Python基本数据类型
一、标准数据类型
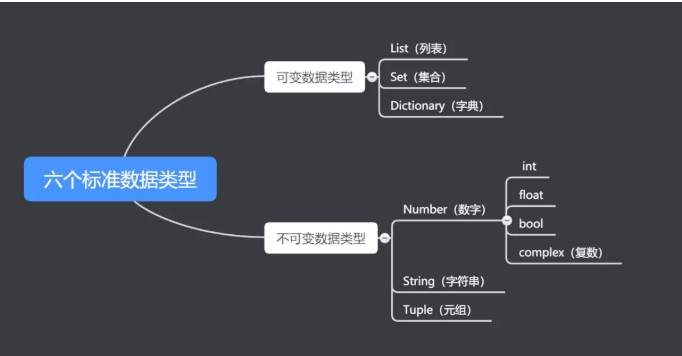
Python3 中常见的数据类型有:
- Number(数字)
- String(字符串)
- bool(布尔类型)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
Python3 的六个标准数据类型中:
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
此外还有一些高级的数据类型,如: 字节数组类型(bytes)。
二、Number(数字)
Python3 支持 int、float、bool、complex(复数)。
- 在Python 3里,只有一种整数类型 int,表示为长整型,没有 python2 中的 Long。
- 像大多数语言一样,数值类型的赋值和计算都是很直观的。
- 内置的 type() 函数可以用来查询变量所指的对象类型。
>>> a, b, c, d = 20, 5.5, True, 4+3j >>> print(type(a), type(b), type(c), type(d)) <class 'int'> <class 'float'> <class 'bool'> <class 'complex'>
2.1.int
int表示整数(integer),可以存储任意大小的整数,不受位数限制。整数可以是正数、负数或零。
a = 42 b = -7 c = 0 print(type(a)) # 输出: <class 'int'> print(type(b)) # 输出: <class 'int'> print(type(c)) # 输出: <class 'int'>
2.2.float
float表示浮点数(floating-point number),用来存储带小数部分的数字。浮点数是基于IEEE 754标准的双精度浮点数,通常占用64位内存。
x = 3.14159 y = -0.001 z = 1.0 print(type(x)) # 输出: <class 'float'> print(type(y)) # 输出: <class 'float'> print(type(z)) # 输出: <class 'float'>
2.3.int 和 float 的转换
Python 提供了函数来在int和float类型之间进行转换。
- 将
int转换为float:使用float()函数 - 将
float转换为int:使用int()函数(注意,这会丢失小数部分)
# int 转换为 float a = 42 b = float(a) print(b) # 输出: 42.0 print(type(b)) # 输出: <class 'float'> # float 转换为 int x = 3.14159 y = int(x) print(y) # 输出: 3 print(type(y)) # 输出: <class 'int'>
2.4.布尔值
布尔类型(bool)是Python中的一种数据类型,它只有两个值:True 和 False。尽管布尔类型在逻辑运算中有其特定的用途,但从数据类型的角度来看,布尔值实际上是整数类型的子类。在Python中,True 等同于数字1,而 False 等同于数字0。这种特性使得布尔值可以直接参与数学运算,尽管在实际应用中,我们通常不会将布尔值用作普通的数学运算。
布尔值常量:
is_true = True is_false = False
比较运算符:
Python中可以使用比较运算符来得到布尔值。例如:
a = 5 b = 3 print(a > b) # 输出: True print(a == b) # 输出: False
逻辑运算符:
Python中有三种逻辑运算符:and、or 和 not,用于布尔值之间的运算。
a = True b = False print(a and b) # 输出: False print(a or b) # 输出: True print(not a) # 输出: False
条件语句:
布尔值常用于条件语句(如 if、elif 和 else)中,用于控制程序的执行流。
if a > b: print("a is greater than b") else: print("a is not greater than b")
布尔值与其他数据类型:
在Python中,很多其他类型的值可以转换为布尔值。以下值会被转换为 False:
NoneFalse- 零(
0、0.0等) - 空序列或集合(如
''、[]、{}等)
其他所有值都被转换为 True。
print(bool(0)) # 输出: False print(bool("")) # 输出: False print(bool([])) # 输出: False print(bool(123)) # 输出: True print(bool("Hello")) # 输出: True
2.5.复数
复数由一个实数部分和一个虚数部分组成,虚数部分以字母j结尾。例如,复数3 + 4j表示实数部分为3,虚数部分为4。
复数的作用:
-
科学计算:复数在工程、物理学和数学领域中广泛应用,特别是在处理电路分析、信号处理和量子力学等方面。
-
傅里叶变换和信号处理:复数在傅里叶变换中起着至关重要的作用,傅里叶变换是信号处理和图像处理的重要工具。
-
控制系统:在控制系统设计中,复数用于表示系统的极点和零点,以分析系统的稳定性和响应特性。
在Python中使用复数
Python内置对复数的支持,可以直接使用复数进行计算。复数以complex类型表示,可以使用以下几种方式创建复数:
⑴.直接赋值:
z = 3 + 4j
⑵.使用complex构造函数:
z = complex(3, 4)
复数的属性和方法
- 实部和虚部:可以通过
z.real和z.imag来访问复数的实部和虚部。
z = 3 + 4j print(z.real) # 输出: 3.0 print(z.imag) # 输出: 4.0
- 共轭复数:可以通过
z.conjugate()方法获取复数的共轭。
z = 3 + 4j print(z.conjugate()) # 输出: (3-4j)
在复数中,复数的共轭(或称为共轭复数)是指将复数的虚部取相反数得到的复数。
复数的运算
Python支持复数的基本运算,如加法、减法、乘法、除法等:
z1 = 5 + 6j z2 = 2 - 3j # 加法 add_result = z1 + z2 print("加法结果:", add_result) # 减法 sub_result = z1 - z2 print("减法结果:", sub_result) # 乘法 mul_result = z1 * z2 print("乘法结果:", mul_result) # 除法 div_result = z1 / z2 print("除法结果:", div_result) # 实部和虚部 print("z1的实部:", z1.real) print("z1的虚部:", z1.imag) # 共轭复数 print("z1的共轭:", z1.conjugate())
假设有两个复数 z1=a+biz_1 = a + biz1=a+bi 和 z2=c+diz_2 = c + diz2=c+di,它们的乘法定义如下:

假设有两个复数 z1=a+biz_1 = a + biz1=a+bi 和 z2=c+diz_2 = c + diz2=c+di,它们的除法定义如下:

2.5.数值运算
# 两个 int 之间的运算 a = 5 b = 3 print(a + b) # 输出: 8 print(a - b) # 输出: 2 print(a * b) # 输出: 15 print(a / b) # 输出: 1.6666666666666667 (结果为 float 类型) print(a // b) # 输出: 1 (整数除法,结果为 int 类型) print(a % b) # 输出: 2 (取余数) # int 和 float 之间的运算 x = 4.0 print(a + x) # 输出: 9.0 (结果为 float 类型) print(a - x) # 输出: 1.0 (结果为 float 类型) print(a * x) # 输出: 20.0 (结果为 float 类型) print(a / x) # 输出: 1.25 (结果为 float 类型)
总结
- int:表示整数,任意大小,不带小数部分。
- float:表示浮点数,带小数部分,遵循IEEE 754标准。
- 类型转换:可以使用
int()和float()函数在int和float之间进行转换。 - 运算:
int和float可以参与算术运算,混合运算结果为float类型。
三、字符串
说到字符串,我们自然会想到中文字符串。但是中文字符串涉及到一些字符集、编码、解码的问题,现在引入这些概念会吧开始的学习复杂化。所以放在后续章节,目前阶段只讨论英文字符串
3.1.字符串的定义
字符串可以用,单引号,双引号或者三引号括起来。其中三引号里面是可以跨行的字符串
#单引号 >>>auto = 'hello world'
#双引号 >>>auto = "my name is Augus" #三引号 >>>auto = '''python is cool''' #三引号跨行 >>>auto = '''python is cool!'''
3.2.字符串的拼接
3.2.1.拼接
#加号连接 >>>a,b = 'hello','world' >>>a+b >>>'hello world' #逗号连接 **使用逗号,只能用于print打印输出 >>>a,b = 'hello','world' >>>print(a,b) #上述代码如果进行赋值操作会生成元组 >>>a,b ("hello","world") #直接连接 >>>print("hello" "world") helloworld
3.2.2.字符串的乘法(重复n次)
>>>"sid" * 3 'sidsidsid'
3.2.3.获取字符串的长度
len('my name is: Augus')
3.2.4.字符串的比较
>>>str1 = 'abc' >>>str2 = 'lmn' >>>str3 = 'xyz' >>>str1 == 'abc' Ture >>>str1 < str2 True >>>str2 != str3 True >>>str1 < str3 and str2 == 'xyz' False
当我们比较字符串大小的时候,python是按照字符的字典顺序来比较的
3.3.字符串的squence操作
我们看到字符串‘HELLOWORLD’,每个字符串可以用正数下标表示,也可以使用负数下标表示它们在字符串中的位置

注意:
- 字符串截取时,数字位是从0开始,而不是从1开始。所以一个长度为n的字符串的最后一个字符的下标是n-1
- 我们可以截取(slice)字符串的一部分内容。截取的操作符是[ ],这个操作符如果只有一个下标参数,那么我们将得到一个字符
- 如果参数有两个,中间以冒号(:)隔开,将返回一段字字符串。截取操作slice有时也称为切片操作.
例如:str[start:end],我们将得到从下标start开始,到下标end结束,但不包括下标end对应字符的那部分字符串
>>>str = 'zxcvbnm' >>>str[0] 'z' >>>str[-7] 'z' #注意:这种情况,左含右不含 >>>str[2:4] 'cv' >>>str[-5:-3] 'cv' >>>str[3:] 'vbnm' >>>str[-4:] 'vbnm' >>>str[:3] ‘zxc >>>str[:-4] 'zxc'
3.4.字符串格式化
3.4.1.旧式”字符串解析(%操作符)
>>>'hello,%s is my name, I like %s' % ('Augus','footall') 'hello,Augus is my name, I like footall'
3.4.2.str.format
⑴.使用位置参数
从以下例子可以看出位置参数不受顺序约束,且可以为{},只要format里面有相对应的参数值即可,参数索引从0开始,传入位置参数可用列表即可
>>>"my name is {},i am {} years old".format("wangwu",18) "my name is wangwu,i am 18 years old" >>>"my name is {0},i am {1} years old".format("wangwu",18) "my name is wangwu,i am 18 years old" >>>"my name is {1},i am {0} years old".format(18,"wangwu") "my name is wangwu,i am 18 years old"
⑵.使用关键字参数
关键字参数值要对的上,可用字典当做关键字参数传入时,字典前加**即可,如下例子3
>>>"my name is {name},i am {age} years old".format(name ="wangwu",age = 18) 'my name is wangwu,i am 18 years old' >>>info = {"name":"wangwu","age":18} >>>"my name is {ele[name]},i am {ele[age]} years old".format(ele=info) 'my name is wangwu,i am 18 years old' #例3:将字典当做关键字参数传入 >>>info = {"name":"wangwu","age":18} >>>"my name is {name},i am {age} years old".format(**info) 'my name is wangwu,i am 18 years old'
3.4.3.字符串插值/f-string
在python3.6中添加一个新的字符串格式化方法,被称为字面量格式化字符串或者"f-string"。
>>>name = badboy >>>f'Hello,{name}!' 'hello,badboy' >>>a=5 >>>b=10 >>>f'Five plus ten is {a+b}and not {2*(a+b)}' 'Five plus ten is 15 and not 30.'
3.5.字符串常见方法
1. len(string)
返回字符串的长度。
s = "Hello, World!" print(len(s)) # 输出: 13
2. count(str, beg=0, end=len(string))
返回子字符串 str 在字符串中出现的次数,如果指定 beg 和 end,则在指定范围内返回出现的次数。
s = "Hello, World! Hello!" print(s.count("Hello")) # 输出: 2 print(s.count("Hello", 0, 10)) # 输出: 1
3. capitalize()
将字符串的第一个字符转换为大写,其余字符转换为小写。
s = "hello, world!" print(s.capitalize()) # 输出: "Hello, world!"
4. center(width, fillchar)
返回一个指定宽度的居中字符串,fillchar 为填充字符,默认为空格。
s = "Hello" print(s.center(10)) # 输出: " Hello " print(s.center(10, '-')) # 输出: "--Hello---"
5. find(str, beg=0, end=len(string))
检测 str 是否包含在字符串中,如果在指定范围内找到则返回开始的索引值,否则返回 -1。
s = "Hello, World!" print(s.find("World")) # 输出: 7 print(s.find("world")) # 输出: -1 print(s.find("o", 5, 10)) # 输出: 8
6. replace(old, new [, max])
将字符串中的 old 替换成 new,如果指定 max,则替换不超过 max 次。
s = "Hello, World! Hello!" print(s.replace("Hello", "Hi")) # 输出: "Hi, World! Hi!" print(s.replace("Hello", "Hi", 1)) # 输出: "Hi, World! Hello!"
7. split(str="", num=string.count(str))
以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num 个子字符串。
s = "Hello, World! Hello!" print(s.split()) # 输出: ['Hello,', 'World!', 'Hello!'] print(s.split('!', 1)) # 输出: ['Hello, World', ' Hello!']
8. index(str, beg=0, end=len(string))
跟 find() 方法一样,只不过如果 str 不在字符串中会报一个异常。
s = "Hello, World!" print(s.index("World")) # 输出: 7 # print(s.index("world")) # 抛出异常: ValueError: substring not found
9. isalnum()
如果字符串至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False。
s = "Hello123" print(s.isalnum()) # 输出: True s = "Hello 123" print(s.isalnum()) # 输出: False
10. isalpha()
如果字符串至少有一个字符并且所有字符都是字母则返回 True,否则返回 False。
s = "Hello" print(s.isalpha()) # 输出: True s = "Hello123" print(s.isalpha()) # 输出: False
11. isdigit()
如果字符串只包含数字则返回 True,否则返回 False。
s = "12345" print(s.isdigit()) # 输出: True s = "12345a" print(s.isdigit()) # 输出: False
12. islower()
如果字符串中包含至少一个区分大小写的字符,并且所有这些字符都是小写,则返回 True,否则返回 False。
s = "hello" print(s.islower()) # 输出: True s = "Hello" print(s.islower()) # 输出: False
13. isspace()
如果字符串中只包含空格,则返回 True,否则返回 False。
s = " " print(s.isspace()) # 输出: True s = " a " print(s.isspace()) # 输出: False
14. istitle()
检测字符串中所有的单词拼写首字母是否为大写,且其他字母为小写。
s = "Hello World" print(s.istitle()) # 输出: True s = "hello World" print(s.istitle()) # 输出: False
15. lower()
转换字符串中所有大写字符为小写。
s = "Hello, World!" print(s.lower()) # 输出: "hello, world!"
16. max(str)
返回字符串中最大的字母。
s = "Hello, World!"
print(max(s)) # 输出: "r"
17. min(str)
返回字符串中最小的字母。
s = "Hello, World!" print(min(s)) # 输出: " "
18. startswith(str, beg=0, end=len(string))
检查字符串是否以 str 开头,如果是则返回 True,否则返回 False。如果 beg 和 end 指定值,则在指定范围内检查。
s = "Hello, World!" print(s.startswith("Hello")) # 输出: True print(s.startswith("World", 7)) # 输出: True
四、列表
在Python中,列表(list)是一种内置的数据类型,用于存储有序的元素集合。列表中的元素可以是任意类型,并且列表是可变的,即可以修改其内容。以下是有关Python列表的一些基本概念和操作:
4.1.创建列表
# 创建一个空列表 empty_list = [] # 创建一个包含多个元素的列表 fruits = ["apple", "banana", "cherry"]
4.2.访问元素
在Python中,列表索引用于访问列表中的特定元素。列表索引从0开始,表示列表中元素的位置。以下是有关列表索引的详细信息和操作示例:
基本索引
- 正索引:从0开始的正整数索引。例如,
list[0]访问列表的第一个元素。 - 负索引:从-1开始的负整数索引,表示从列表的末尾开始计数。例如,
list[-1]访问列表的最后一个元素。
fruits = ["apple", "banana", "cherry", "date"] # 正索引 print(fruits[0]) # 输出: apple print(fruits[1]) # 输出: banana # 负索引 print(fruits[-1]) # 输出: date print(fruits[-2]) # 输出: cherry
嵌套列表索引
如果列表中包含其他列表,可以使用多个索引访问嵌套的元素:
matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] # 访问第一行第二列的元素 print(matrix[0][1]) # 输出: 2 # 访问第二行的整个列表 print(matrix[1]) # 输出: [4, 5, 6]
4.3.修改元素
可以通过索引修改列表中的元素
fruits[1] = "blueberry" print(fruits) # 输出: ["apple", "blueberry", "cherry"]
4.4.添加元素
可以使用 append() 方法在列表末尾添加元素,也可以使用 insert() 方法在指定位置添加元素。
fruits.append("date") print(fruits) # 输出: ["apple", "blueberry", "cherry", "date"] fruits.insert(1, "banana") print(fruits) # 输出: ["apple", "banana", "blueberry", "cherry", "date"]
4.5.删除元素
可以使用 remove() 方法删除指定元素,使用 pop() 方法删除指定位置的元素或删除并返回最后一个元素,使用 del 语句删除指定位置的元素或整个列表。
fruits.remove("banana") print(fruits) # 输出: ["apple", "blueberry", "cherry", "date"] fruits.pop(1) print(fruits) # 输出: ["apple", "cherry", "date"] last_fruit = fruits.pop() print(last_fruit) # 输出: date print(fruits) # 输出: ["apple", "cherry"] del fruits[0] print(fruits) # 输出: ["cherry"] del fruits # 删除整个列表
4.6.列表切片
切片操作允许你获取列表的一部分,使用 [start:stop:step] 语法:
- start:切片开始的索引(包括此索引的元素)。
- stop:切片结束的索引(不包括此索引的元素)。
- step:切片的步长(默认为1)。
numbers = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # 获取索引2到5之间的元素 print(numbers[2:6]) # 输出: [2, 3, 4, 5] # 获取从开头到索引5的元素 print(numbers[:6]) # 输出: [0, 1, 2, 3, 4, 5] # 获取从索引5到结尾的元素 print(numbers[5:]) # 输出: [5, 6, 7, 8, 9] # 获取所有元素,每隔一个取一个 print(numbers[::2]) # 输出: [0, 2, 4, 6, 8] # 反转列表 print(numbers[::-1]) # 输出: [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
列表索引的注意事项
-
越界错误:访问超出列表范围的索引会引发
IndexError。例如,访问fruits[10]会出错,因为列表fruits的有效索引范围是0到3。
# 示例 # print(fruits[10]) # 会引发 IndexError
- 切片越界:切片操作不会引发错误,即使切片的结束索引超出了列表的实际长度。例如,
numbers[2:20]会返回从索引2到列表末尾的所有元素,而不会引发错误。
4.7.列表常用方法
⑴.list.append(obj): 在列表末尾添加新的对象。
my_list = [1, 2, 3] my_list.append(4) print(my_list) # Output: [1, 2, 3, 4]
⑵.list.count(obj): 统计某个元素在列表中出现的次数。
my_list = [1, 2, 2, 3, 4, 2] print(my_list.count(2)) # Output: 3
⑶.list.extend(seq): 在列表末尾一次性追加另一个序列中的多个值。
list1 = [1, 2, 3] list2 = [4, 5, 6] list1.extend(list2) print(list1) # Output: [1, 2, 3, 4, 5, 6]
⑷.list.index(obj): 找出列表中某个值第一个匹配项的索引位置。
my_list = [10, 20, 30, 20, 40] print(my_list.index(20)) # Output: 1 (第一个匹配项的索引)
⑸.list.insert(index, obj): 将对象插入列表的指定位置。
my_list = [1, 2, 3] my_list.insert(1, 5) print(my_list) # Output: [1, 5, 2, 3]
⑹.list.pop(index): 移除并返回列表中的一个元素,默认是最后一个元素。
my_list = [1, 2, 3] popped_element = my_list.pop() print(popped_element) # Output: 3 (被移除的元素) print(my_list) # Output: [1, 2]
⑺.list.remove(obj): 移除列表中某个值的第一个匹配项。
my_list = [1, 2, 3, 2] my_list.remove(2) print(my_list) # Output: [1, 3, 2] (只移除第一个匹配项)
⑻.list.reverse(): 反向列表中的元素。
my_list = [1, 2, 3] my_list.reverse() print(my_list) # Output: [3, 2, 1]
⑼.list.sort([func]): 对列表进行排序,可选择性地指定排序方法。
my_list = [3, 1, 2] my_list.sort() print(my_list) # Output: [1, 2, 3] (默认升序排序)
五、元组
在Python中,元组(Tuple)是一个有序的不可变序列,用于存储多个元素。元组与列表相似,但其主要区别在于元组一旦创建后,其内容和长度都不能被修改。这使得元组更适合用于不希望被修改的数据集合。下面是关于Python元组的一些基本特点和用法:
5.1.创建元组
在Python中,元组可以使用圆括号 () 来创建,元素之间用逗号分隔。
my_tuple = (1, 2, 3, 4, 5) empty_tuple = () single_element_tuple = (1,) # 单个元素的元组需要在元素后面加上逗号
5.2.访问元组元素
在Python中,元组(Tuple)的索引操作与列表(List)类似,可以使用索引访问元组中的元素。以下是关于元组索引的一些详细信息:
基本索引
- 正索引:从0开始,递增访问元组中的元素。
- 负索引:从-1开始,递减访问元组中的元素,表示从末尾开始的元素
my_tuple = (10, 20, 30, 40, 50) # 正索引 print(my_tuple[0]) # Output: 10 print(my_tuple[1]) # Output: 20 # 负索引 print(my_tuple[-1]) # Output: 50 print(my_tuple[-2]) # Output: 40
切片操作
可以使用切片操作符 : 访问元组的子集。切片返回一个新的元组。
my_tuple = (10, 20, 30, 40, 50) # 从索引1到3(不包括索引4) print(my_tuple[1:4]) # Output: (20, 30, 40) # 从开始到索引2(不包括索引3) print(my_tuple[:3]) # Output: (10, 20, 30) # 从索引2到结束 print(my_tuple[2:]) # Output: (30, 40, 50)
多维元组索引
元组可以包含其他元组,形成多维结构。访问多维元组时可以使用嵌套索引。
multi_tuple = ((1, 2, 3), (4, 5, 6), (7, 8, 9)) # 访问第一个子元组的第二个元素 print(multi_tuple[0][1]) # Output: 2 # 访问第二个子元组的第三个元素 print(multi_tuple[1][2]) # Output: 6
索引超出范围
如果尝试访问超出元组范围的索引,会引发 IndexError 错误。
my_tuple = (10, 20, 30) # 尝试访问索引3(超出范围) print(my_tuple[3]) # IndexError: tuple index out of range
元组的可变性与索引
尽管元组本身是不可变的(即你不能改变元组中的元素),你可以通过索引获取元组中的元素,但不能通过索引修改元素。如果需要修改元素,则需要创建一个新的元组。
my_tuple = (10, 20, 30) # 尝试通过索引修改元素(会引发 TypeError 错误) # my_tuple[1] = 25
5.3.元组的不可变性
元组一旦创建,其内容和长度都不能被修改。
my_tuple = (1, 2, 3) # 下面的操作会引发 TypeError 错误 # my_tuple[0] = 10 # del my_tuple[0]
5.4.元组的操作
切片操作
切片操作符 : 来访问元组的子集。切片返回一个新的元组
my_tuple = (10, 20, 30, 40, 50) # 从索引1到3(不包括4) print(my_tuple[1:4]) # Output: (20, 30, 40) # 从开始到索引2(不包括3) print(my_tuple[:3]) # Output: (10, 20, 30) # 从索引2到结束 print(my_tuple[2:]) # Output: (30, 40, 50) # 步长切片 print(my_tuple[::2]) # Output: (10, 30, 50)
成员检查
可以使用 in 运算符检查一个元素是否在元组中。
my_tuple = (10, 20, 30, 40, 50) # 检查元素是否在元组中 print(20 in my_tuple) # Output: True print(25 in my_tuple) # Output: False
元组拼接
可以使用 + 运算符将两个元组拼接在一起,得到一个新的元组。
tuple1 = (1, 2, 3) tuple2 = (4, 5, 6) combined_tuple = tuple1 + tuple2 print(combined_tuple) # Output: (1, 2, 3, 4, 5, 6)
元组重复
可以使用 * 运算符重复元组中的元素,得到一个新的元组。
my_tuple = (1, 2, 3) repeated_tuple = my_tuple * 3 print(repeated_tuple) # Output: (1, 2, 3, 1, 2, 3, 1, 2, 3)
5.5.元组的方法
元组并不像列表那样拥有丰富的方法,但提供了少数几个方法来操作元组。
count(x): 统计元素 x 在元组中出现的次数。index(x): 返回元素 x 在元组中第一次出现的索引。- len(tuple) 计算元组元素个数。
- max(tuple) 返回元组中元素最大值。
- min(tuple) 返回元组中元素最小值。
- tuple(seq) 将列表转换为元组。
my_tuple = (1, 2, 3, 2, 4, 2) print(my_tuple.count(2)) # Output: 3 print(my_tuple.index(2)) # Output: 1
5.6.使用元组的场景
- 当需要确保某个数据集合在整个程序执行过程中保持不变时,使用元组比较合适,因为它们是不可变的。
- 可以用作字典的键(因为字典的键必须是不可变的)或者作为一些函数的返回值,确保返回的数据不会被修改。
元组的不可变性使得它们在某些情况下比列表更加安全和高效。
六、集合
在 Python 中,集合(set)是一种无序且不重复的数据集合。集合可以用于去除重复元素、集合运算(如交集、并集、差集)等操作。Python 的集合由大括号 {} 或者 set() 函数创建。
6.1.创建集合
- 使用大括号创建集合:
fruits = {"apple", "banana", "cherry"}
- 使用 set() 函数创建集合:
numbers = set([1, 2, 3, 4, 5])
6.2.添加元素
使用 add() 方法添加单个元素:
fruits.add("orange")
6.3.删除元素
使用 remove() 方法删除指定元素(如果元素不存在会报错):
fruits.remove("banana")
使用 discard() 方法删除指定元素(如果元素不存在不会报错):
fruits.discard("banana")
使用 pop() 方法随机删除一个元素,并返回该元素(集合是无序的,因此删除的是任意元素):
removed_item = fruits.pop()
6.4.集合运算
并集:使用 union() 方法或 | 运算符
set1 = {1, 2, 3}
set2 = {3, 4, 5}
union_set = set1.union(set2)
# 或者使用
union_set = set1 | set2
交集:使用 intersection() 方法或 & 运算符
intersection_set = set1.intersection(set2) # 或者使用 intersection_set = set1 & set2
差集:使用 difference() 方法或 - 运算符
difference_set = set1.difference(set2) # 或者使用 difference_set = set1 - set2
对称差集:使用 symmetric_difference() 方法或 ^ 运算符
symmetric_difference_set = set1.symmetric_difference(set2) # 或者使用 symmetric_difference_set = set1 ^ set2
6.5.其他操作
检查元素是否在集合中:使用 in 关键字
if "apple" in fruits: print("Apple is in the set")
获取集合大小:使用 len() 函数
size = len(fruits)
清空集合:使用 clear() 方法
fruits.clear()
复制集合:使用 copy() 方法
fruits_copy = fruits.copy()
6.6.示例代码
以下是一个综合使用集合操作的示例:
# 创建集合 fruits = {"apple", "banana", "cherry"} # 添加元素 fruits.add("orange") # 删除元素 fruits.remove("banana") # 集合运算 set1 = {1, 2, 3} set2 = {3, 4, 5} # 并集 union_set = set1 | set2 # 交集 intersection_set = set1 & set2 # 差集 difference_set = set1 - set2 # 对称差集 symmetric_difference_set = set1 ^ set2 # 输出结果 print("Fruits:", fruits) print("Union:", union_set) print("Intersection:", intersection_set) print("Difference:", difference_set) print("Symmetric Difference:", symmetric_difference_set)
七、字典
Python 中的字典(dict)是一种用于存储键值对的无序集合。每个键(key)在字典中是唯一的,而每个键都对应一个值(value)。字典是非常灵活且高效的数据结构,常用于各种需要存储和查找数据的场景。
7.1.创建字典
使用大括号 {} 创建字典:
person = {"name": "Alice", "age": 30, "city": "New York"}
使用 dict() 函数创建字典:
person = dict(name="Alice", age=30, city="New York")
7.2.访问和修改字典的值
访问字典中的值:
name = person["name"] # 访问键为 "name" 的值
修改字典中的值:
person["age"] = 31 # 将键为 "age" 的值更新为 31
使用 get() 方法访问值(可以提供默认值):
city = person.get("city", "Unknown") # 如果键不存在,返回 "Unknown"
7.3.添加和删除键值对
添加新的键值对:
person["email"] = "alice@example.com"
删除键值对:
使用 del 语句:
del person["email"]
使用 pop() 方法(返回被删除的值):
email = person.pop("email", "Not found") # 如果键不存在,返回 "Not found"
使用 popitem() 方法(删除并返回最后添加的键值对):
last_item = person.popitem()
7.4.字典操作
获取所有键:
keys = person.keys()
获取所有值:
values = person.values()
获取所有键值对:
items = person.items()
合并字典:
dict1 = {"a": 1, "b": 2}
dict2 = {"b": 3, "c": 4}
dict1.update(dict2) # dict1 现在是 {"a": 1, "b": 3, "c": 4}
清空字典:
person.clear()
copy(): 返回字典的浅拷贝。示例:
radiansdict = {'a': 1, 'b': 2}
new_dict = radiansdict.copy()
print(new_dict) # 输出: {'a': 1, 'b': 2}
fromkeys(seq[, value]): 创建一个新字典,以序列 seq 中的元素作为键,value 为所有键的初始值。示例:
keys = ['a', 'b', 'c'] new_dict = dict.fromkeys(keys, 0) print(new_dict) # 输出: {'a': 0, 'b': 0, 'c': 0}
get(key[, default]): 返回指定键的值,如果键不在字典中返回默认值 default。示例:
radiansdict = {'a': 1, 'b': 2}
print(radiansdict.get('a')) # 输出: 1
print(radiansdict.get('c', 0)) # 输出: 0
setdefault(key[, default]): 和 get() 类似,但如果键不在字典中,会将键添加到字典并将值设为 default。示例:
radiansdict = {'a': 1, 'b': 2}
print(radiansdict.setdefault('c', 3)) # 输出: 3
print(radiansdict) # 输出: {'a': 1, 'b': 2, 'c': 3}
八、可变数据类型和不可变数据类型
8.1.可变数据类型和不可变数据类型是什么?
可变和不可变都是基于内存地址来说的。
- 不可变数据类型: 当该数据类型的对应变量的值发生了改变,那么它对应的内存地址也会发生改变,对于这种数据类型,就称不可变数据类型。
- 可变数据类型 :当该数据类型的对应变量的值发生了改变,那么它对应的内存地址不发生改变,对于这种数据类型,就称可变数据类型。
总结:不可变数据类型更改后地址发生改变,可变数据类型更改地址不发生改变
8.2.数据类型分类
在Python中数据类型有:整型,字符串,元组,集合,列表,字典。接下来查看他们分别属于不可变数据类型还是可变数据类型。
8.2.1.整型
>>> A = 1 >>> print(id(A),type(A)) 140710074386096 <class 'int'> >>> A = 100 >>> print(id(A),type(A)) 140710074389264 <class 'int'>
可以发现,当数据发生改变后,变量的内存地址发生了改变,那整型就是不可变数据类型。
8.2.2.字符串
>>> str1 = "hello" >>> print(id(str1),type(str1)) 2150342503216 <class 'str'> >>> str1 = "helloworld" >>> print(id(str1),type(str1)) 2150342503152 <class 'str'>
可以发现,当数据发生改变后,变量的内存地址发生了改变,那字符串就是不可变数据类型。
8.2.3.元组
元组被称为只读列表,即数据可以被查询,但不能被修改,但是我们可以在元组的元素中存放一个列表,通过更改列表的值来查看元组是属于可变还是不可变。
>>> list1 = [1,2,3] >>> tup1 = (1,2,list1) >>> print(id(tup1),type(tup1)) 2150342077440 <class 'tuple'> >>> list1[2] = 100 >>> print(id(tup1),type(tup1)) 2150342077440 <class 'tuple'>
我们可以发现,虽然元组数据发生改变,但是内存地址没有发生了改变,但是我们不可以以此来判定元组就是可变数据类型。
我们回头仔细想想元组的定义就是不可变的。修改了元组中列表的值,但是因为列表是可变数据类型,所以虽然在列表中更改了值,但是列表的地址没有改变,列表在元组中的地址的值没有改变,所以也就意味着元组没有发生变化。
我们就可以认为元组是不可变数据类型,因为元组是不可变的。
8.2.4 集合
集合我们常用来进行去重和关系运算,集合是无序的。
>>> s1 = {1,2,"hello","world"}
>>> print(id(s1),type(s1))
2150342489920 <class 'set'>
>>> s1.add("tom")
>>> print(id(s1),type(s1))
2150342489920 <class 'set'>
我们可以发现,虽然集合数据发生改变,但是内存地址没有发生了改变,那么集合就是可变数据类型。
8.2.5.列表
>>> list1 = [23,45,12,"zs"] >>> print(id(list1),type(list1)) 2150342481344 <class 'list'> >>> list1.append("ls") >>> print(id(list1),type(list1)) 2150342481344 <class 'list'>
我们可以发现,虽然列表数据发生改变,但是内存地址没有改变,那列表是可变数据类型。
8.2.6.字典
字典是python中唯一的映射类型,采用键值对(key-value)的形式存储数据。python对key进行哈希函数运算,根据计算的结果决定value的存储地址,所以字典是无序存储的。但是在3.6版本后,字典开始是有序的,这是新的版本特征。字典的key值可以是整型,字符串,元组,但是不可以是列表,集合,字典。
>>> info = {'name': 'zhangsan', 'age': 100}
>>> print(id(info),type(info))
2150342011840 <class 'dict'>
>>> info['age'] = 12
>>> print(id(info),type(info))
2150342011840 <class 'dict'>
我们可以发现,虽然字典数据发生改变,但是内存地址没有发生了改变,那么字典就是可变数据类型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号