102302110高悦作业1
• 作业①:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
1.代码与实验结果
首先打开网页,查看网页的源代码,找出并分析所要爬取内容的html结构

根据这个结构,用beautifulsoup进行解析并且提取文本输出
for line in lines:
rank=line.find("div", class_="ranking")
if rank is None:
rank=""
else:
rank=rank.text.strip()
name=line.find("span", class_="name-cn")
if name is None:
name=""
else:
name=name.text.strip()
tds = line.find_all("td")
if len(tds)>=4:
province=tds[2].text.strip()
type=tds[3].text.strip()
score=tds[4].text.strip()
else:
province=""
type=""
score=""
print(f"{rank:<6}{name:<16}{province:<6}{type:<8}{score}")
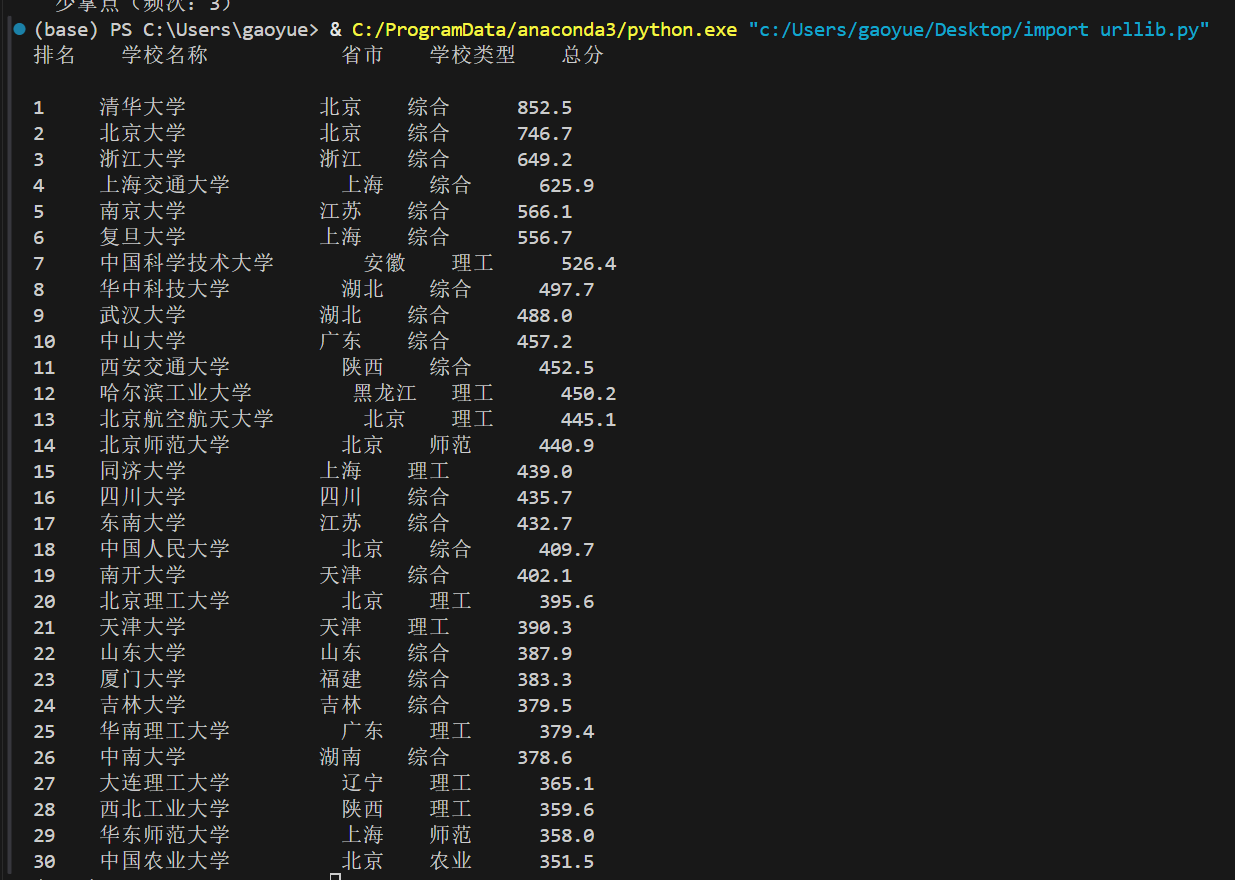
2.实验心得:通过这个实验,我了解了一般爬取网页信息的步骤:首先分析网页的源代码,找出、定位所需信息的特征,用bs或正则表达式进行提取,最后输出
• 作业②:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
1.代码与实验结果
选择了一个比较小众的网站:没得比
因为怕一直用爬虫访问会被网站禁止访问,因此先爬取下书包的第一页的源代码并保存的本地进行分析
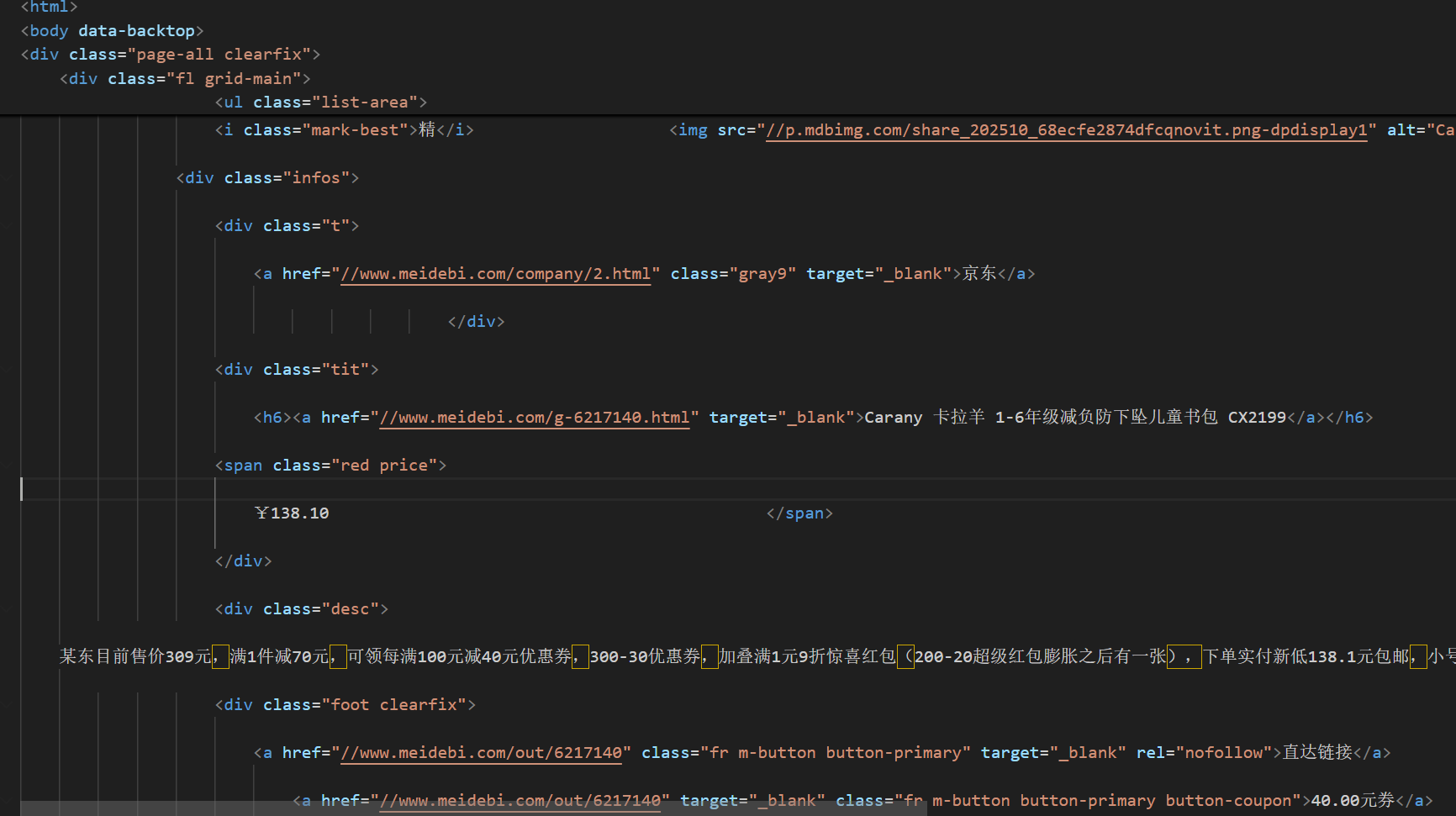
分析出相应的结构后,用正则表达式匹配
goods_pattern = re.compile(
r'<li class="clearfix">.*?'
r'<div class="tit">.*?<h6>.*?<a[^>]*?>(.*?)</a>.*?</h6>.*?'
r'<span class="red price">\s*¥([0-9.]+)\s*</span>',
re.DOTALL
)


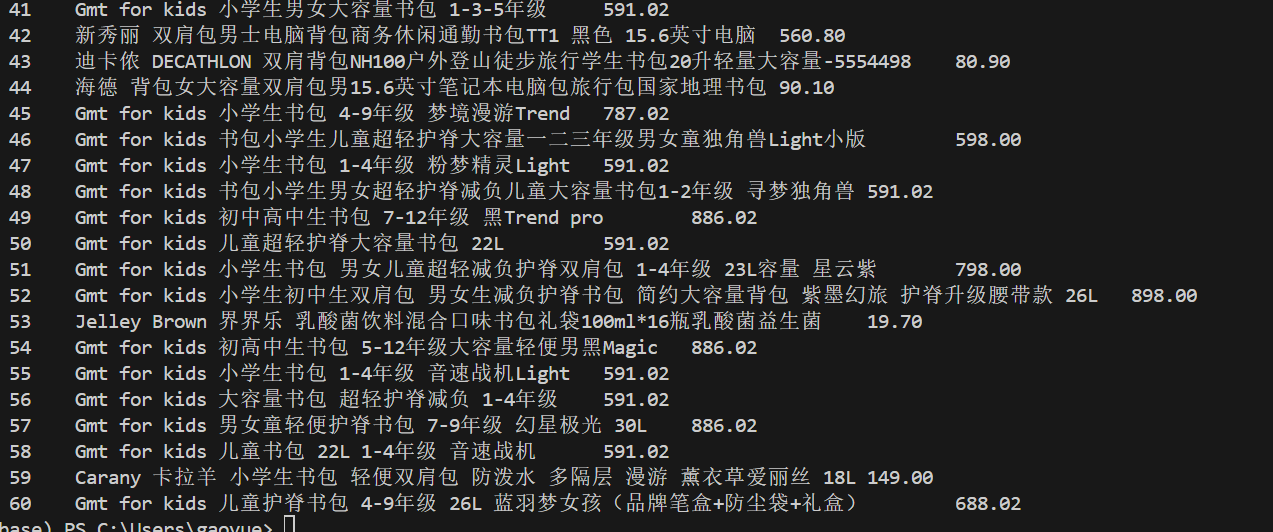
2.心得:前期一直执着于爬取淘宝,然后一直被反爬浪费了很多时间。以及我学会了如何分析正则表达式的写法。
• 作业③:爬取一个给定网页(https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG、JPG或PNG格式图片文件
1.代码与实验结果
首先还是先打开网站,找到有关jpg png等所在的特征

写出正则表达式,精准匹配
<img\s+src="(/__local/[^"]*?\.(jpg|jpeg|png))"\s+alt="([^"]*)"
2.心得:这次的三个作业让我学会了爬取网页的基本步骤

 浙公网安备 33010602011771号
浙公网安备 33010602011771号