_cls@@text()=第二行') # 与多属性查找配合使用
注意
- tag:div@text():abc 和 tag:div@@text():abc 是有区别的,前者只在div的直接文本节点搜索,后者搜索div的整个内部。
2.4.5.css selector 匹配符 css
表示用 css selector 方式查找元素。只在语句最前面且单独使用时生效。
css:与css=效果一致,没有css^和css$语法。
ele = tab.ele('css:.div') # 查找 div 元素 ele = tab.ele('css:>div') # 查找 div 子元素元素,这个写法是本库特有,原生不支持
2.4.6.xpath 匹配符 xpath
表示用 xpath 方式查找元素。只在语句最前面且单独使用时生效。
xpath:与xpath=效果一致,没有xpath^和xpath$语法。
说明:
- 元素对象的ele()支持完整的 xpath 语法,如能使用 xpath 直接获取元素属性(字符串类型)。
ele2 = ele1.ele('xpath:.//div') # 查找后代中第一个 div 元素 ele2 = ele1.ele('xpath://div') # 和上面一行一样,查找元素的后代时,// 前面的 . 可以省略 ele_class_str = ele1.ele('xpath://div/@class') # 使用xpath获取div元素的class属性(页面元素无此功能)
说明
- 查找元素的后代时,selenium 原生代码要求 xpath 前面必须加.,否则会变成在全个页面中查找。 作者觉得这个设计是画蛇添足,既然已经通过元素查找了,自然应该只查找这个元素内部的元素。 所以,用 xpath 在元素下查找时,最前面//或/前面的.可以省略。
2.4.7.selenium 的 loc 元组
查找方法能直接接收 selenium 原生定位元组进行查找,便于项目迁移。
from DrissionPage.common import By # 查找id为one的元素 loc1 = (By.ID, 'one') ele = tab.ele(loc1) # 按 xpath 查找 loc2 = (By.XPATH, '//p[@class="p_cls"]') ele = tab.ele(loc2)
三、页面或元素内查找
3.1.页面或元素内查找
在页面自动化中,ele() 和 eles() 方法用于从页面或元素内部查找指定的子元素。这些方法允许您根据需要进行精确的元素定位。以下是如何在页面对象和元素对象中使用这些方法:
3.1.1. ele() 方法
- 功能: 用于查找第一个匹配的子元素。如果存在多个匹配元素,只会返回第一个。
- 使用场景: 适用于当您只需要获取单个子元素时。
# 从页面对象中查找第一个id为'login'的元素 login_button = page.ele('#login') # 从元素对象中查找第一个class为'button'的子元素 submit_button = parent_div.ele('.button'
3.1.2. eles() 方法
- 功能: 用于查找所有匹配的子元素,并返回一个包含所有匹配元素的列表。
- 使用场景: 适用于当您需要处理多个匹配元素时。
# 从页面对象中查找所有class为'item'的元素 items = page.eles('.item') # 从元素对象中查找所有class为'child'的子元素 children = parent_div.eles('.child')
3.1.3.应用示例
选择器示例:
- ID 选择器:
#id - Class 选择器:
.class - 属性选择器:
[attribute=value] - 文本选择器:
text:内容 - Tag 选择器:
tag:element
<html> <body> <div id="main"> <button class="btn" id="start">Start</button> <button class="btn" id="stop">Stop</button> </div> </body> </html>
- 查找页面内的第一个按钮:
start_button = page.ele('#start')
- 查找
maindiv 内的所有按钮:
main_div = page.ele('#main') buttons = main_div.eles('.btn')
3.2.静态方式查找
静态元素即 s 模式的SessionElement元素对象,是纯文本构造的,处理速度非常快。对于复杂的页面,要在成百上千个元素中采集数据时,转换为静态元素可把速度提升几个数量级。实践表明用同一套逻辑,仅仅把元素转换为静态,就把一个要 30 秒才完成的页面,加速到零点几秒完成。我们甚至可以把整个页面转换为静态元素,再在其中提取信息。当然,这种元素不能进行点击等交互。用s_ele()可在把查找到的动态元素转换为静态元素输出,或者获取元素或页面本身的静态元素副本。
3.2.1.s_ele()
页面对象和元素对象都拥有此方法,用于查找第一个匹配条件的元素,获取其静态版本。页面对象和元素对象的s_ele()方法参数名称稍有不同,但用法一样。
from DrissionPage import ChromiumPage # 初始化 ChromiumPage page = ChromiumPage() # 打开百度首页 page.get("https://gitee.com/explore/all") # 将动态元素转换为静态元素 info = page.s_ele('.section') # 输出静态元素的(标签,文本信息) print(info.tag, info.text) # 关闭浏览器 page.quit()
3.2.2.s_eles()
此方法与s_ele()相似,但返回的是匹配到的所有元素组成的列表,或属性值组成的列表。
from DrissionPage import ChromiumPage # 初始化 ChromiumPage page = ChromiumPage() # 打开百度首页 page.get("https://gitee.com/explore/all") # 将动态元素转换为静态元素,返回的是匹配到的所有元素组成的列表,或属性值组成的列表。 items = page.s_eles('xpath://h3/a') # 遍历所有元素组成的列表,分别获取文本和链接 for item in items: # 输出 <a> 标签的文本内容和链接地址 print(item.text, item.link) # 关闭浏览器 page.quit()
输出如下:
Lucene.Jin/Lucene Server https://gitee.com/jinjiG/lucene-server devlive-community/InfoSphere https://gitee.com/devlive-community/infosphere dotNET China/MiniAuth https://gitee.com/dotnetchina/MiniAuth 三鲤/金鱼Scheme https://gitee.com/LiiiLabs/goldfish 广联达科技股份有限公司/GDMPLab https://gitee.com/glodon/gdmplab Dream Num/univer https://gitee.com/dream-num/univer 广州中科云飞科技创新有限公司/InnoFlight-MSDK https://gitee.com/qw1357802/innoflight-msdk 沉默王二/paicoding https://gitee.com/itwanger/paicoding 深圳高通半导体有限公司/GT-HMI Builder https://gitee.com/genitop/GT-HMI-Builder 舒登登/PclCSharp https://gitee.com/shudengdeng/pcl-csharp Ascend/cann-hccl https://gitee.com/ascend/cann-hccl Cambricon/mlu-ops https://gitee.com/cambricon/mlu-ops Cambricon/cnindex https://gitee.com/cambricon/cnindex godo/godoos https://gitee.com/ruitao_admin/godoos 秦派软件/AtomUI https://gitee.com/pulsarware/atomui
3.3.获取页面焦点元素
使用页面对象的active_ele属性获取页面上焦点所在元素。
ele = tab.active_ele
以百度搜索页面为例进行演示:
from DrissionPage import ChromiumPage # 初始化 ChromiumPage page = ChromiumPage() # 打开指定页面 page.get("https://www.baidu.com") # 输入内容到搜索框 search_box = page.ele("#kw").input("DrissionPage") # 获取当前页面上的焦点元素 focus_element = page.active_ele # 输出焦点元素的属性 print("焦点元素的 HTML 内容:", focus_element.html) # 关闭浏览器 page.quit()
3.4.<iframe>中查找
3.4.1.查找<iframe>元素
<iframe>和<frame>也可以用ele()查找到,生成的对象是ChromiumFrame而不是ChromiumElement。但不建议用ele()获取<iframe>元素,因为 IDE 无法正确提示后续操作。建议用 Page 对象的get_frame()方法获取。使用方法与ele()一致,可以用定位符查找。还增加了用序号、id、name 属性定位元素的功能。示例:
iframe = page.get_frame(1) # 获取页面中第一个iframe元素 iframe = page.get_frame('#theFrame') # 获取页面id为theFrame的iframe元素对象
通过126邮箱演示:
from DrissionPage import ChromiumPage # 初始化 ChromiumPage page = ChromiumPage() # 打开百度首页 page.get("https://www.126.com/") # 通过xpath定位iframe iframe = page.get_frame('xpath://div[@id="loginDiv"]/iframe') # 定位邮箱输入框输入邮箱 page.ele("@name=email").input("Auguses@126.com") # 输入密码 page.ele("@name=password").input("Qqweasd2543") # 点击登录 page.ele("@id=dologin").click() # 关闭浏览器 page.quit()
3.4.2.在页面下跨级查找
与 selenium 不同,本库可以直接查找同域<iframe>里面的元素。而且无视层级,可以直接获取到多层<iframe>里的元素。无需切入切出,大大简化了程序逻辑,使用更便捷。
假设在页面中有个两级<iframe>,其中有个元素<div id='abc'></div>,可以这样获取:
page = ChromiumPage() ele = page('#abc')
获取前后无需切入切出,也不影响获取页面上其它元素。如果用 selenium,要这样写:
driver = webdriver.Chrome() driver.switch_to.frame(0) driver.switch_to.frame(0) ele = driver.find_element(By.ID, 'abc') driver.switch_to.default_content()
显然比较繁琐,而且切入到<iframe>后无法对<iframe>外的元素进行操作。
from DrissionPage import ChromiumPage # 初始化 ChromiumPage page = ChromiumPage() # 打开百度首页 page.get("https://www.126.com/") # 通过xpath定位iframe iframe = page.get_frame('xpath://div[@id="loginDiv"]/iframe') # 定位邮箱输入框输入邮箱 email_box = page.ele("@name=email") email_box.clear() email_box.input("Auguses@126.com") # 输入密码 page.ele("@name=password").input("Qqweasd2543") # 点击登录 page.ele("@id=dologin").click() # 点击会员,和selenium不同的是,不需要进行切换出iframe,即可选择选择 page.ele("@href=https://v.mail.163.com/?utm_source=126loginnav").click() # 关闭浏览器 # page.quit()
3.4.3.在 iframe 元素下查找
本库把<iframe>看作一个特殊元素/页面对象看待,可以实现同时操作多个<iframe>,而无需来回切换。
对于跨域名的<iframe>,我们无法通过页面直接查找里面的元素,可以先获取到<iframe>元素,再在其下查找。当然,非跨域<iframe> 也可以这样操作。
假设一个<iframe>的 id 为 'iframe1',要在其中查找一个 id 为'abc'的元素:
page = ChromiumPage() iframe = page('#iframe1') ele = iframe('#abc')
这个<iframe>元素是一个页面对象,因此可以继续在其下进行跨<iframe>查找(相对这个<iframe>不跨域的)。
126邮箱案例如下:
from DrissionPage import ChromiumPage # 初始化 ChromiumPage page = ChromiumPage() # 打开百度首页 page.get("https://www.126.com/") # 通过xpath定位iframe,这个<iframe>元素是一个页面对象可以继续在其下进行跨<iframe>查找 iframe = page('xpath://div[@id="loginDiv"]/iframe') # <iframe>元素是一个页面对象,在里面继续定位邮箱输入框 email_box = iframe("@name=email") email_box.clear() email_box.input("Auguses@126.com") # 输入密码 iframe("@name=password").input("Qqweasd2543") # 点击登录 iframe("@id=dologin").click() # 点击会员,和selenium不同的是,不需要进行切换出iframe,即可选择选择 page.ele("@href=https://v.mail.163.com/?utm_source=126loginnav").click() # 关闭浏览器 # page.quit()
3.5.ShadowRoot中查找
shadow-root是什么?
- Shadow Root是Web组件技术中的一个重要概念,它属于Shadow DOM技术的一部分。Shadow DOM提供了一种封装样式和DOM结构的方法,通过创建隔离的DOM树,可以避免样式和脚本冲突,有助于开发可重用、封装良好的组件。Shadow Root允许开发者在不影响主文档DOM结构的情况下,添加额外的DOM结构和样式,从而实现组件的内部细节与外部隔离,提高代码的可维护性和重用性。在测试和自动化脚本中,可以通过适当的方法访问和操作Shadow DOM内的元素,确保了即使在复杂的页面结构中也能精确地定位和操作元素。
- Shadow Root可以通过
Element.createShadowRoot()方法创建,并附加到一个元素节点上作为shadow-host。这种技术使得开发者能够在不干扰主文档DOM结构的同时,对组件的内部进行详细的控制和定制。通过Shadow DOM,开发者可以更好地控制组件的外观和行为,同时保持代码的清晰和可维护性3。 - 总的来说,Shadow Root是Web开发中一个强大的工具,它通过提供隔离的DOM树和样式封装,使得开发者能够创建更加模块化和可重用的Web组件,同时也有助于提高测试和自动化的效率。
本库把 shadow-root 也作为元素对象看待,是为ShadowRoot对象。 该对象可与普通元素一样查找下级元素和 DOM 内相对定位。对ShadowRoot对象进行相对定位时,把它看作其父对象内部的第一个对象,其余定位逻辑与普通对象一致。
用元素对象的shadow_root属性可获取ShadowRoot对象。
- 如果
ShadowRoot元素的下级元素中有其它ShadowRoot元素,那这些下级ShadowRoot元素内部是无法直接通过定位语句查找到的,只能先定位到其父元素,再用shadow-root属性获取。
# 获取一个 shadow-root 元素 sr_ele = page.ele('#app').shadow_root # 在该元素下查找下级元素 ele1 = sr_ele.ele('tag:div') # 用相对定位获取其它元素 ele1 = sr_ele.parent(2) ele1 = sr_ele.next('tag:div', 1) ele1 = sr_ele.after('tag:div', 1) eles = sr_ele.nexts('tag:div') # 定位下级元素中的 shadow+-root 元素 sr_ele2 = sr_ele.ele('tag:div').shadow_root
由于 shadow-root 不能跨级查找,链式操作非常常见,所以设计了一个简写:sr,功能和shadow_root 一样,都是获取元素内部的ShadowRoot。
多级 shadow-root 链式操作示例:
- 以下这段代码,可以打印浏览器历史第一页,可见是通过多级 shadow-root 来获取的。
from DrissionPage import ChromiumPage page = ChromiumPage() page.get('chrome://history/') items = page('#history-app').sr('#history').sr.eles('t:history-item') for i in items: print(i.sr('#item-container').text.replace('\n', ''))
四、相对定位
4.1.基于 DOM 相对定位
以下方法可以以某元素为基准,在 DOM 中按照条件获取其直接子节点、同级节点、祖先元素、文档前后节点。这里说的是“节点”,不是“元素”。因为相对定位可以获取除元素外的其它节点,包括文本、注释节点。
4.1.1.获取父级元素
⑴.方法:parent()
- parent() 方法用于获取当前元素的某一级父元素,可以通过层级数或定位符筛选特定的父元素。
参数:
- level_or_loc:可为整数或字符串,指定获取第几级父元素,或通过定位符筛选祖先元素。
- index:当 level_or_loc 为定位符时,指定返回第几个匹配的祖先元素。
返回类型:
- ChromiumElement、SessionElement、NoneElement
# 获取 ele1 的第二层父元素 ele2 = ele1.parent(2) # 获取 ele1 父元素中 id 为 id1 的元素 ele2 = ele1.parent('#id1')
说明: 在这个例子中,ele1.parent(2) 会获取 ele1 的第二级父元素,即从 ele1 开始向上追溯两层的元素。而 ele1.parent('#id1') 则会获取 ele1 的祖先元素中 id 为 id1 的元素。
⑵.完整案例
通过百度搜索页面演示:
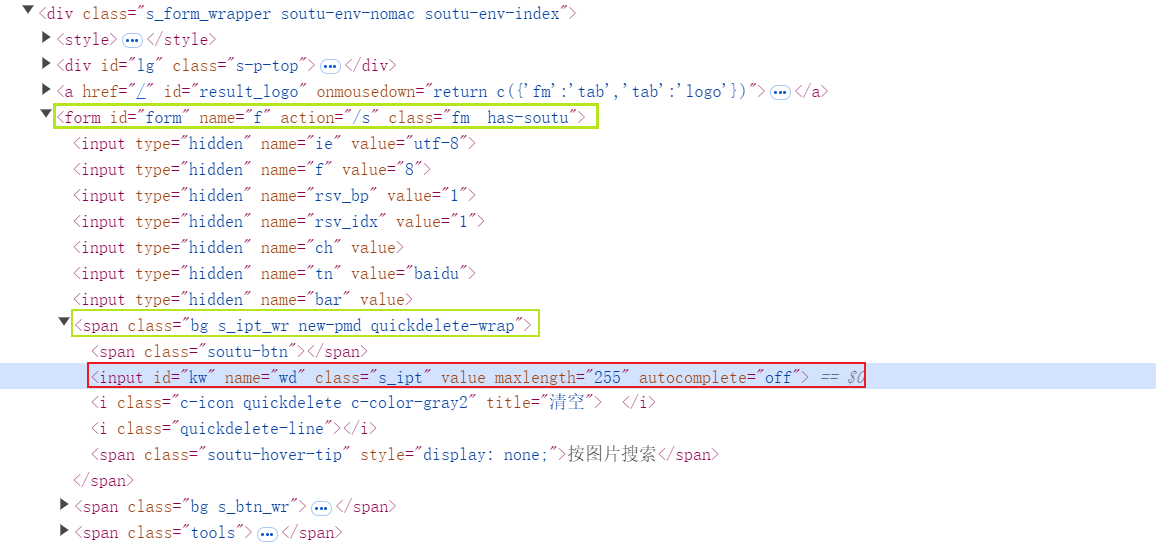
from DrissionPage import ChromiumPage # 初始化 ChromiumPage page = ChromiumPage() # 打开百度首页 page.get("https://www.baidu.com") # 定位搜索框 search_box = page.ele("#kw") # 获取 search_box 的父元素 parent_element = search_box.parent() print("获取 search_box 的父元素:", parent_element) # 获取search_box指定父级元素,例如 id=form 的父元素 parent_form = search_box.parent("@id=form") print("获取id=form的父元素:", parent_form)
输出如下:
获取 search_box 的父元素: <ChromiumElement span class='bg s_ipt_wr new-pmd iptfocus quickdelete-wrap'> 获取id=form的父元素: <ChromiumElement form id='form' name='f' action='/s' class='fm has-soutu'>
4.1.2.获取直接子节点
⑴.方法:child()
child() 方法返回当前元素的一个直接子节点,可以指定查询条件和第几个节点。
参数:
- locator:字符串或元组,指定筛选子节点的查询条件。
- index:整数,指定返回第几个匹配的子节点,可以为负数表示倒数第几个。
- ele_only:布尔值,指定是否只查找元素节点。
返回类型:
- str、ChromiumElement、SessionElement、NoneElement
# 获取 ele1 的第一个子元素 ele2 = ele1.child() # 获取 ele1 的第三个 div 子元素 ele2 = ele1.child('tag:div', 3)
说明: ele1.child() 获取的是 ele1 的第一个直接子元素,而 ele1.child('tag:div', 3) 则是获取第三个 div 类型的子元素。
⑵.方法:children()
children() 方法返回当前元素的所有符合条件的直接子节点组成的列表。
# 获取 ele1 的所有子元素 ele2 = ele1.children() # 获取 ele1 的所有 div 子元素 divs = ele1.children('tag:div')
说明: 这个方法可以一次性获取某个元素的所有符合条件的子元素。例如,ele1.children('tag:div') 会返回所有 div 类型的子元素。
⑶.完整案例
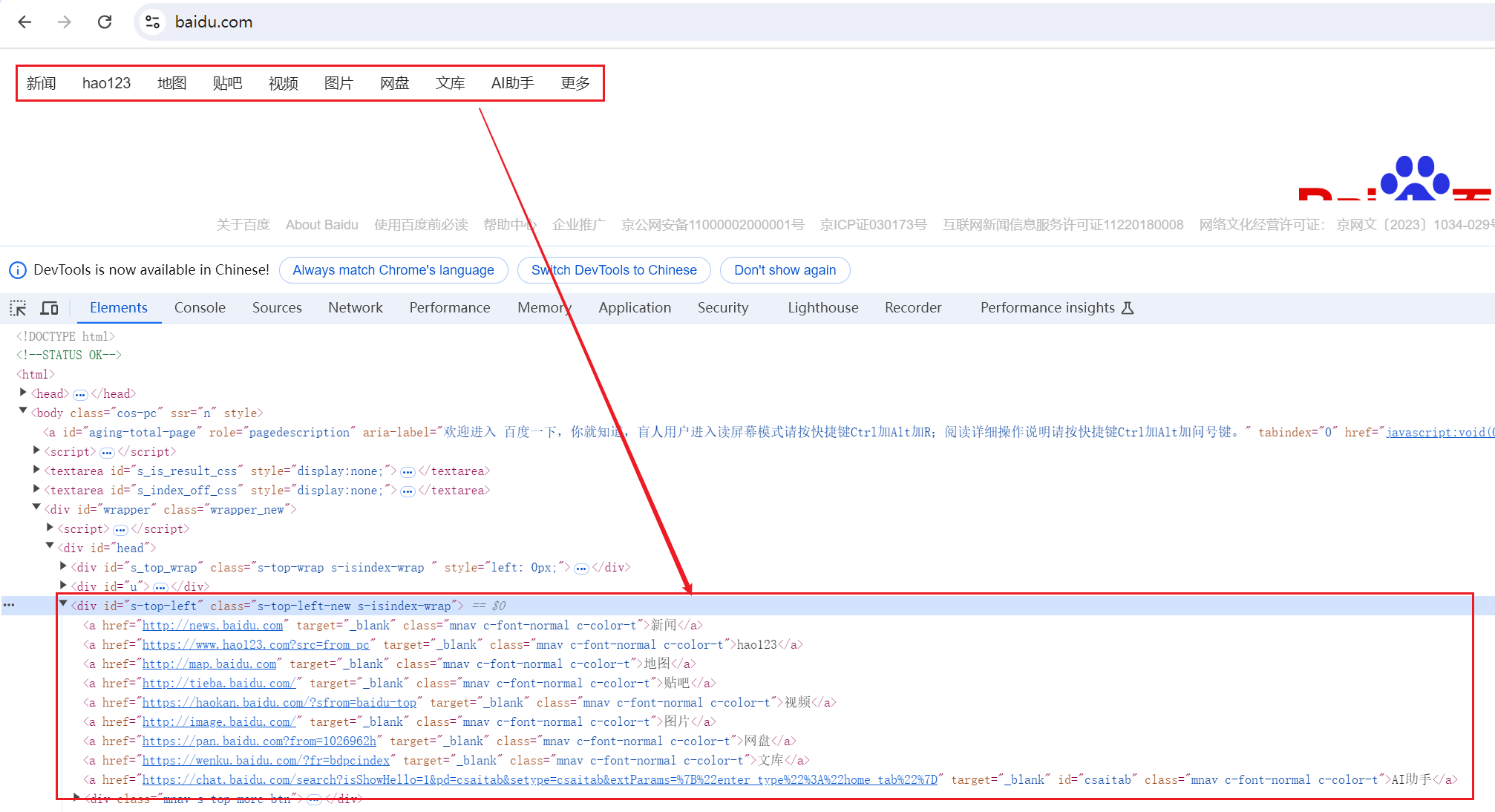
from DrissionPage import ChromiumPage # 初始化 ChromiumPage page = ChromiumPage() # 打开百度首页 page.get("https://www.baidu.com") # 定位百度搜索页面左上角超链接 hyperlink = page.ele("@id=s-top-left") # 获取第一个直接子节点 child_element = hyperlink.child() print("获取第一个直接子节点:", child_element) # 获取 hyperlink 的所有子元素 children_element = hyperlink.children() print("获取 hyperlink 的所有子元素:", children_element) # 获取 hyperlink 的所有 a 子元素 children_element_all_a = hyperlink.children("tag:a") print("获取 hyperlink 的所有 a 子元素", children_element_all_a)
输出如下:
获取第一个直接子节点: <ChromiumElement a href='http://news.baidu.com' target='_blank' class='mnav c-font-normal c-color-t'> 获取 hyperlink 的所有子元素: [<ChromiumElement a href='http://news.baidu.com' target='_blank' class='mnav c-font-normal c-color-t'>, <ChromiumElement a href='https://www.hao123.com?src=from_pc' target='_blank' class='mnav c-font-normal c-color-t'>, <ChromiumElement a href='http://map.baidu.com' target='_blank' class='mnav c-font-normal c-color-t'>, <ChromiumElement a href='http://tieba.baidu.com/' target='_blank' class='mnav c-font-normal c-color-t'>, <ChromiumElement a href='https://haokan.baidu.com/?sfrom=baidu-top' target='_blank' class='mnav c-font-normal c-color-t'>, <ChromiumElement a href='http://image.baidu.com/' target='_blank' class='mnav c-font-normal c-color-t'>, <ChromiumElement a href='https://pan.baidu.com?from=1026962h' target='_blank' class='mnav c-font-normal c-color-t'>, <ChromiumElement a href='https://wenku.baidu.com/?fr=bdpcindex' target='_blank' class='mnav c-font-normal c-color-t'>, <ChromiumElement a href='https://chat.baidu.com/search?isShowHello=1&pd=csaitab&setype=csaitab&extParams=%7B%22enter_type%22%3A%22home_tab%22%7D' target='_blank' id='csaitab' class='mnav c-font-normal c-color-t'>, <ChromiumElement div class='mnav s-top-more-btn'>] 获取 hyperlink 的所有 a 子元素 [<ChromiumElement a href='http://news.baidu.com' target='_blank' class='mnav c-font-normal c-color-t'>, <ChromiumElement a href='https://www.hao123.com?src=from_pc' target='_blank' class='mnav c-font-normal c-color-t'>, <ChromiumElement a href='http://map.baidu.com' target='_blank' class='mnav c-font-normal c-color-t'>, <ChromiumElement a href='http://tieba.baidu.com/' target='_blank' class='mnav c-font-normal c-color-t'>, <ChromiumElement a href='https://haokan.baidu.com/?sfrom=baidu-top' target='_blank' class='mnav c-font-normal c-color-t'>, <ChromiumElement a href='http://image.baidu.com/' target='_blank' class='mnav c-font-normal c-color-t'>, <ChromiumElement a href='https://pan.baidu.com?from=1026962h' target='_blank' class='mnav c-font-normal c-color-t'>, <ChromiumElement a href='https://wenku.baidu.com/?fr=bdpcindex' target='_blank' class='mnav c-font-normal c-color-t'>, <ChromiumElement a href='https://chat.baidu.com/search?isShowHello=1&pd=csaitab&setype=csaitab&extParams=%7B%22enter_type%22%3A%22home_tab%22%7D' target='_blank' id='csaitab' class='mnav c-font-normal c-color-t'>]
4.1.3.获取同级节点
⑴.方法:next()
next() 方法返回当前元素后面的某一个同级节点。
参数:
- locator:指定筛选条件
- index:指定第几个符合条件的同级节点
- ele_only:是否只查找元素节点
返回类型:
- str、ChromiumElement、SessionElement、NoneElement
# 获取 ele1 后面第一个兄弟元素 ele2 = ele1.next() # 获取 ele1 后面第 3 个 div 兄弟元素 ele2 = ele1.next('tag:div', 3)
说明: 通过 ele1.next() 可以获取到 ele1 后面的第一个兄弟元素,而 ele1.next('tag:div', 3) 则是获取第三个 div 类型的兄弟元素。
⑵.方法:prev()
prev() 方法与 next() 类似,但它返回的是当前元素前面的某一个同级节点。
# 获取 ele1 前面第一个兄弟元素 ele2 = ele1.prev() # 获取 ele1 前面第 3 个 div 兄弟元素 ele2 = ele1.prev(3, 'tag:div')
说明: prev() 用于查找元素前面的同级节点。这个例子中,ele1.prev(3, 'tag:div') 将会返回 ele1 前面第 3 个 div 类型的兄弟元素。
⑶.完整案例

代码如下:
from DrissionPage import ChromiumPage # 初始化 ChromiumPage page = ChromiumPage() # 打开百度首页 page.get("https://www.baidu.com") # 定位百度搜索页面左上角超链接 hyperlink = page.ele("@id=s-top-left") # 获取 hyperlink 后面第一个兄弟元素 ele1 = hyperlink.next() print("获取 hyperlink 后面第一个兄弟元素", ele1) # 获取 hyperlink 后面第 3 个 div 兄弟元素 ele2 = hyperlink.next("tag:div", 3) print("获取 hyperlink 后面第 3 个 div 兄弟元素", ele2) # 获取 hyperlink 前面第一个兄弟元素 ele3 = hyperlink.prev() print("获取 hyperlink 前面第一个兄弟元素", ele3) # 获取 hyperlink 前面第 2 个 div 兄弟元素 ele4 = hyperlink.prev('tag:div', 2) print("获取 hyperlink 前面第 2 个 div 兄弟元素", ele4)
输出如下:
获取 hyperlink 后面第一个兄弟元素 <ChromiumElement div id='u1' class='s-top-right s-isindex-wrap'> 获取 hyperlink 后面第 3 个 div 兄弟元素 <ChromiumElement div id='s_wrap' class='s-isindex-wrap'> 获取 hyperlink 前面第一个兄弟元素 <ChromiumElement div id='u'> 获取 hyperlink 前面第 2 个 div 兄弟元素 <ChromiumElement div id='s_top_wrap' class='s-top-wrap s-isindex-wrap '>
4.1.4.在文档中查找节点
⑴.方法:after()
after() 方法返回当前元素后面整个文档中的某一个节点,不限于同级。
# 获取 ele1 后面第 3 个元素 ele2 = ele1.after(index=3) # 获取 ele1 后面第 3 个 div 元素 ele2 = ele1.after('tag:div', 3)
说明: 这个方法适用于需要跨越多个节点查找的情况,例如 ele1.after('tag:div', 3) 查找到的可能是 ele1 后面的第三个 div 元素,无论其层级如何。
⑵.方法:before()
before() 方法与 after() 类似,但它返回的是当前元素前面整个文档中的某一个节点。
# 获取 ele1 前面第 3 个元素 ele2 = ele1.before(3) # 获取 ele1 前面第 3 个 div 元素 ele2 = ele1.before('tag:div', 3)
说明: 同样地,before() 方法用于查找文档中当前元素之前的节点,示例中的 ele1.before('tag:div', 3) 将会返回 ele1 前面第 3 个 div 元素。
⑶.完整案例
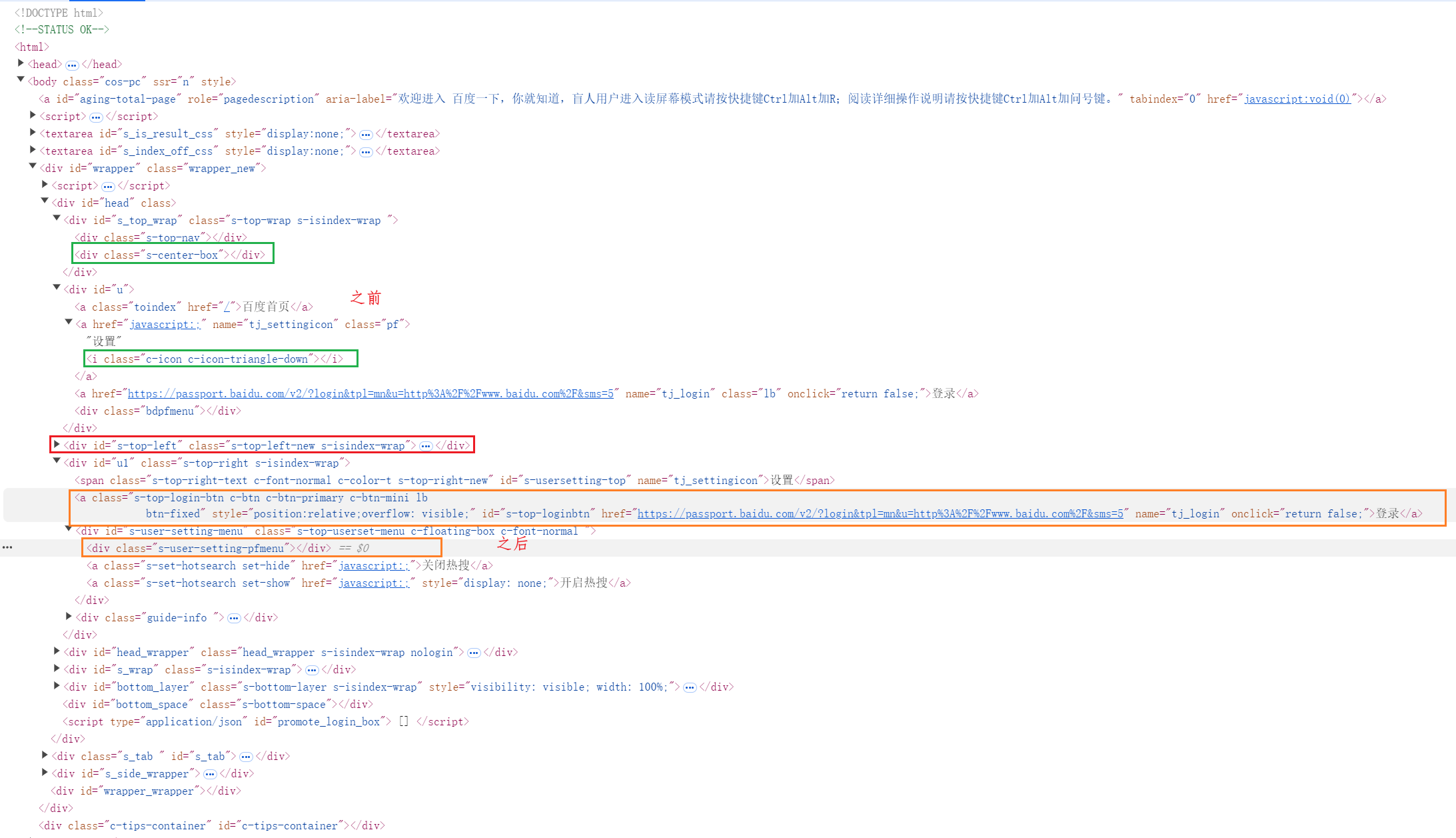
完整代码如下:
from DrissionPage import ChromiumPage # 初始化 ChromiumPage page = ChromiumPage() # 打开百度首页 page.get("https://www.baidu.com") # 定位百度搜索页面左上角超链接 hyperlink = page.ele("@id=s-top-left") # 获取 hyperlink 后面第 3 个元素 ele1 = hyperlink.after(index=3) print("获取 hyperlink 后面第 3 个元素", ele1) # 获取 hyperlink 后面第 3 个 div 元素 ele2 = hyperlink.after('tag:div', 3) print("获取 hyperlink 后面第 3 个 div 元素", ele2) # 获取 hyperlink 前面第 3 个元素 ele3 = hyperlink.before(3) print("获取 hyperlink 前面第 3 个元素", ele3) # 获取 hyperlink 前面第 3 个 div 元素 ele4 = hyperlink.before('tag:div', 3) print("获取 hyperlink 前面第 3 个 div 元素", ele4)
输出如下:
获取 hyperlink 后面第 3 个元素 <ChromiumElement a class='s-top-login-btn c-btn c-btn-primary c-btn-mini lb btn-fixed' style='position:relative;overflow: visible;' id='s-top-loginbtn' href='https://passport.baidu.com/v2/?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2F&sms=5' name='tj_login' onclick='return false;'> 获取 hyperlink 后面第 3 个 div 元素 <ChromiumElement div class='s-user-setting-pfmenu'> 获取 hyperlink 前面第 3 个元素 <ChromiumElement i class='c-icon c-icon-triangle-down'> 获取 hyperlink 前面第 3 个 div 元素 <ChromiumElement div class='s-center-box'>
4.2.基于视觉相对定位
下面方法可以以某元素为基准,向不同方向或指定偏移量获取元素。只有浏览器模式支持这类定位方式。只能获取可见的元素(不论是否在视口内),不能获取被遮挡的
4.2.1. east()
用于获取一个在当前元素右边的元素。
- 可以通过
loc_or_pixel参数指定定位符或距离(像素),并可通过index参数指定获取第几个元素。 loc_or_pixel参数可用定位符指定筛选条件,定位符只支持str格式,且不支持 xpath 和 css 方式。- 用
index参数可指定获取第几个结果。如果loc_or_pixel为None,获取第若干个元素。 loc_or_pixel为int格式时,直接获取元素右边这个距离的元素,此时index参数无效。距离从右边框开始计算。
参数:
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
loc_or_pixel |
strint |
None |
定位符或距离(像素) |
index |
int |
1 |
第几个,从1开始,loc_or_pixel为int格式时无效 |
返回值:
| 返回类型 | 说明 |
|---|---|
ChromiumElement |
找到的元素对象 |
NoneElement |
未获取到结果时 |
from DrissionPage import ChromiumPage # 初始化 ChromiumPage page = ChromiumPage() # 打开百度首页 page.get("https://www.baidu.com") # 定位百度搜索框 search_box = page.ele('#kw') print(search_box) # 获取 search_box 右边的第一个元素 ele1 = search_box.east() print("获取search_box 右边的第一个元素:", ele1) # 获取 search_box 右边距离 200 像素的元素 ele2 = search_box.east(200) print("获取 search_box 右边距离 200 像素的元素:", ele2)
输出如下:
<ChromiumElement input id='kw' name='wd' class='s_ipt' value='' maxlength='255' autocomplete='off'> 获取search_box 右边的第一个元素: <ChromiumElement input type='submit' id='su' value='百度一下' class='bg s_btn'> 获取 search_box 右边距离 200 像素的元素: <ChromiumElement div id='head_wrapper' class='head_wrapper s-isindex-wrap nologin'>
4.2.2.west()
用于获取一个在当前元素左边的元素。可以通过 loc_or_pixel 参数指定定位符或距离(像素),并可通过 index 参数指定获取第几个元素。
loc_or_pixel参数可用定位符指定筛选条件,定位符只支持str格式,且不支持 xpath 和 css 方式。- 用
index参数可指定获取第几个结果。如果loc_or_pixel为None,获取第若干个元素。 loc_or_pixel为int格式时,直接获取元素下边这个距离的元素,此时index参数无效。距离从下边框开始计算。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
loc_or_pixel |
strint |
None |
定位符或距离(像素) |
index |
int |
1 |
第几个,从1开始,loc_or_pixel为int格式时无效 |
| 返回类型 | 说明 |
|---|---|
ChromiumElement |
找到的元素对象 |
NoneElement |
未获取到结果时 |
from DrissionPage import ChromiumPage # 初始化 ChromiumPage page = ChromiumPage() # 打开百度首页 page.get("https://www.baidu.com") # 定位“百度搜索框” ele1 = page.ele('#kw') print(ele1) # 获取 button 右边的第一个元素 ele1 = ele.west() print("获取 ele1 左边的第一个元素:", ele1) # 获取 button 左边距离 200 像素的元素 ele2 = ele.west(200) print("获取 ele1 左边距离 200 像素的元素:", ele2)
输出:
<ChromiumElement input id='kw' name='wd' class='s_ipt' value='' maxlength='255' autocomplete='off'> 获取 ele1 左边的第一个元素: <ChromiumElement div id='head_wrapper' class='head_wrapper s-isindex-wrap nologin'> 获取 ele1 左边距离 200 像素的元素: <ChromiumElement div id='head_wrapper' class='head_wrapper s-isindex-wrap nologin'>
4.2.3. south()
用于获取一个在当前元素下边的元素。可以通过 loc_or_pixel 参数指定定位符或距离(像素),并可通过 index 参数指定获取第几个元素。
loc_or_pixel参数可用定位符指定筛选条件,定位符只支持str格式,且不支持 xpath 和 css 方式。- 用
index参数可指定获取第几个结果。如果loc_or_pixel为None,获取第若干个元素。 loc_or_pixel为int格式时,直接获取元素上边这个距离的元素,此时index参数无效。距离从上边框开始计算
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
loc_or_pixel |
strint |
None |
定位符或距离(像素) |
index |
int |
1 |
第几个,从1开始,loc_or_pixel为int格式时无效 |
| 返回类型 | 说明 |
|---|---|
ChromiumElement |
找到的元素对象 |
NoneElement |
未获取到结果时 |
# 初始化 ChromiumPage page = ChromiumPage() # 打开百度首页 page.get("https://www.baidu.com") # 定位百度搜索页面左上角超链接 hyperlink = page.ele("@id=s-top-left") # 获取 hyperlink 下边的第一个元素 ele1 = hyperlink.south() print("获取 ele1 下边的第一个元素:", ele1) # 获取 hyperlink 下边距离 200 像素的元素 ele2 = hyperlink.south(200) print("获取 ele1 下边距离 200 像素的元素:", ele2)
输出
获取 hyperlink 下边的第一个元素: <ChromiumElement div id='head_wrapper' class='head_wrapper s-isindex-wrap nologin'> 获取 hyperlink 下边距离 200 像素的元素: <ChromiumElement a class='text-color' href='http://ir.baidu.com' target='_blank'>
4.2.4. north()
用于获取一个在当前元素上边的元素。可以通过 loc_or_pixel 参数指定定位符或距离(像素),并可通过 index 参数指定获取第几个元素。
loc_or_pixel参数可用定位符指定筛选条件,定位符只支持str格式,且不支持 xpath 和 css 方式。- 用
index参数可指定获取第几个结果。如果loc_or_pixel为None,获取第若干个元素。 loc_or_pixel为int格式时,直接获取元素上边这个距离的元素,此时index参数无效。距离从上边框开始计算。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
loc_or_pixel |
strint |
None |
定位符或距离(像素) |
index |
int |
1 |
第几个,从1开始,loc_or_pixel为int格式时无效 |
| 返回类型 | 说明 |
|---|---|
ChromiumElement |
找到的元素对象 |
NoneElement |
未获取到结果时 |
from DrissionPage import ChromiumPage # 初始化 ChromiumPage page = ChromiumPage() # 打开百度首页 page.get("https://www.baidu.com") # 定位百度搜索框 search_box = page.ele('#kw') print(search_box) # 获取 search_box 上边的第一个元素 ele1 = search_box.north() print("获取 search_box 上边的第一个元素:", ele1) # 获取 search_box 上边距离 150 像素的元素 ele2 = search_box.north(150) print("获取 search_box 上边距离 150 像素的元素:", ele2)
如果不存在,则显示None,输出如下:
<ChromiumElement input id='kw' name='wd' class='s_ipt' value='' maxlength='255' autocomplete='off'> 获取 search_box 上边的第一个元素: <ChromiumElement div id='lg' class='s-p-top'> 获取 search_box 上边距离 150 像素的元素: None
4.2.5.offset()
用于获取相对于当前元素左上角指定偏移量的一个元素。offset_x 和 offset_y 分别表示横坐标和纵坐标的偏移量。
参数:
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
offset_x |
int |
必填 | 横坐标偏移量(像素),向右为正 |
offset_y |
int |
必填 | 纵坐标偏移量(像素),向下为正 |
| 返回类型 | 说明 |
|---|---|
ChromiumElement |
找到的元素对象 |
NoneElement |
未获取到结果时 |
示例:假设你要获取相对于搜索结果标题左上角偏移 50 像素向右和 100 像素向下的元素:
# 假设 ele1 是当前的搜索结果标题元素 ele1 = driver.find_element_by_id('result-title') # 获取相对于 ele1 左上角偏移 50 像素向右和 100 像素向下的元素 offset_element = ele1.offset(50, 100)
4.2.6. over()
用于获取覆盖在当前元素上最上层的元素。可以通过 timeout 参数设置等待元素出现的超时时间。
参数:
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
timeout |
float |
None |
等待元素出现的超时时间(秒),为None使用页面timeout设置值 |
返回值:
| 返回类型 | 说明 |
|---|---|
ChromiumElement |
找到的元素对象 |
NoneElement |
未获取到结果时 |
示例:假设你要获取覆盖在搜索结果标题上最上层的元素:
# 假设 ele1 是当前的搜索结果标题元素 ele1 = driver.find_element_by_id('result-title') # 获取覆盖在 ele1 上的最上层元素,等待最多 5 秒 top_element = ele1.over(timeout=5)
五、行为模式
5.1.等待元素
5.1.1.内置等待
内置等待是指在查找元素时自动等待元素加载到DOM中,等待时间可以根据需要设置。
作用:
- 通过内置等待机制,自动延迟操作,直至元素加载完成,从而减少因元素尚未加载而导致的错误或异常。
- 内置等待的默认时间与页面的超时时间一致,但可以在每次查找时单独设置等待时间,以适应不同的需求。
用法:
from DrissionPage import ChromiumPage # 页面初始化时设置查找元素超时时间为 15 秒 page = ChromiumPage(timeout=15) page.get("https://www.baidu.com") # 设置查找元素超时时间为 5 秒 page.set.timeouts(5) # 使用页面超时时间(5 秒)查找元素 ele1 = page.ele("#kw") ele1.input("演唱会") # 为这次查找页面独立设置等待时间(1 秒) page.ele("#su", timeout=1).click()
5.1.2.主动等待
页面对象的wait.eles_loaded()方法,可主动等待指定元素加载到 DOM。
from DrissionPage import ChromiumPage page = ChromiumPage() # 打开页面 page.get("https://www.baidu.com") # 等待指定的元素加载完成, 返回的是true或者false outcome = page.wait.eles_loaded("#kw", 15) print(outcome)
5.2.链式写法
因为元素对象本身又可以查找对象,所有可实现多级链式操作,可使程序更简洁。
ele = tab.ele('#s_fm').ele('#su')
其中ele()可省略,简化写成:
ele = tab('#s_fm')('#su')
from DrissionPage import ChromiumPage page = ChromiumPage() # 打开页面 page.get("https://www.baidu.com") # 使用链式写法找到百度搜索页面左上角,点击调转到新闻页面 page('@id=s-top-left')('@href=http://news.baidu.com').click()
5.3.找不到元素时
5.3.1.默认情况
默认情况下,找不到元素时不会立即抛出异常,而是返回一个NoneElement对象。这个对象用if判断表现为False,调用其功能会抛出ElementNotFoundError异常。
这样可以用if判断是否找到元素,也可以用try去捕获异常。查找多个元素找不到时,返回空的list。
from DrissionPage import ChromiumPage from DrissionPage.errors import ElementNotFoundError page = ChromiumPage() # 打开页面 page.get("https://www.baidu.com") # 定位不存在的元素 ele = page.ele("#ki") # 异常捕获 try: ele.click() except ElementNotFoundError as e: print("元素没有找到:", e)
输出如下:
元素没有找到: 没有找到元素。 method: ele() args: {'locator': '#ki', 'index': 1}
5.3.2.立即抛出异常
如果想在找不到元素时立刻抛出异常,可以用以下方法设置。此设置为全局有效,在项目开始时设置一次即可。查找多个元素找不到时,依然返回空的list。
设置全局变量:如果需要在找不到元素时立即抛出异常,可以在项目开始时设置全局变量:
from DrissionPage.common import Settings Settings.raise_when_ele_not_found = True
示例:设置全局变量后,即可立即抛出异常,
from DrissionPage import ChromiumPage from DrissionPage.common import Settings Settings.raise_when_ele_not_found = True page = ChromiumPage(timeout=1) page.get('https://www.baidu.com') ele = page('#abcd') # 这个元素不存在
抛出异常如下:
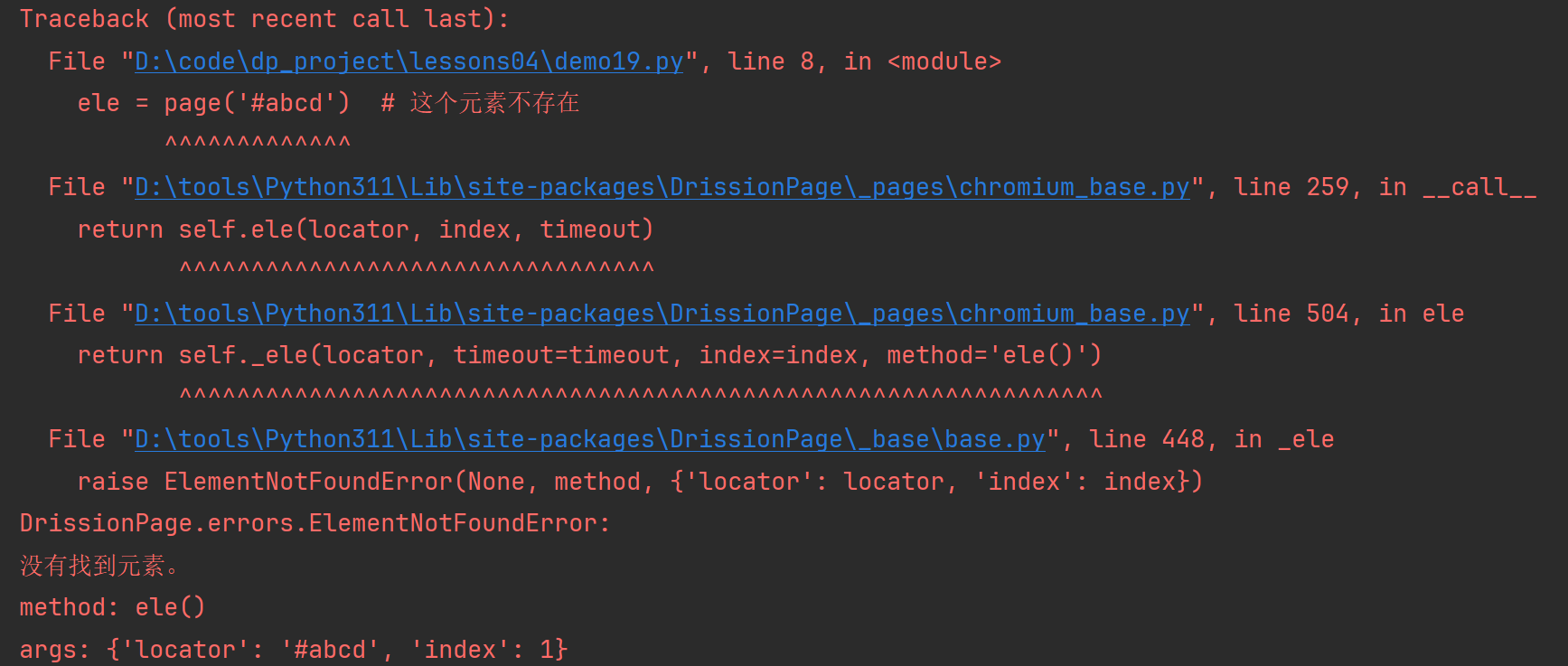
5.3.3.设置默认返回值
设置默认返回值:如果不希望在元素找不到时抛出异常,可以设置一个默认返回值,我这里是官方案例自己编写案例均是有问题存在bug
示例:比如说,遍历页面上一个列表中多个对象,但其中有些元素可能缺失某个子元素,可以这样写:
from DrissionPage import ChromiumPage page = ChromiumPage() page.set.NoneElement_value('没找到') for li in page.eles('t:li'): name = li('.name').text age = li('.age').text phone = li('.phone').text
假如某个子元素不存在,不会抛出异常,而是返回'没找到'这个字符串。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号