爬虫
一 . 爬虫的基本信息
概念:
爬虫:通过编写程序模拟浏览器上网,然后让其去互联网上爬取/获取数据的过程
分类:
-- 分类(使用场景)(主要下面三种其他分类不用看)
-通用爬虫(爬取一整张页面数据,'抓取系统')
-聚焦爬虫(爬取页面中指定内容,前提是爬取一整张数据)
-增量式数据(用来 检测 网站数据更新情况,只爬取网站最新更新的数据)
机制:
反爬机制(网站制定了相关的手段或者策略阻止爬虫程序进行网页数据的抓取)
反反爬策略(爬虫破解网站指定的反爬策略)
--反爬机制
-robots协议:
-防君子不防小人(你要遵守就有用,不遵守协议可以爬)
模块:
requests
-环境安装 pip install requests
-作用:模拟浏览器发请求
-编码流程:1.指定url
2.发起请求
3.获取响应数据
4.持久化存储
二 . 示例
先来一个简简单单的小例子
# 爬取搜狗首页数据,按照编码流程写
import requests
# 1.获取url
url = "https://www.sogou.com/"
# 2,发起请求,get方法的返回值就是一个相应对象
response = requests.get(url=url, verify=False) # 有的不用写verify
# 3,获取响应数据,text是字符串形式的相应数据
page_text = response.text
# print(page_text)
# 4,持久化存储(应该存到数据库中,)
with open('./sogou.html', 'w', encoding='utf-8') as f:
f.write(page_text)
案例2:
import requests
url = 'https://www.sogou.com/web'
# 处理url请求的参数
wd = input('enter a word:')
param = {
'query': wd
}
# 去浏览器请求头中找
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/70.0.3538.110 Safari/537.36'
}
response = requests.get(url=url, params=param, verify=False, headers=headers) # get请求的时候参数是params
# 设置响应数据的编码,防止有乱码
response.encoding = 'utf-8'
# 3,获取响应数据,text是字符串形式的相应数据
page_text = response.text
# 持久化存储
name = wd + '.html'
with open(name, 'w', encoding='utf-8') as f:
f.write(page_text)
# 这里就遇到了反爬机制UA检测,User-Agent
# 解决策略,UA伪装
案例3:
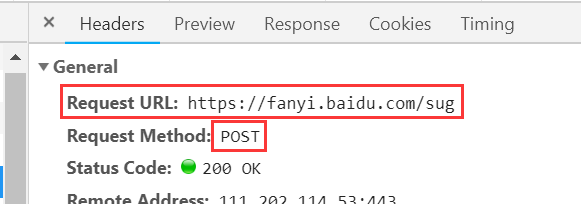
# 百度翻译
# 页面中有可能存在动态加载的数据
import requests
wd = input('enter a English word:')
url = 'https://fanyi.baidu.com/sug'
data = {
'kw': wd
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/70.0.3538.110 Safari/537.36'
}
response = requests.post(url=url, data=data, headers=headers, verify=False)
# post请求的参数是data
# 前提响应数据必须是json
obj_json = response.json()
print(obj_json)
案例4:
# 爬取豆瓣电影中的电影详情数据
import requests
url = 'https://movie.douban.com/j/chart/top_list'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/70.0.3538.110 Safari/537.36'
}
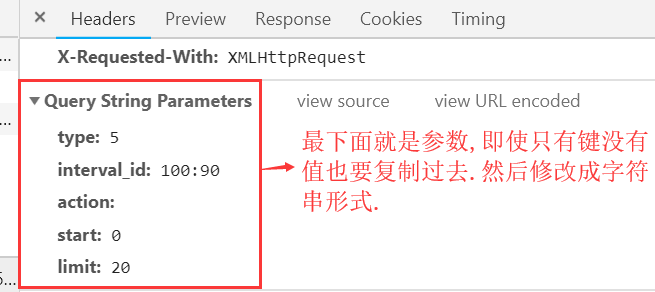
param = {
'type': '5',
'interval_id': '100:90',
'action': '',
'start': '0',
'limit': '20'
}
obj_json = requests.get(url=url, headers=headers, params=param, verify=False).json()
print(obj_json)
# 注意:页面中有些情况会包含动态加载的数据,比如下拉才会出来,这是ajax请求,在network中的XHR中
案例4:
# 爬取化妆品生产许可信息管理平台信息 http://125.35.6.84:81/xk/
# 企业详情页中的详情数据也是动态加载出来的,详情页也是通过ajax请求(url:域名都一样,只不过是携带的参数(id)不一样)到的(企业的详情信息)
import requests
url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/70.0.3538.110 Safari/537.36'
}
IDs = []
all_data = []
# 就要前三页数据
for page in range(1, 4):
data = {
'on': 'true',
'page': str(page),
'pageSize': '15',
'productName': '',
'conditionType': '1',
'applyname': '',
'applysn': '',
}
# 首页ajax请求返回的响应数据
json_obj = requests.post(url=url, headers=headers, verify=False, data=data).json()
for dic in json_obj['list']:
ID = dic['ID']
IDs.append(ID)
for id in IDs:
detail_post_url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById'
data = {
'id': id
}
detail_dic = requests.post(url=detail_post_url, headers=headers, data=data, verify=False).json()
all_data.append(detail_dic)
# print(all_data)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号