状态+checkpoint(重点)
状态+checkpoint(重点)
状态
-
flink用于保存之前计算结果的机制
-
flink会为每一个key保存一个状态
-
常用的sum(需要保存之前的计算结果) window(需要保存一段时间内的数据)内部都是有状态的
-
flink也提供了几种查用的状态类
- valueState: 单值状态,为每一个key保存一个值,可以是任何类型,必须可以序列化
- mapState: kv格式的状态,为每一个key保存一个kv格式的状态
- listState: 集合状态,为每一个key保存一个集合状态,集合中可以保存多个元素
- reducingState/AggregatingState:聚合状态,为每一个key保存一个值,再定义状态时需要一个聚合函数
-
flink的状态和普通变量的区别
- 普通变量是保存再flink的内存中的,如果flink任务执行失败,变量的数据会丢失
- flink的状态是一个特殊的变量,状态中的数据会被checkpoint持久化到hdfs中, 如果任务执行失败,重启任务,可以恢复状态
-
状态后端,用于保存状态的位置
-
HashMapStateBackend:
-
将flink的状态先保存TaskManager的内存中,在触发checkpoint的时候将taskmanager中的状态再持久化到hdfs中
-
可以直接使用
env.setStateBackend(new HashMapStateBackend())
-
-
EmbeddedRocksDBStateBackend:
-
RocksDS是一个本地的轻量级的数据库,数据在磁盘上
-
再启动lfink任务的时候会在每一个taskManager所在的节点启动一个rocksDB进程
-
flink的状态会先保存在rocksDb数据库中,当触发checkpoint的时候将数据库中的状态持久化到hdfs中
-
可以支持增量快照
-
使用rocksDb状态后端需要带入依赖
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-statebackend-rocksdb</artifactId> <version>1.15.0</version> </dependency> -
使用方式
env.setStateBackend(new EmbeddedRocksDBStateBackend(true))
-
-
checkpoint
-
checkpoint是flink用于持久化flink状态的机制
-
flink会定时将flink计算的状态持久化到hdfs中
-
开启checkpint的方法
-
在代码中开启- 每一个代码单独开启,优先级最高
// 每 1000ms 开始一次 checkpoint env.enableCheckpointing(1000) // 高级选项: // 设置模式为精确一次 (这是默认值) env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE) // 确认 checkpoints 之间的时间会进行 500 ms env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500) // Checkpoint 必须在一分钟内完成,否则就会被抛弃 env.getCheckpointConfig.setCheckpointTimeout(60000) // 允许两个连续的 checkpoint 错误 env.getCheckpointConfig.setTolerableCheckpointFailureNumber(2) // 同一时间只允许一个 checkpoint 进行 env.getCheckpointConfig.setMaxConcurrentCheckpoints(1) // 使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留 //RETAIN_ON_CANCELLATION: 当任务取消时保留checkpoint env.getCheckpointConfig.setExternalizedCheckpointCleanup( ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION) //指定状态后端 //EmbeddedRocksDBStateBackend eocksDb状态后端 env.setStateBackend(new EmbeddedRocksDBStateBackend(true)) //将状态保存到hdfs中,在触发checkpoint的时候将状态持久化到hdfs中 env.getCheckpointConfig.setCheckpointStorage("hdfs://master:9000/flink/checkpoint") -
在flink的集群的配置文件中同意开启-- flink新版才有
vim flink-conf.yaml
execution.checkpointing.interval: 3min execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION execution.checkpointing.max-concurrent-checkpoints: 1 execution.checkpointing.min-pause: 0 execution.checkpointing.mode: EXACTLY_ONCE execution.checkpointing.timeout: 10min execution.checkpointing.tolerable-failed-checkpoints: 0 state.backend: rocksdb state.checkpoints.dir: hdfs://master:9000/flink/checkpoint
-
-
从checkpoint恢复任务
-
可以在网页中指定checkpint的路径恢复,路径需要带上前缀hdfs://master:9000
hdfs://master:9000/flink/checkpoint/11edbec21742ceddebbb90f3e49f24b4/chk-35 -
也可以在命令行中重新提交任务,指定恢复任务的位置, 需要先上传jarr包
# -s 恢复任务的位置 flink run -t yarn-session -Dyarn.application.id=application_1658546198162_0005 -c com.shujia.flink.core.Demo15RocksDB -s hdfs://master:9000/flink/checkpoint/11edbec21742ceddebbb90f3e49f24b4/chk-35 flink-1.0.jar
如下代码,数据存储在hashmap中即内存中,当关闭任务后,数据就会消失
package com.wt.flink.core import org.apache.flink.api.common.functions.MapFunction import org.apache.flink.runtime.state.hashmap.HashMapStateBackend import org.apache.flink.streaming.api.CheckpointingMode import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup import org.apache.flink.streaming.api.scala._ import scala.collection.mutable object Demo11HashMap { def main(args: Array[String]): Unit = { val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment /** * 打开flink的checkpoint * */ // 每 1000ms 开始一次 checkpoint env.enableCheckpointing(1000) // 高级选项: // 设置模式为精确一次 (这是默认值) env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE) // 确认 checkpoints 之间的时间会进行 500 ms env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500) // Checkpoint 必须在一分钟内完成,否则就会被抛弃 env.getCheckpointConfig.setCheckpointTimeout(60000) // 允许两个连续的 checkpoint 错误 env.getCheckpointConfig.setTolerableCheckpointFailureNumber(2) // 同一时间只允许一个 checkpoint 进行 env.getCheckpointConfig.setMaxConcurrentCheckpoints(1) // 使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留 //RETAIN_ON_CANCELLATION: 当任务取消时保留checkpoint env.getCheckpointConfig.setExternalizedCheckpointCleanup( ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION) /** * 需要设置flink checkpoint保存状态的位置 * */ env.setStateBackend(new HashMapStateBackend()) //将状态保存到hdfs中 env.getCheckpointConfig.setCheckpointStorage("hdfs://master:9000/flink/checkpoint") val linesDS: DataStream[String] = env.socketTextStream("master", 8888) val wordsDS: DataStream[String] = linesDS.flatMap(_.split('<')) val keyByDS: KeyedStream[String, String] = wordsDS.keyBy(wrod => wrod) val countDS: DataStream[(String, Int)] = keyByDS.map( new MapFunction[String, (String, Int)] { /** * 同于保存单词的数量(状态) * * 使用一个普通的结果保存之前的计算结果,如果任务执行失败,集合中保存的结果会丢失 * */ private val wordCount = new mutable.HashMap[String, Int]() override def map(word: String): (String, Int) = { //如果map集合中有就获取让后累加,再更新, var count: Int = wordCount.getOrElse(word, 0) //累加 count += 1 //更新 wordCount.put(word, count) //返回新的单词的数量 (word, count) } }) countDS.print() env.execute() } }checkpoint 代码
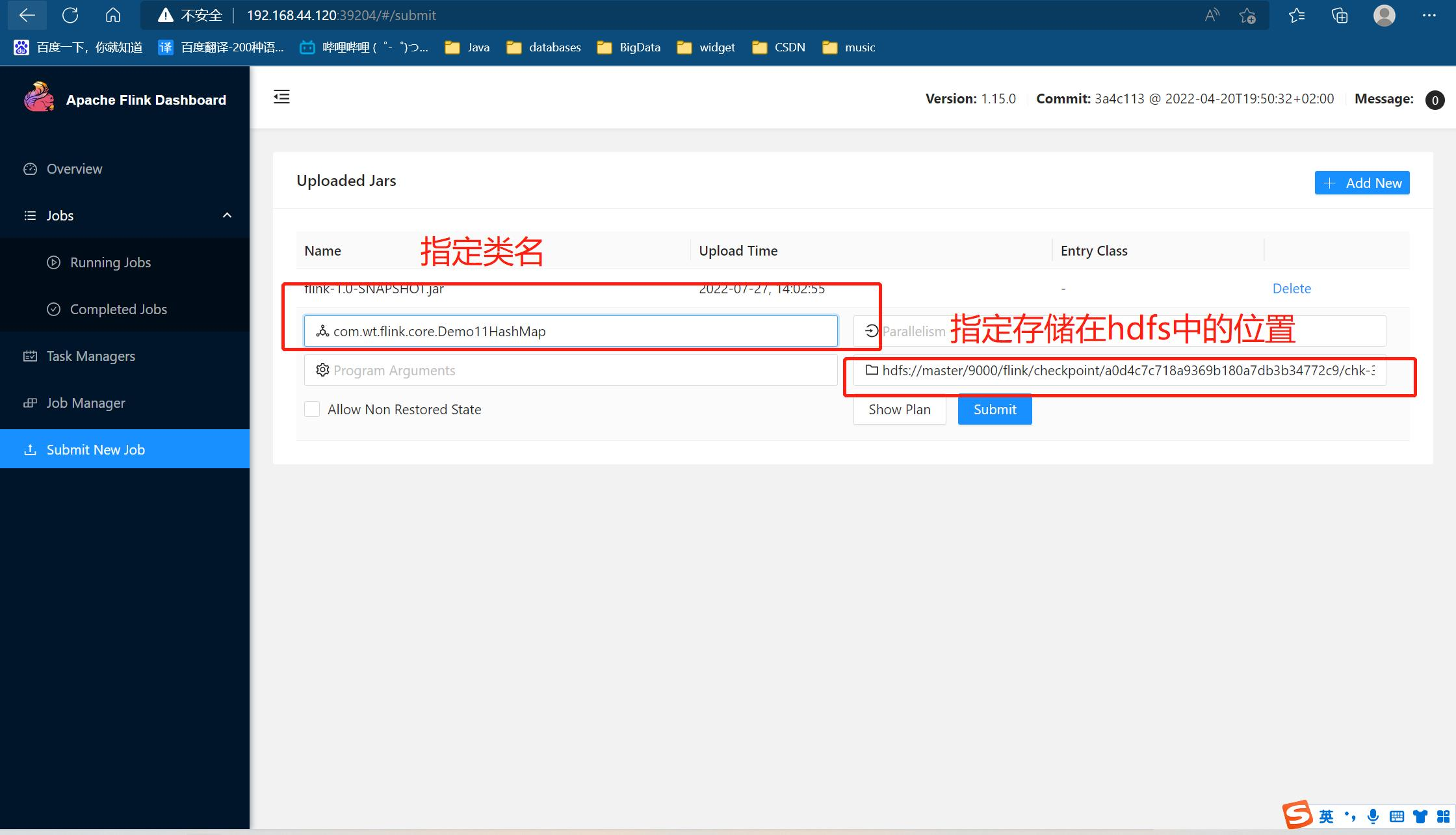
package com.wt.flink.core import org.apache.flink.runtime.state.hashmap.HashMapStateBackend import org.apache.flink.streaming.api.CheckpointingMode import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup import org.apache.flink.streaming.api.scala._ object Demo12Checkpoint { def main(args: Array[String]): Unit = { val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment /** * 打开flink的checkpoint * */ // 每 1000ms 开始一次 checkpoint env.enableCheckpointing(1000) // 高级选项: // 设置模式为精确一次 (这是默认值) env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE) // 确认 checkpoints 之间的时间会进行 500 ms env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500) // Checkpoint 必须在一分钟内完成,否则就会被抛弃 env.getCheckpointConfig.setCheckpointTimeout(60000) // 允许两个连续的 checkpoint 错误 env.getCheckpointConfig.setTolerableCheckpointFailureNumber(2) // 同一时间只允许一个 checkpoint 进行 env.getCheckpointConfig.setMaxConcurrentCheckpoints(1) // 使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留 //RETAIN_ON_CANCELLATION: 当任务取消时保留checkpoint env.getCheckpointConfig.setExternalizedCheckpointCleanup( ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION) /** * 需要设置flink checkpoint保存状态的位置 * */ env.setStateBackend(new HashMapStateBackend()) //将状态保存到hdfs中 env.getCheckpointConfig.setCheckpointStorage("hdfs://master:9000/flink/checkpoint") val linesDS: DataStream[String] = env.socketTextStream("master", 8888) val wordsDS: DataStream[String] = linesDS.flatMap(_.split(',')) val kvDS: DataStream[(String, Int)] = wordsDS.map((_, 1)) val keyByDS: KeyedStream[(String, Int), String] = kvDS.keyBy(_._1) /** * sum: 底层使用了flink的状态保存之前的计算结果 * flink的状态会被checkpoint持久化到hdfs中,任务被取消或者执行失败可以恢复之前的计算结果 */ val countDS: DataStream[(String, Int)] = keyByDS.sum(1) countDS.print() env.execute() } } 1.第一次提交上面的任务到集群中时,只需要指定类名即可
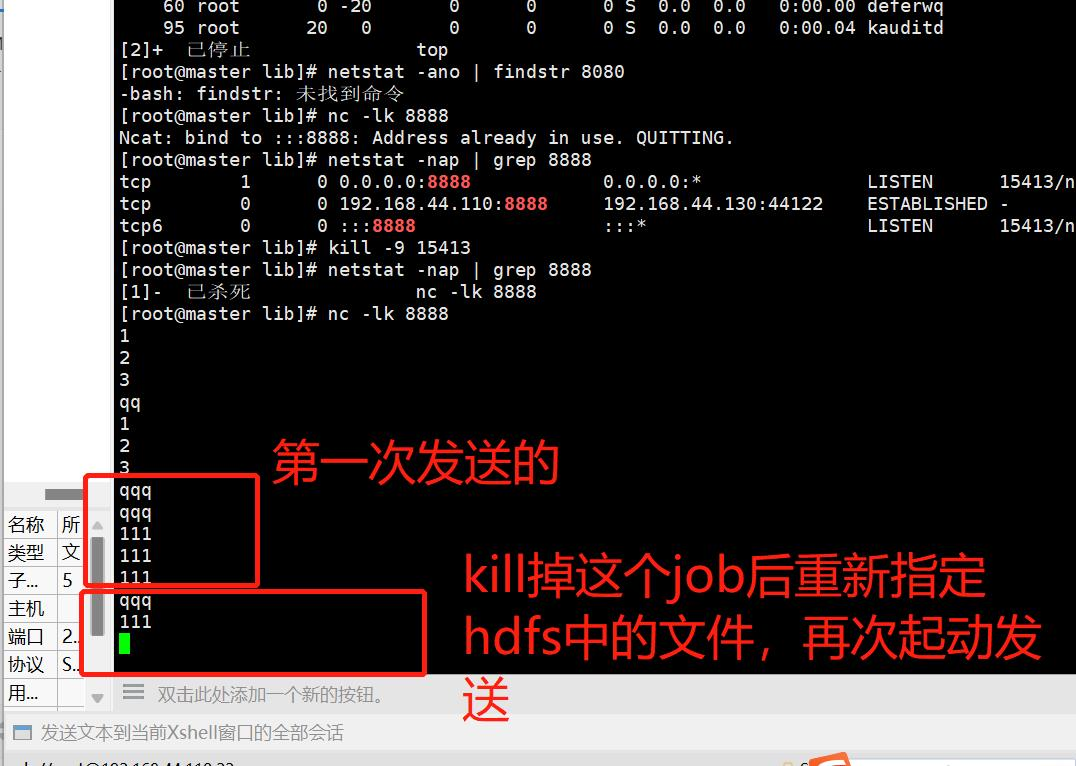
2.我们向其中打入数据
3.然后 kill 掉任务
- 再次提交任务,指定类名,还有快照在hdfs中存放的位置,如下:
-
打入的数据如下:
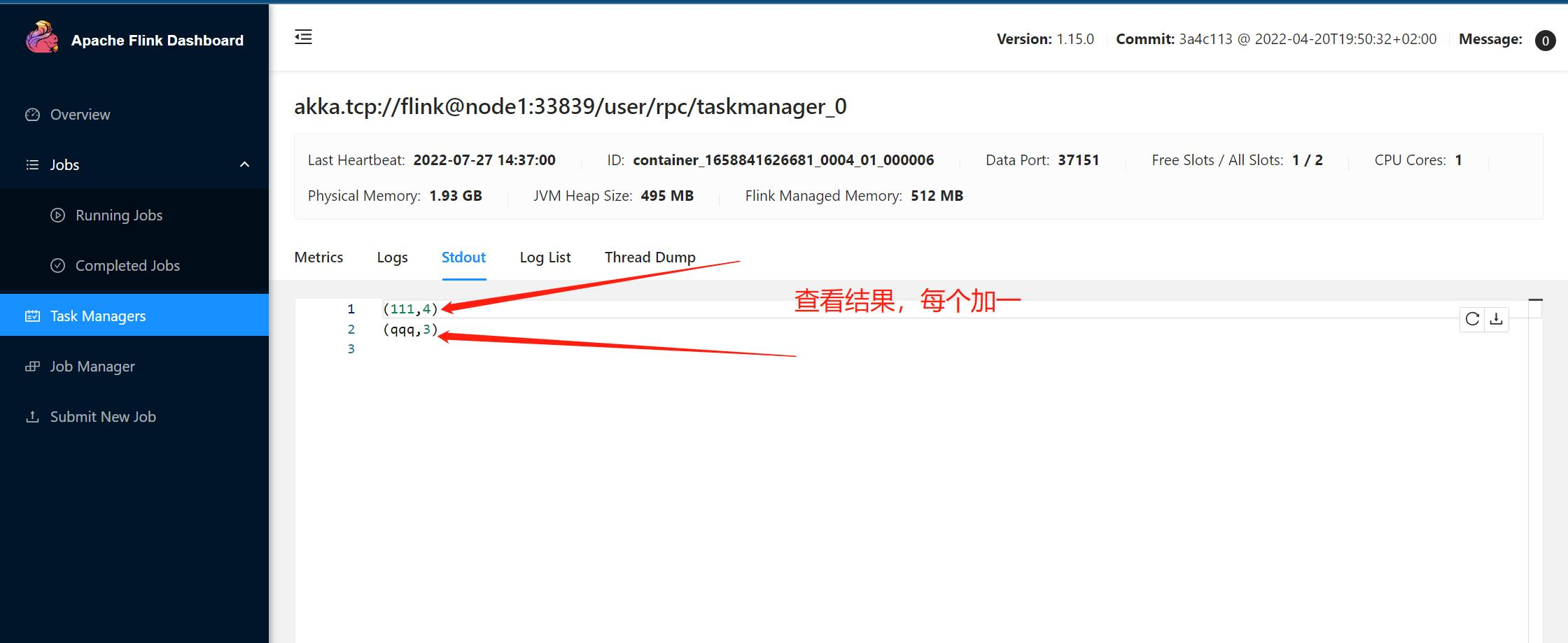
第二次查看结果:
valueState
package com.wt.flink.core
import org.apache.flink.api.common.functions.{RichMapFunction, RuntimeContext}
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup
import org.apache.flink.streaming.api.scala._
object Demo13ValueState {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
/**
* 打开flink的checkpoint
*
*/
// 每 1000ms 开始一次 checkpoint
env.enableCheckpointing(5000)
// 高级选项:
// 设置模式为精确一次 (这是默认值)
//EXACTLY_ONCE: 唯一一次
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// 确认 checkpoints 之间的时间会进行 500 ms
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
// Checkpoint 必须在一分钟内完成,否则就会被抛弃
env.getCheckpointConfig.setCheckpointTimeout(60000)
// 允许两个连续的 checkpoint 错误
env.getCheckpointConfig.setTolerableCheckpointFailureNumber(2)
// 同一时间只允许一个 checkpoint 进行
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
// 使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留
//RETAIN_ON_CANCELLATION: 当任务取消时保留checkpoint
env.getCheckpointConfig.setExternalizedCheckpointCleanup(
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
/**
* 需要设置flink checkpoint保存状态的位置
*
*/
env.setStateBackend(new HashMapStateBackend())
//将状态保存到hdfs中
env.getCheckpointConfig.setCheckpointStorage("hdfs://master:9000/flink/checkpoint")
val linesDS: DataStream[String] = env.socketTextStream("master", 8888)
val wordsDS: DataStream[String] = linesDS.flatMap(_.split('<'))
val keyByDS: KeyedStream[String, String] = wordsDS.keyBy(wrod => wrod)
val countDS: DataStream[(String, Int)] = keyByDS.map(new RichMapFunction[String, (String, Int)]() {
/**
* ValueState: 单值状态,为每一个key再状态中保存一个值
* 状态:是flink中特殊的变量,会被checkpoint保存到hdfs中,如果任务执行失败可以恢复之前的计算结果
*/
var valueState: ValueState[Int] = _
/**
* open:再map之前执行,每一个task中只执行一次
* flink的状态需要先再open中定义
* 态需:用于保存之前结果的变量,和普通变量的区别,状态会被checkpoint持久化到到hdfs中
*
*/
override def open(parameters: Configuration): Unit = {
//获取flink的上下文对象
//getRuntimeContext: 是AbstractRichFunction中的一个方法
val context: RuntimeContext = getRuntimeContext
//创建状态的描述对象
//状态描述对象:对状态中保存的数据做一个设置,指定保存数据的类型,初始值
val valueStateDesc = new ValueStateDescriptor[Int]("count", classOf[Int])
//通过状态的描述对象获取一个状态
valueState = context.getState(valueStateDesc)
}
override def map(word: String): (String, Int) = {
//1、获取状态中保存的数据
var count: Int = valueState.value()
//2、累加统计
count += 1
//3、更新状态
valueState.update(count)
//返回单词的数量
(word, count)
}
})
countDS.print()
env.execute()
}
}
求动态的求出每个班级的平均年龄
package com.wt.flink.core
import org.apache.flink.api.common.functions.RuntimeContext
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
object Demo14AvgAge {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
/**
* 实时计算每一个班级的平均年龄
*
*/
val studentDS: DataStream[String] = env.socketTextStream("master", 8888)
//取出班级和学生的年龄
val clazzAndAge: DataStream[(String, Int)] = studentDS.map(line => {
val split: Array[String] = line.split(",")
val clazz: String = split(4)
val age: Int = split(2).toInt
(clazz, age)
})
//按照班级分组
val keyByDS: KeyedStream[(String, Int), String] = clazzAndAge.keyBy(_._1)
//计算平均年龄
//flink的状态可以在任务算子中使用,map.flatMap,fliter process都可以
val avgAgeDS: DataStream[(String, Double)] = keyByDS
.process(new KeyedProcessFunction[String, (String, Int), (String, Double)] {
override def open(parameters: Configuration): Unit = {
/**
* 定义两个状态来保存总人数和总的年龄
*
*/
val context: RuntimeContext = getRuntimeContext
//总人数状态的描述对象
val sumNumDesc = new ValueStateDescriptor[Int]("sumNum", classOf[Int])
//总的年龄的描述对象
val sumAgeDesc = new ValueStateDescriptor[Int]("sumAge", classOf[Int])
sumNumState = context.getState(sumNumDesc)
sumAgeState = context.getState(sumAgeDesc)
}
//保存总的人数的状态
var sumNumState: ValueState[Int] = _
//保存总的年龄的状态
var sumAgeState: ValueState[Int] = _
override def processElement(kv: (String, Int),
ctx: KeyedProcessFunction[String, (String, Int), (String, Double)]#Context,
out: Collector[(String, Double)]): Unit = {
val clazz: String = kv._1
val age: Int = kv._2
//获取之前的总的人数和总的年龄
var sumNum: Int = sumNumState.value()
//人数累加
sumNum += 1
//更新状态
sumNumState.update(sumNum)
var sumAge: Int = sumAgeState.value()
//累加
sumAge += age
//更新状态
sumAgeState.update(sumAge)
//季孙平均年龄
val avgAge: Double = sumAge.toDouble / sumNum
//将数据发送到下游
out.collect((clazz, avgAge))
}
})
avgAgeDS.print()
env.execute()
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号