DrissionPage
一、概述
DrissionPage 是一个基于 python 的网页自动化工具。它既能控制浏览器,也能收发数据包,还能把两者合而为一。可兼顾浏览器自动化的便利性和 requests 的高效率。它功能强大,内置无数人性化设计和便捷功能。它的语法简洁而优雅,代码量少,对新手友好。
二、主要功能
集成 Selenium 和 Requests-HTML:
- Selenium:用于浏览器自动化,可以模拟用户与网页的交互,如点击按钮、填写表单等,适合处理动态加载内容的网页。
- Requests-HTML:用于快速解析和提取静态 HTML 内容,适合处理不需要用户交互的网页,速度更快且资源消耗更少。
简化代码:
- DrissionPage 提供了更为简洁和直观的 API,使得编写自动化脚本和数据抓取脚本变得更加容易,减少了重复性代码。
自动切换模式:
- 用户可以在 Selenium 模式和 Requests-HTML 模式之间无缝切换,根据任务的需求选择合适的工具,提高效率。
三、主要作用
网页自动化测试:
- 使用 Selenium 的功能,DrissionPage 可以用于编写自动化测试脚本,模拟用户操作,进行功能测试和回归测试。
数据抓取:
- 利用 Requests-HTML 的功能,快速提取网页中的数据,比如获取商品价格、新闻标题等。
动态内容处理:
- 对于那些需要动态加载内容的网页,可以使用 Selenium 模式来确保所有内容都加载完毕,然后再进行数据提取。
提升效率:
- 通过结合两种模式,用户可以根据任务需要选择最佳的工具,大大提高了网页操作和数据抓取的效率。
四、基本使用
4.1.安装
参考文档:https://drissionpage.cn/get_start/installation,请使用 pip 安装 DrissionPage:
pip install DrissionPage
4.2.导入
4.2.1.页面类
页面类是最主要的工具,用于控制浏览器或收发数据包。DrissionPage 包含三种主要页面类。根据需要在其中选择使用。
⑴.ChromiumPage
如果只要控制浏览器,导入ChromiumPage。
from DrissionPage import ChromiumPage
⑵.SessionPage
如果只要收发数据包,导入SessionPage
from DrissionPage import SessionPage
⑶. WebPage
WebPage是功能最全面的页面类,既可控制浏览器,也可收发数据包。
from DrissionPage import WebPage
4.2.2.配置工具
⑴.ChromiumOptions
ChromiumOptions类用于设置浏览器启动参数。
这些参数只有在启动浏览器时有用,接管已存在的浏览器时是不生效的。
from DrissionPage import ChromiumOptions
⑵.SessionOptions
SessionOptions类用于设置Session对象启动参数。
用于配置SessionPage或WebPages 模式的连接参数。
from DrissionPage import SessionOptions
⑶.Settings
Settings用于设置全局运行配置,如找不到元素时是否抛出异常等。
from DrissionPage.common import Settings
4.2.3.其它工具
其它可能用到的工具,放在DrissionPage.common路径。
⑴.Keys
键盘按键类,用于键入 ctrl、alt 等按键。
from DrissionPage.common import Keys
⑵.Actions
动作链,用于执行一系列动作。在浏览器页面对象中已有内置,无如特殊需要无需主动导入。
from DrissionPage.common import Actions
⑶.By
与 selenium 一致的By类,便于项目迁移。
from DrissionPage.common import By
⑷.其它工具
wait_until:可等待传入的方法结果为真make_session_ele:从 html 文本生成ChromiumElement对象configs_to_here:把配置文件复制到当前路径get_blob:获取指定的 blob 资源tree:用于打印页面对象或元素对象结构from_selenium:用于对接 selenium 代码from_playwright:用于对接 playwright 代码
from DrissionPage.common import wait_until from DrissionPage.common import make_session_ele from DrissionPage.common import configs_to_here
4.2.4.异常
异常放在DrissionPage.errors路径。全部异常详见进阶使用章节。
from DrissionPage.errors import ElementNotFoundError
4.2.5.衍生对象类型
Tab、Element 等对象是由 Page 对象生成,开发过程中需要类型判断时需要导入这些类型。可在DrissionPage.items路径导入。
from DrissionPage.items import SessionElement from DrissionPage.items import ChromiumElement from DrissionPage.items import ShadowRoot from DrissionPage.items import NoneElement from DrissionPage.items import ChromiumTab from DrissionPage.items import MixTab from DrissionPage.items import ChromiumFrame
4.3.准备工作
如果只使用收发数据包功能,无需任何准备工作。如果要控制浏览器,则需设置浏览器路径。程序默认设置控制 Chrome,所以下面用 Chrome 演示。如果要使用 Edge 或其它 Chromium 内核浏览器,设置方法是一样的。
- 作者发现 92 版的 Chrome 存在一些奇怪的问题,导致有些电脑环境下不能启动,请尽量避免使用
4.3.1.执行步骤
⑴.尝试启动浏览器
默认状态下,程序会自动在系统内查找 Chrome 路径。执行以下代码,浏览器启动并且访问了项目文档,说明可直接使用,跳过后面的步骤即可。
from DrissionPage import ChromiumPage page = ChromiumPage() page.get('http://DrissionPage.cn')
⑵.设置路径
如果上面的步骤提示出错,说明程序没在系统里找到 Chrome 浏览器。可用以下其中一种方法设置,设置会持久化记录到默认配置文件,之后程序会使用该设置启动。
- 这里的浏览器路径不一定是 Chrome,Edge 等 Chromium 内核的浏览器都可以。
- 打开浏览器,在地址栏输入
chrome://version(Edge 输入edge://version),回车。
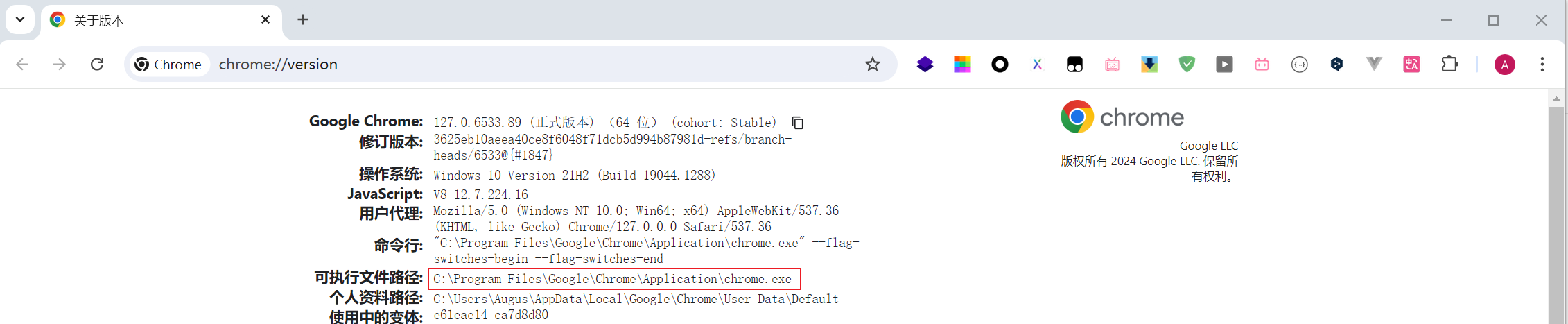
方法一:新建一个临时 py 文件,并输入以下代码,填入您电脑里的 Chrome 浏览器可执行文件路径,然后运行。
from DrissionPage import ChromiumOptions path = r'D:\Chrome\Chrome.exe' # 请改为你电脑内Chrome可执行文件路径 ChromiumOptions().set_browser_path(path).save()
这段代码会把浏览器路径记录到配置文件,今后启动浏览器皆以新路径为准。
另外,如果是想临时切换浏览器路径以尝试运行和操作是否正常,可以去掉 .save(),以如下方式结合第1️⃣步的代码。
from DrissionPage import ChromiumPage, ChromiumOptions path = r'D:\Chrome\Chrome.exe' # 请改为你电脑内Chrome可执行文件路径 co = ChromiumOptions().set_browser_path(path) page = ChromiumPage(co) page.get('http://DrissionPage.cn')
方法二:在命令行输入以下命令(路径改成自己电脑里的):
dp -p D:\Chrome\chrome.exe
- 注意命令行的 python 环境与项目应是同一个
- 注意要先使用 cd 命令定位到项目路径
五、基础案例
5.1.操控浏览器
演示使用ChromiumPage控制浏览器登录 gitee 网站。
页面分析
网址:https://gitee.com/login,打开网址,按F12,我们可以看到页面 html 如下:
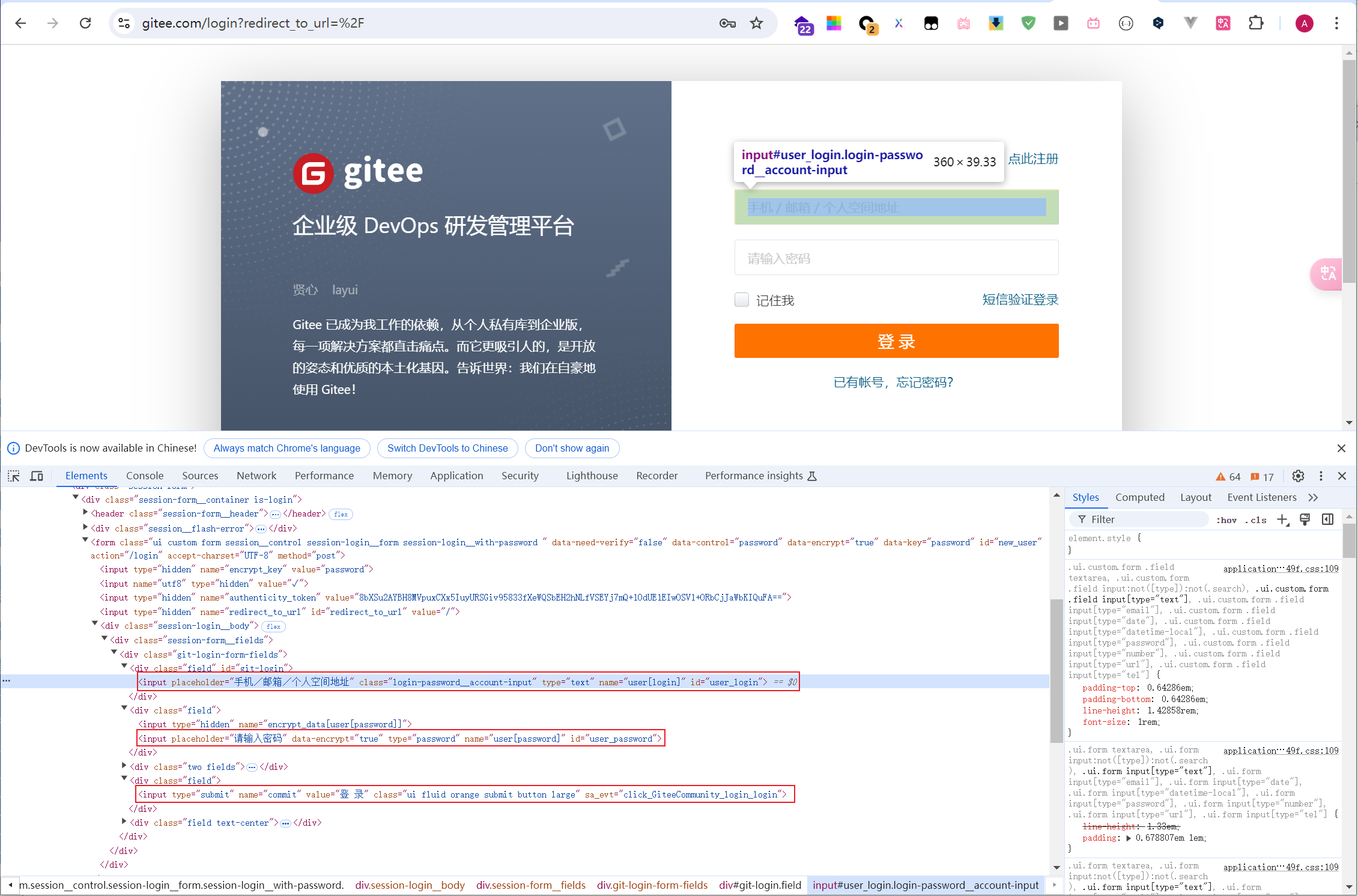
用户名输入框id为'user_login',密码输入框id为'user_password',登录按钮value为'登 录'。我们可以用这三个属性定位这三个元素,然后对其输入数据和点击。
示例代码
把账号和密码改为自己的,可直接执行看到运行结果。
from DrissionPage import ChromiumPage # 创建页面对象,并启动或接管浏览器 page = ChromiumPage() # 跳转到登录页面 page.get('https://gitee.com/login') # 定位到账号文本框,获取文本框元素 ele = page.ele('#user_login') # 输入对文本框输入账号 ele.input('您的账号') # 定位到密码文本框并输入密码 page.ele('#user_password').input('您的密码') # 点击登录按钮 page.ele('@value=登 录').click()
示例详解
我们逐行解读代码:
from DrissionPage import ChromiumPage
首先,我们导入用于控制浏览器的类ChromiumPage。
page = ChromiumPage()
接下来,我们创建一个ChromiumPage对象。
page.get('https://gitee.com/login')
get()方法用于访问参数中的网址。它会等待页面完全加载,再继续执行后面的代码。您也可以修改等待策略,如等待 DOM 加载而不等待资源下载,就停止加载,这将在后面的章节说明。
ele = page.ele('#user_login')
ele()方法用于查找元素,它返回一个ChromiumElement对象,用于操作元素。'#user_login'是定位符文本,#意思是按id属性查找元素。ele()内置了等待,如果元素未加载,它会执行等待,直到元素出现或到达时限。默认超时时间 10 秒。
ele.input('您的账号')
input()方法用于对元素输入文本。
page.ele('#user_password').input('您的密码')
我们也可以进行链式操作,获取元素后直接输入文本。
page.ele('@value=登 录').click()
输入账号密码后,以相同的方法获取按钮元素,并对其执行点击操作。不同的是,这次通过其value属性作为查找条件。@表示按属性名查找。到这里,我们已完成了自动登录 gitee 网站的操作。
5.2.收发数据包
演示用SessionPage已收发数据包的方式采集 gitee 网站数据。示例不使用浏览器。
页面分析
网址:https://gitee.com/explore/all,这个示例的目标,要获取所有库的名称和链接,为避免对网站造成压力,我们只采集 5 页。打开网址,按F12,我们可以看到页面 html 如下:
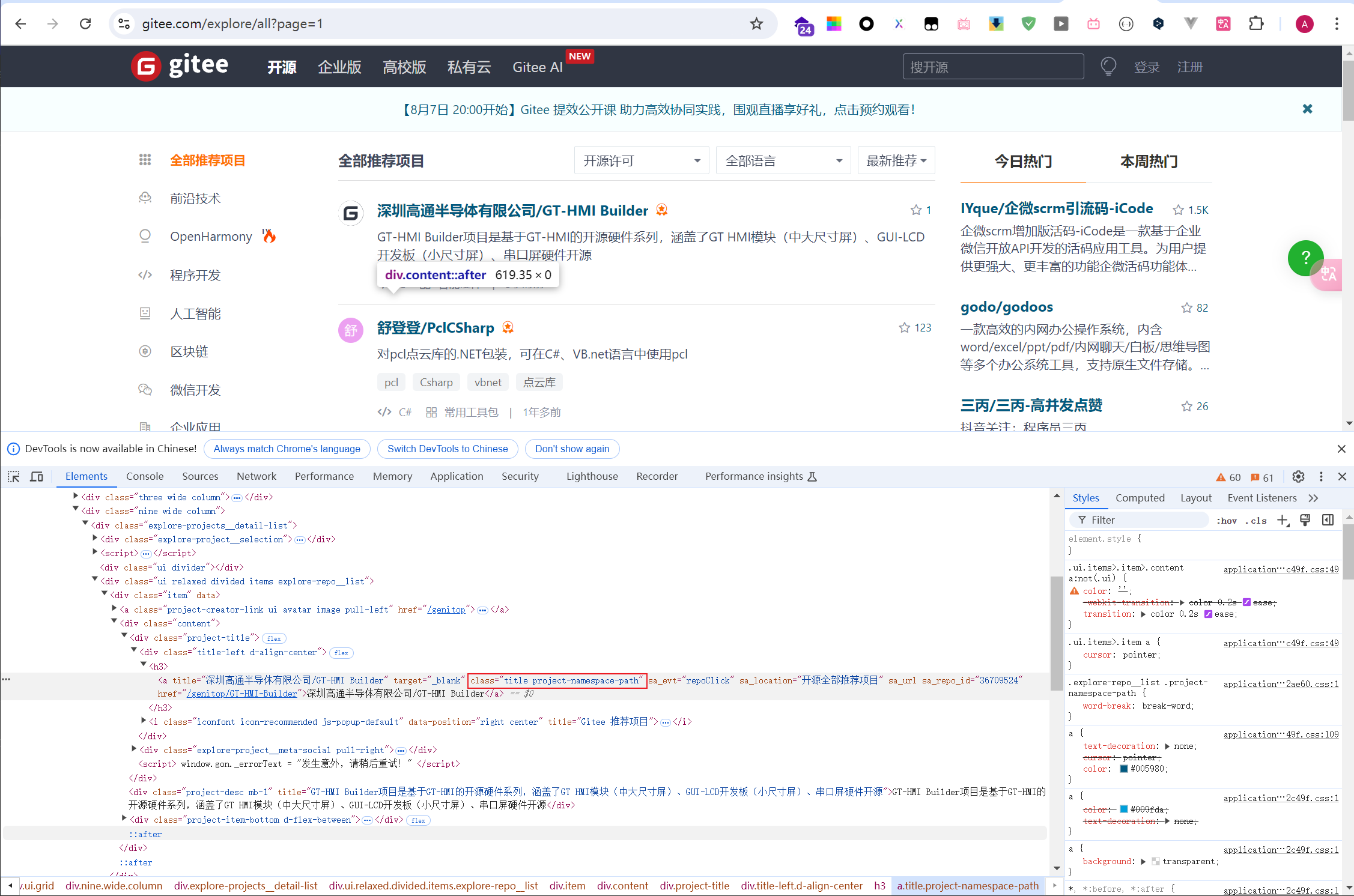
完整代码:
from DrissionPage import SessionPage # 创建页面对象 page = SessionPage() # 爬取3页 for i in range(1, 4): # 访问某一页的网页 page.get(f'https://gitee.com/explore/all?page={i}') # 获取所有开源库<a>元素列表 links = page.eles('.title project-namespace-path') # 遍历所有<a>元素 for link in links: # 打印链接信息 print(link.text, link.link)
输出如下:
深圳高通半导体有限公司/GT-HMI Builder https://gitee.com/genitop/GT-HMI-Builder 舒登登/PclCSharp https://gitee.com/shudengdeng/pcl-csharp Ascend/cann-hccl https://gitee.com/ascend/cann-hccl Cambricon/mlu-ops https://gitee.com/cambricon/mlu-ops Cambricon/cnindex https://gitee.com/cambricon/cnindex
示例详解
我们逐行解读代码:
from DrissionPage import SessionPage
首先,我们导入用于收发数据包的页面类SessionPage。
page = SessionPage()
接下来,我们创建一个SessionPage对象。
for i in ranage(1, 4): page.get(f'https://gitee.com/explore/all?page={i}')
然后我们循环 3 次,以构造每页的 url,每次都用get()方法访问该页网址。
links = page.eles('.title project-namespace-path')
访问网址后,我们用页面对象的eles()获取页面中所有class属性为'title project-namespace-path'的元素对象。eles()方法用于查找多个符合条件的元素,返回由它们组成的list。这里查找的条件是class属性,.表示按class属性查找元素。
for link in links: print(link.text, link.link)
最后,我们遍历获取到的元素列表,获取每个元素的属性并打印出来。.text获取元素的文本,.link获取元素的href或src属性。
5.3.模式切换
演示WebPage如何切换控制浏览器和收发数据包两种模式。
切换模式是用来应付登录检查很严格的网站,可以用浏览器处理登录,再转换模式用收发数据包的形式来采集数据。但是这种场景需要有对应的账号,不便于演示。演示使用浏览器在 gitee 搜索,然后转换到收发数据包的模式来读取数据。虽然此示例现实使用意义不大,但可以了解其工作模式。
页面分析
网址:https://gitee.com/explore,打开网址,按F12,我们可以看到页面 html 如下:
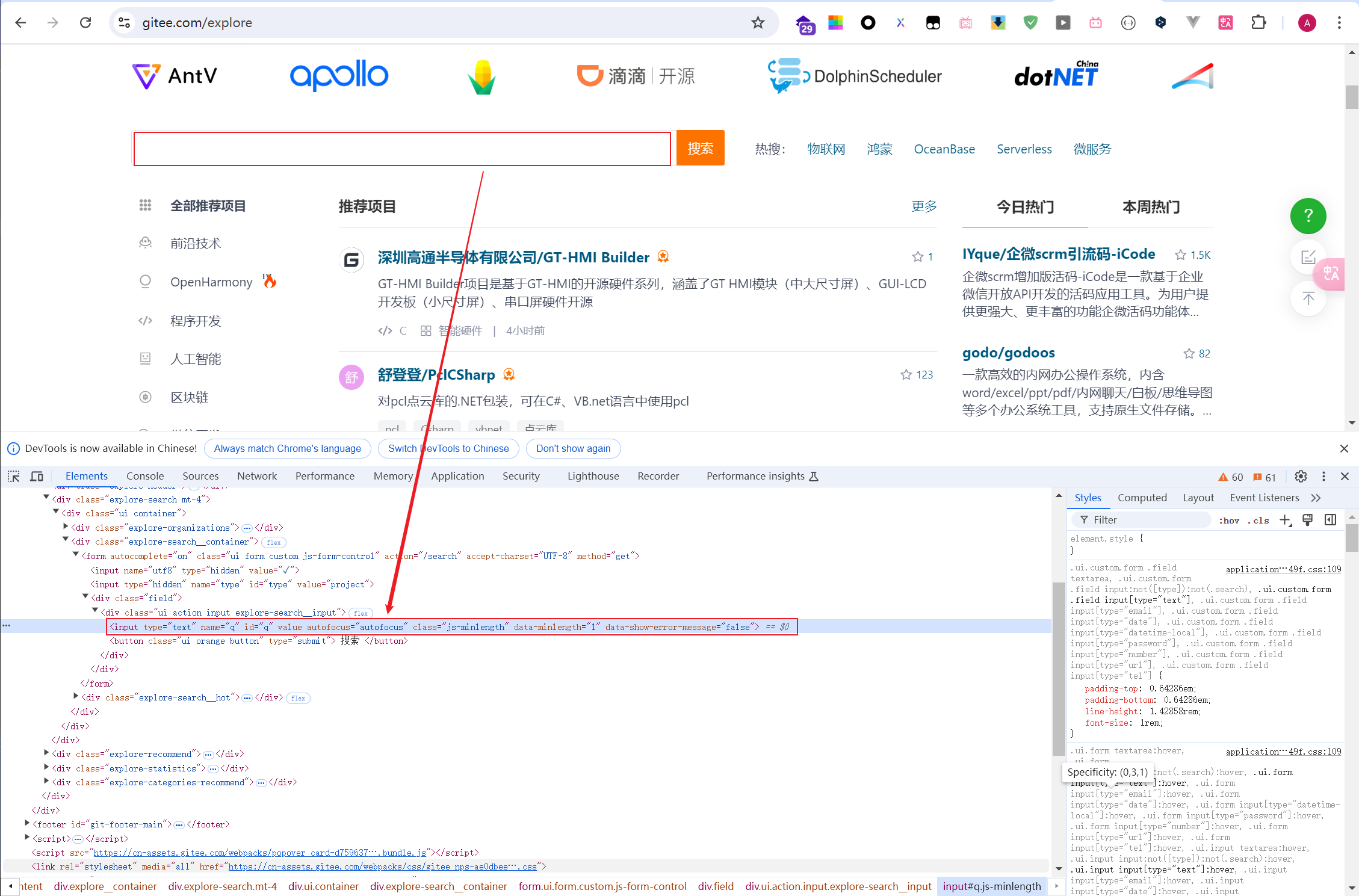
输入框<input>元素id属性为'q',搜索按钮<button>元素文本包含'搜索'文本,可用来作条件查找元素。
输入关键词搜索后,再查看页面 html:
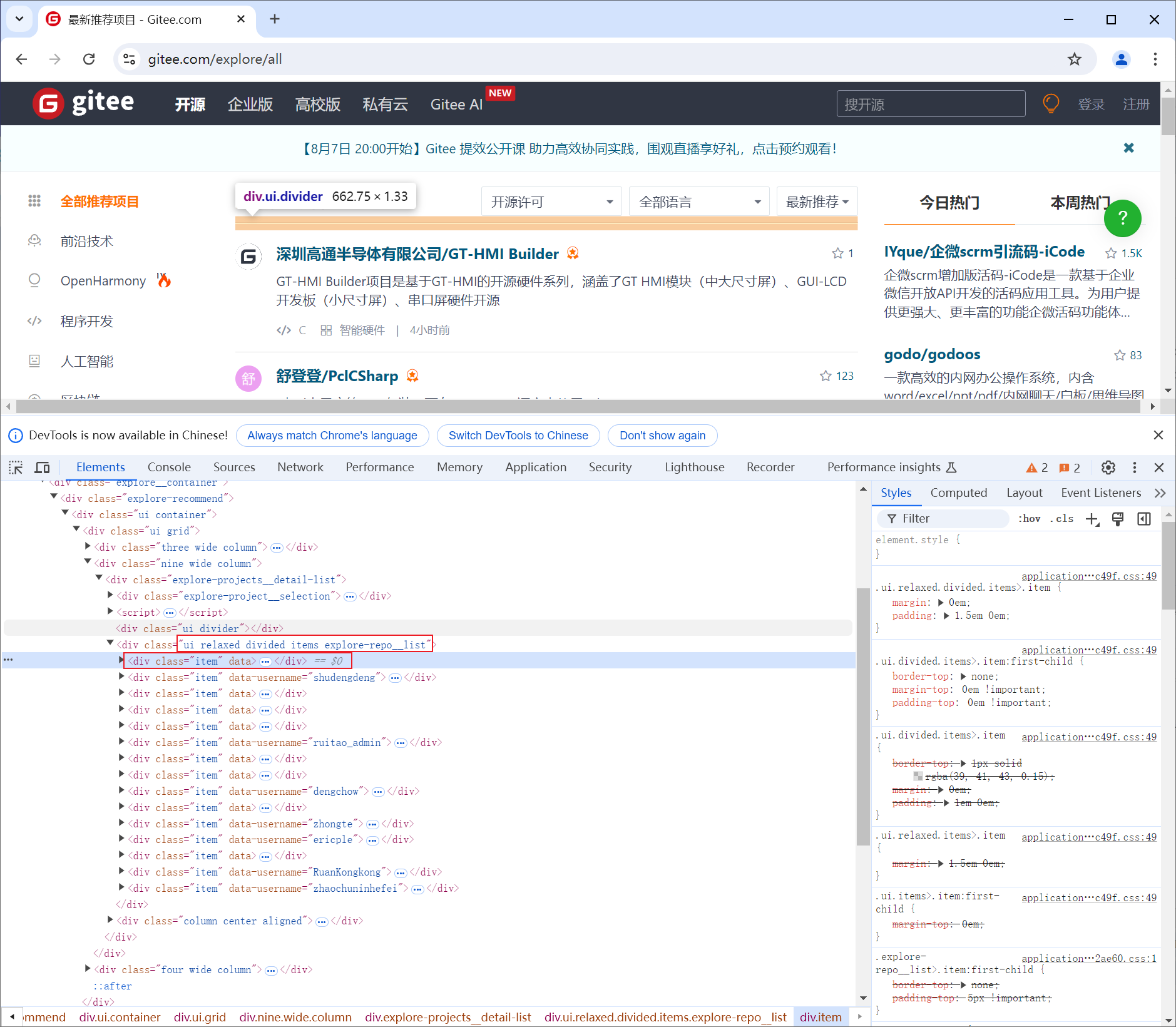
通过分析 html 代码,我们可以看出,每个结果的标题都存在class为'ui relaxed divided items explore-repo__list'里面,class为'item'的元素中。因此,我们可以获取页面中所有这些元素,再遍历获取其信息
示例代码
可以直接运行以下代码:
from DrissionPage import WebPage # 创建页面对象 page = WebPage() # 访问网址 page.get('https://gitee.com/explore/all') # 切换到收发数据包模式 page.change_mode() # 获取所有行元素 items = page.ele('.ui relaxed divided items explore-repo__list').eles('.item') # 遍历获取到的元素 for item in items: # 打印元素文本 print(item('t:h3').text) # 选择 <h3> 标签并打印其文本内容,t代表标签选择器 print(item('.project-desc mb-1').text) # 选择 class 为 .project-desc mb-1 的元素并打印其文本内容 print()
输出如下:
深圳高通半导体有限公司/GT-HMI Builder GT-HMI Builder项目是基于GT-HMI的开源硬件系列,涵盖了GT HMI模块(中大尺寸屏)、GUI-LCD开发板(小尺寸屏)、串口屏硬件开源 舒登登/PclCSharp 对pcl点云库的.NET包装,可在C#、VB.net语言中使用pcl Ascend/cann-hccl cann-hccl,是基于昇腾硬件的高性能集合通信库(Huawei Collective Communication Library,简称HCCL)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号