级联,映射
一 . 级联
我们上次说过一个级联,numpy.concatenate, 接下来讲的级联和这个类似,只是多了一些参数而已!
正常操作,先倒包,后面就不在导包了
import numpy
import pandas
from pandas import Series,DataFrame
1. 使用pandas.concat()级联
与numpy.concatenate函数类似只是多了一些参数:
-- objs
-- axis()
-- keys
-- join='outer'/ 'inter': 表示级联方式,outer会将所有的项进行级联(忽略是否匹配),inner只会将匹配的级联
-- ignore_index=False
匹配级联
df1 = DataFrame(data=numpy.random.randint(0,100,size=(3,3)),index=['a','b','c'],columns=['A','B','C'])
df2 = DataFrame(data=numpy.random.randint(0,100,size=(3,3)),index=['a','e','c'],columns=['A','E','C'])
pandas.concat((df1,df1),axis=0,join='outer')
pandas.concat((df1,df2),axis=0,join='inner')
pandas.merge() 合并
1.merge和concat区别在于,merge需要依据某一共同的列来进行合并
2.使用pandas.merge()合并时,会自动根据两者相同column名称的列,作为key进行合并 3.注意每一列元素顺序可以不一致
参数:
- how: out取并集,inner取交集
- on: 当有多列相同的时候,可以用on指定哪一列进行合并.on的值为一个列名
合并实操
一对一合并(多对一和多对多同理) df1 = DataFrame({ 'employee':['Lias','Bob','Jack'], 'hire_date':[2000,2004,2008] }) df2 = DataFrame({ 'employee':['Bob','Jack','Lias'], 'group':['Account','Engineer','Engineer'] }) pandas.merge(df1,df2,how='outer') # 合并,取并集,默认employee作为key

df.sort.index() # 按索引排序
df.sort.values() # 对元素排序
!!! 如果两个表的 列名 不同,但是数据相同,可以用这两个列合并,left_on='列名',right='列名'
二 . 映射
1. replace
Series替换操作
单值替换
普通替换
字典替换(推荐)
多值替换
列表替换
字典替换(推荐)
参数
to_replace:被替换的元素
单值普通替换
s = Series(data=[3,4,5,6,8,10,9])
s.replace(to_replace=6,value='six')
多值替换
s.replace(to_replace=[3,4],value=['三','四'])
DataFrame中替换操作
单值替换
普通替换:替换所有符合要求的元素:to_replace=666,value='六六六'
按列指定单值替换:to_replace={列标签:需要被替换值} value='要换成的值'
多值替换
列表替换:to_replace=[] value=[]
字典替换(推荐): to_replace={to_replace:value}
下图就是df
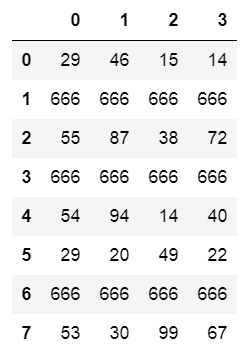
实操
df.replace(to_replace=666,value='六六六')
df.replace(to_replace={30:'参拾'})
map()函数:新建一列, map函数不是DataFrame的方法,而是Series的方法
map()可以映射新一列数据
map()中可以使lambda表达式
map()可以使用方法,可以是自定义方法
eg:map({to_replace:value}) 注意 map中不能使用sum之类的函数
实操
dic = {
'name':['jay','tom','jay'],
'salary':[12000,800,12000]
}
df = DataFrame(data=dic)
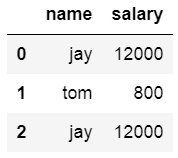
新增一列,给df中,添加一列,该列的值为英文名对应的中文名
# 映射关系表
dic ={
'jay':'周杰伦',
'tom':'汤姆'
}
df['c_name']= df['name'].map(dic) # map是Series的方法,所以要先取到Series对象

map当做一种运算工具,至于执行何种运算,是有map函数决定的,(参数:lambda,函数)
def after_salary(s):
if s<=3000:
return s
return s - (s-3000)*0.5
# 超过3000部分的钱缴纳50%的税
df['after_salary'] = df['salary'].map(after_salary) # 这个salary就是after_salary函数中的参数s
使用聚合操作对数据异常值检测和过滤
使用df.std()函数可以求的DataFrame对象每一列的标准差
创建一个1000行3列的df范围(0-1),求每一列的标准差
简单的一个小例子
df = DataFrame(data=numpy.random.random(size=(1000,3)),columns=['A','B','C'])
对df进行删选,去除标准差太大的数据,过滤条件为C列的数据大于两倍的C列标准差
double_std = df['C'].std()*2 # C列的标准差的2倍
~(df['C'] > double_std)
df.loc[~(df['C'] > double_std)] # 清洗过的数据
排序
使用 .take()函数排序
- take()函数接收一个索引列表,用数字表示,使得df根据列表中索引的顺序进行排序
- eg:df.take([1,3,5,2,4])
小案例
# df = DataFrame(data=numpy.random.random(size=(1000,3)),columns=['A','B','C'])
df.take([2,1,0],axis=1) # take的axis和drop是一样的, 1代表列 用隐式索引
df.take(numpy.random.permutation(3),axis=1) #也会生成3列
数据分类处理(重点)
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的值
数据分类处理:
- 分组:先把数据分为几组
- 用函数处理:为不同组的数据应用不同函数以转换数据
- 合并:把不同组得到的结果合并起来
数据分类处理的核心:
- groupby()函数
- groups属性:查看分组情况
- eg: df.groupby(by='item').groups
分组
from pandas import DataFrame,Series
df = DataFrame({
'item':['Apple','Banana','Orange','Banana','Orange','Apple'],
'price':[4,3,3,2,5,4],
'color':['red','yellow','yellow','green','green','green'],
'weight':[12,20,50,30,20,44]
})
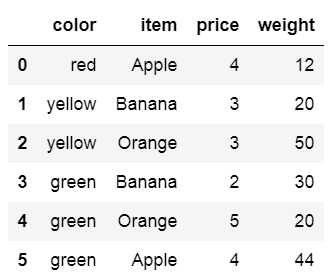
小案例
df.groupby(by='item',axis=0).groups
# 给df创建一个新列,内容为各个水果的平均价格
mean_price = df.groupby(by='item',axis=0)['price'].mean()
dic = mean_price.to_dict() #变成字典格式
df['mean_price'] = df['item'].map(dic)

高级数据聚合
使用groupby分组后,也可以使用transform和apply提供自定义函数实现更多的运算
df.groupby('item')['price'].sum() <==> df.groupby('item')['price'].apply(sum)
transform和apply都会进行运算,在transform或者apply中传入函数即可
transform和apply可以传入lambda表达式
自定义方法
def func(s):
sum = 0
for i in s:
sum += i
return sum/s.size
# 使用apply函数求出水果的平均价格
df.groupby(by='item')['price'].apply(func) # 返回的是没有映射的数据,func怎么定义根据调用它的数据类型决定
df.groupby(by='item')['price'].transform(func) # 返回的是映射过的数据
!!! apply 还可以代替运算工具形式的map
### 补充一下
df['color'].value_counts() # 计数


 浙公网安备 33010602011771号
浙公网安备 33010602011771号