

Hbase-day02_Hbase shell(进阶)
HBase学习(二)
一、Hbase shell
1、Region信息观察
创建表指定命名空间
在创建表的时候可以选择创建到bigdata17这个namespace中,如何实现呢?
使用这种格式即可:‘命名空间名称:表名’
针对default这个命名空间,在使用的时候可以省略不写
create 'bigdata17:t1','info','level'
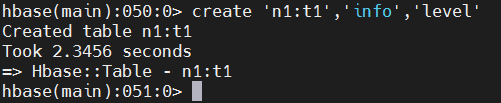
此时使用list查看所有的表
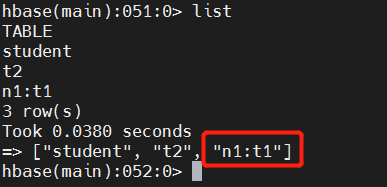
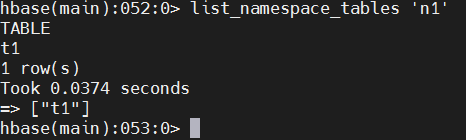
如果只想查看bigdata17这个命名空间中的表,如何实现呢?
可以使用命令list_namespace_tables
list_namespace_tables 'n1'
查看region中的某列簇数据
hbase hfile -p -f /hbase/data/default/tbl_user/92994712513a45baaa12b72117dda5e5/info/d84e2013791845968917d876e2b438a5
1.1 查看表的所有region
list_regions '表名'

1.2 强制将表切分出来一个region
split '表名','行键'

但是在页面上可以看到三个:过一会会自动的把原来的删除
1.2 查看某一行在哪个region中
locate_region '表名','行键'

可以hbase hfile -p -f xxxx 查看一下
画图带同学理解
2、预分region解决热点问题
row设计的一个关键点是查询维度
(在建表的时候根据具体的查询业务 设计rowkey 预拆分)
在默认的拆分策略中 ,region的大小达到一定的阈值以后才会进行拆分,并且拆分的region在同一个regionserver中 ,只有达到负载均衡的时机时才会进行region重分配!并且开始如果有大量的数据进行插入操作,那么并发就会集中在单个RS中, 形成热点问题,所以如果有并发插入的时候尽量避免热点问题 ,应当预划分 Region的rowkeyRange范围 ,在建表的时候就指定预region范围
查看命令使用(指定4个切割点,就会有5个region)
help 'create'
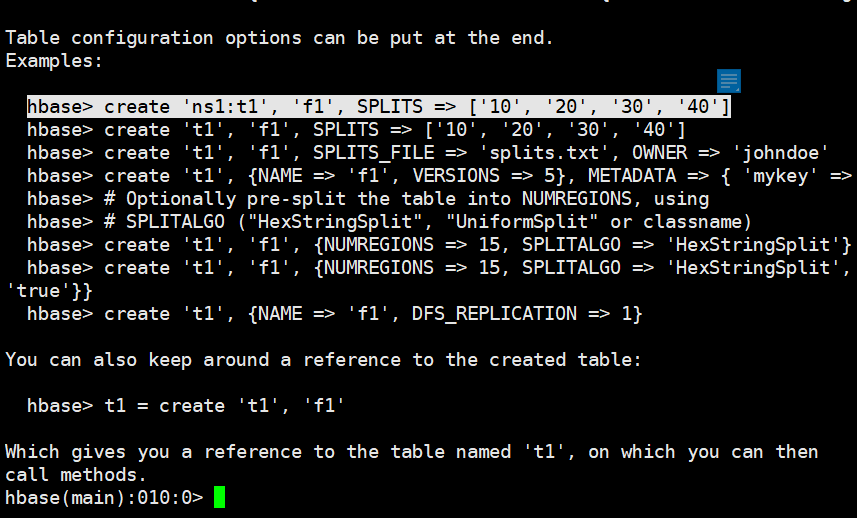
create 'tb_split','cf',SPLITS => ['e','h','l','r']
list_regions 'tb_split'

添加数据试试
put 'tb_split','c001','cf:name','first'
put 'tb_split','f001','cf:name','second'
put 'tb_split','z001','cf:name','last'
hbase hfile -p --f xxxx 查看数据
如果没有数据,因为数据还在内存中,需要手动刷新内存到HDFS中,以HFile的形式存储
3、总结(写一个文档总结回顾)
hbase
分布式数据库,可以存储海量的数据,并发的问题
数据在底层是以列式存储的【方便压缩,查询速度快】
namespace :hbase中是没有数据库概念的,只有命名空间进行对表的管理
create namespace '自定义命名空间名字'
表 用来组织数据的一种基本的结构对象 create 'ns:tb_name','cf'
列簇:在建表的时候,至少指定一个列簇 Column Family
Fileds 列 属性
Cell 确定一个属性值【表名,行键,列簇,属性名,时间戳】---> 值
行键 rowkey 64K 非常关键
1) 确定唯一一行
2)行键 hashMap <name,User> liyi----->index值---->User
3) 排序的 字典顺序
4)一行数据几乎都是存储在一起的
hbase仅只能通过行键快速查询数据
---------------------------------------------------------------------------
HMaster 主节点 zookeeper master 备用的
HRegionServer 用来管理region的,当region达到一定阈值的时候,开始切分两个几乎等大的region(与之前的region在regionserver上),然后当region数量达到一定值的时候,由HMaster对region做负载均衡。
Region 表的行范围数据,对表进行横向切块
----------------------------------------------------------------------------
start-hbase.sh
jps
hbase shell 交互式的客户端
help
version
whoami
-----------------------------------------------------------------------------
DDL
create 'tb_name','cf',{NAME=>'cf2',VERSIONS=>3}
create 'pre_region_tb','cf1','cf2',SPLITS=>['d','m'] 预分3个region出来
put 'tb_name','rowkey','cf2:name','huangxain'
put 'tb_name','rowkey','cf2:name','liyi'
put 'tb_name','rowkey','cf2:name','zhangyongfeng'
scan 'tb_name'
alter 添加修改删除列簇
disable '表名'
disable_all 'tb.*'
enable
drop
drop_all
list_regions '表名' 查看表的region信息
locate_region '表名','行键' 查看某一行在哪一个region中
split '表名','行键(切割点)' 上一个region不包含切割点的
flush '表名' 将regionserver内存中的数据以hfile的形式写到HDFS中
命名空间/表/region/列簇/文件
tb_name 数据---> 行
region 行范围数据
1) 手动split flush
2) 建表的时候,预分region,达到阈值自动写入到HDFS中,避免很多小文件
4、日志查看
演示不启动hdfs 就启动hbase
日志目录:
/usr/local/soft/hbase-1.7.1/logs
start-all.sh发现HMaster没启动,hbase shell客户端也可以正常访问
再启动hbase就好了
5、scan进阶使用
查看所有的命名空间
list_namespace
查看某个命名空间下的所有表
list_namespace_tables 'default'
修改命名空间,设置一个属性
alter_namespace 'bigdata17',{METHOD=>'set','author'=>'wyh'}
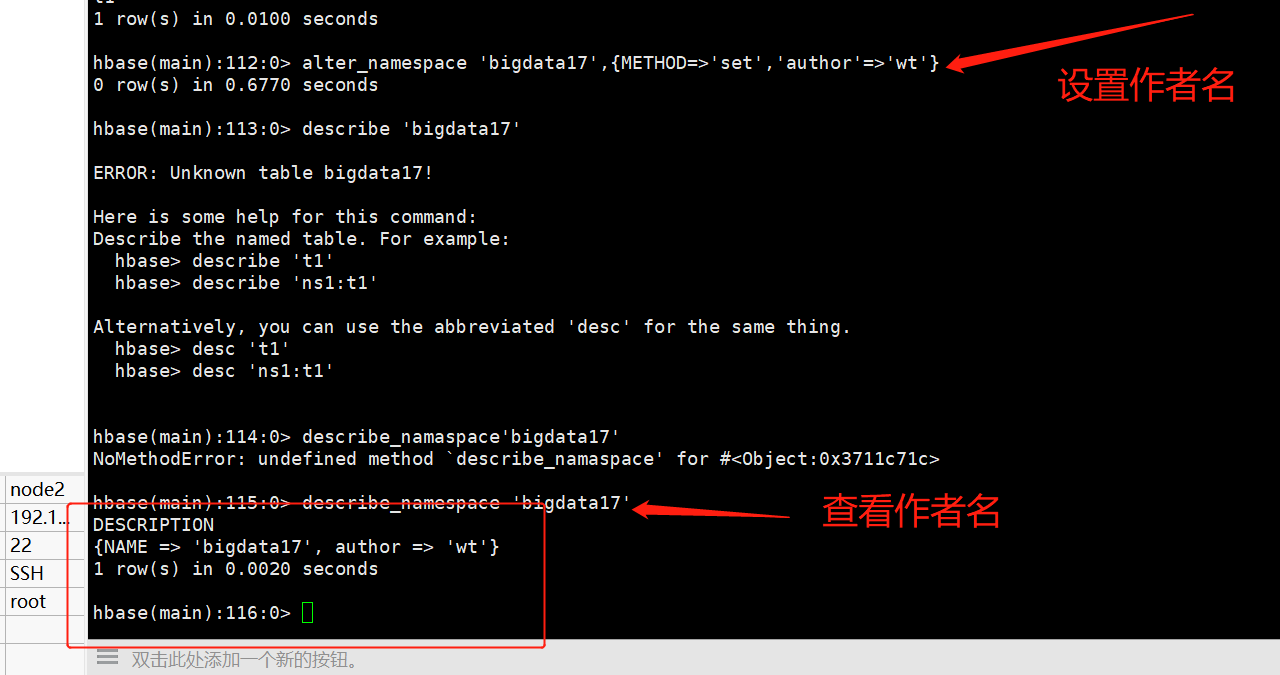
查看命名空间属性
describe_namespace 'bigdata17'
删除一个属性
alter_namespace 'bigdata17',{METHOD=>'unset', NAME=>'author'}
删除一个命名空间
drop_namespace 'bigdata17'
创建一张表
create 'teacher','cf'
添加数据
put 'teacher','tid0001','cf:tid',1
put 'teacher','tid0002','cf:tid',2
put 'teacher','tid0003','cf:tid',3
put 'teacher','tid0004','cf:tid',4
put 'teacher','tid0005','cf:tid',5
put 'teacher','tid0006','cf:tid',6
显示三行数据
scan 'teacher',{LIMIT=>3}
put 'teacher','tid00001','cf:name','wyh'
scan 'teacher',{LIMIT=>3}
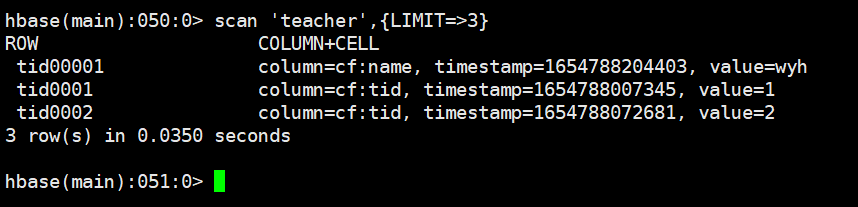
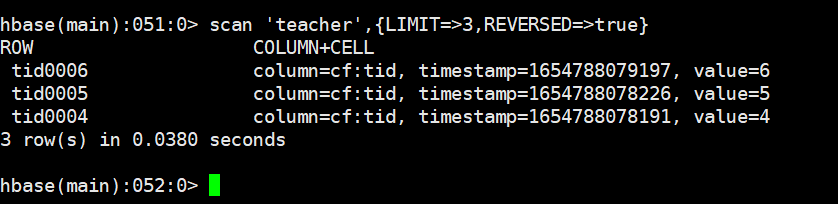
从后查三行
scan 'teacher',{LIMIT=>3,REVERSED=>true}
查看包含指定列的行
scan 'teacher',{LIMIT=>3,COLUMNS=>['cf:name']}

简化写法:
scan 'teacher',LIMIT=>3
在已有的值后面追加值
append 'teacher','tid0006','cf:name','123'
6、get进阶使用
简单使用,获取某一行数据
get 'teacher','tid0001'
获取某一行的某个列簇
get 'teacher','tid0001','cf'
获取某一行的某一列(属性 )
get 'teacher','tid0001','cf:name'
可以新增一个列簇数据测试
查看历史版本
1、修改表可以存储多个版本
alter 'teacher',NAME=>'cf',VERSIONS=>3
2、put四次相同rowkey和列的数据
put 'teacher','tid0001','cf:name','WT1'
put 'teacher','tid0001','cf:name','WT2'
put 'teacher','tid0001','cf:name','WT3'
put 'teacher','tid0001','cf:name','WT4'
3、查看历史数据,默认是最新的
get 'teacher','tid0001',{COLUMN=>'cf:name',VERSIONS=>2}
修改列簇的过期时间 TTL单位是秒,这个时间是与插入的时间比较,而不是现在开始60s
alter 'teacher',{NAME=>'cf2',TTL=>'60'}
7、插入时间指定时间戳
put 'teacher','tid0007','cf2:job','bigdata17',1654845442790
画图理解这个操作在实际生产的作用
8、delete(只能删除一个单元格,不能删除列簇)
删除某一列
delete 'teacher','tid0004','cf:tid'
9、deleteall(删除不了某个列簇,但是可以删除多个单元格)
删除一行,如果不指定类簇,删除的是一行中的所有列簇
deleteall 'teacher','tid0006'
删除单元格
deleteall 'teacher','tid0006','cf:name','cf2:job'
10、incr和counter
统计表有多少行(统计的是行键的个数)
count 'teacher'
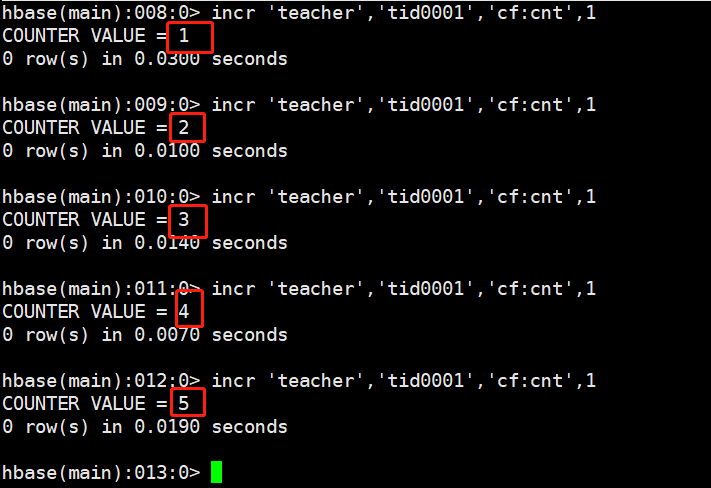
新建一个自增的一列
incr 'teacher','tid0001','cf:cnt',1
每操作一次,自增1
incr 'teacher','tid0001','cf:cnt',1
incr 'teacher','tid0001','cf:cnt',10
incr 'teacher','tid0001','cf:cnt',100
配合counter取出数据,只能去incr字段
get_counter 'teacher','tid0001','cf:cnt'
11、获取region的分割点,清除数据,快照
获取region的分割点
get_splits 'tb_split'
清除表数据
truncate 'teacher'
拍摄快照
snapshot 'tb_split','tb_split_20220610'
列出所有快照
list_table_snapshots 'tb_split'
再添加一些数据
put 'tb_split','a001','cf:name','wyh'
恢复快照(先禁用)
disable 'tb_split'
restore_snapshot 'tb_split_20220610'
enable 'tb_split'
12 修饰词
1、修饰词
# 语法
scan '表名', {COLUMNS => [ '列族名1:列名1', '列族名1:列名2', ...]}
# 示例
scan 'tbl_user', {COLUMNS => [ 'info:id', 'info:age']}
2、TIMESTAMP 指定时间戳
# 语法
scan '表名',{TIMERANGE=>[timestamp1, timestamp2]}
# 示例
scan 'tbl_user',{TIMERANGE=>[1551938004321, 1551938036450]}
3、VERSIONS
默认情况下一个列只能存储一个数据,后面如果修改数据就会将原来的覆盖掉,可以通过指定VERSIONS时HBase一列能存储多个值。
create 'tbl_test', 'columnFamily1'
describe 'tbl_test'
# 修改列族版本号
alter 'tbl_test', { NAME=>'columnFamily1', VERSIONS=>3 }
put 'tbl_test', 'rowKey1', 'columnFamily1:column1', 'value1'
put 'tbl_test', 'rowKey1', 'columnFamily1:column1', 'value2'
put 'tbl_test', 'rowKey1', 'columnFamily1:column1', 'value3'
# 默认返回最新的一条数据
get 'tbl_test','rowKey1','columnFamily1:column1'
# 返回3个
get 'tbl_test','rowKey1',{COLUMN=>'columnFamily1:column1', VERSIONS=>3}
# 返回2个
get 'tbl_test','rowKey1',{COLUMN=>'columnFamily1:column1', VERSIONS=>2}
4、STARTROW
ROWKEY起始行。会先根据这个key定位到region,再向后扫描
# 语法
scan '表名', { STARTROW => '行键名'}
# 示例
scan 'tbl_user', { STARTROW => 'vbirdbest'}
5、STOPROW :截止到STOPROW行,STOPROW行之前的数据,不包括STOPROW这行数据
# 语法
scan '表名', { STOPROW => '行键名'}
# 示例
scan 'tbl_user', { STOPROW => 'xiaoming'}
6、LIMIT 返回的行数
# 语法
scan '表名', { LIMIT => 行数}
# 示例
scan 'tbl_user', { LIMIT => 2 }
13 FILTER条件过滤器
过滤器之间可以使用AND、OR连接多个过滤器。
1、ValueFilter 值过滤器
# 语法:binary 等于某个值
scan '', FILTER=>"ValueFilter(=,'binary:')"
# 语法 substring:包含某个值
scan '表名', FILTER=>"ValueFilter(=,'substring:列值')"
# 示例
scan 'tbl_user', FILTER=>"ValueFilter(=, 'binary:26')"
scan 'tbl_user', FILTER=>"ValueFilter(=, 'substring:6')"
2、ColumnPrefixFilter 列名前缀过滤器
# 语法 substring:包含某个值
scan '表名', FILTER=>"ColumnPrefixFilter('列名前缀')"
# 示例
scan 'tbl_user', FILTER=>"ColumnPrefixFilter('birth')"
# 通过括号、AND和OR的条件组合多个过滤器
scan 'tbl_user', FILTER=>"ColumnPrefixFilter('birth') AND ValueFilter(=,'substring:26')"
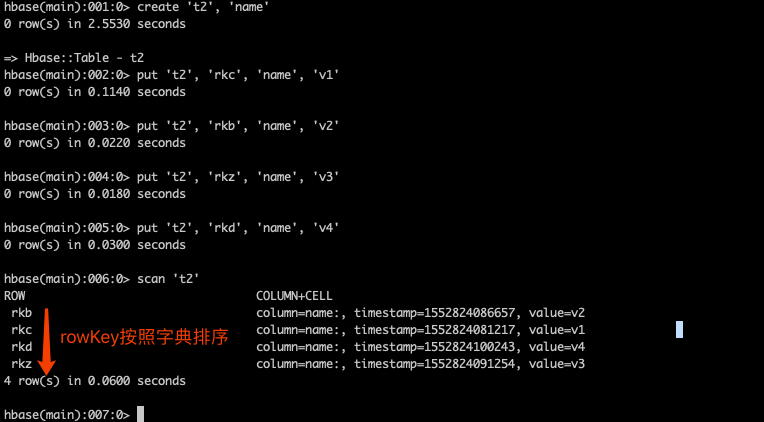
3、rowKey字典排序
Table中的所有行都是按照row key的字典排序的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号