操作系统导论习题解答(22. Swapping: Policies)
Beyond Physical Memory: Policies
对于OS的replacement policy,如何决定哪个(些)page(s)应该被移出内存是非常重要的,弄不好就会严重影响性能。当然的,为了避免极端情况下的行为发生,OS还包括一些调整措施。
1. Cache Management
在讨论策略之前,我们可以让主存保留一部分pages,这样就形成了cache。
对于每个program的cache hit和cache miss,average memory access time(AMAT)有如下计算形式:
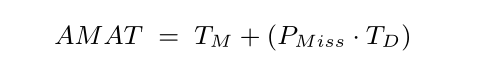
上式TM = 访问内存所需时间,TD = 访问磁盘所需时间,PMiss = 缓存中找不到数据的概率(通常我们用cache miss的概率代替)。
2. The Optimal Replacement Policy
这种方法非常简单:如果必须要扔掉一些page,为什么不扔掉那些最远的page呢?
既然总要有人当FW,那为什么不能是你呢?(滑稽)
下图所示:

由于现在无法预料以后的计算机会如何发展,故而该策略只能用来进行对比。
3. A Simple Policy: FIFO
一图以言之:

该策略无法确定page的重要性,即使序号为0的page需要被访问多次,但是FIFO仍然将其踢出去。
4. Another Simple Policy: Random
话不多说,上图:

上图只是随机策略的一种情况而已,随机策略就和名字一样,随机踢出page,正所谓生死有命富贵在天。
下图是10000次实验:

5. Using History: LRU
LFU: Least-Frequently-Used
LRU: Least-Recently-Used
MFU: Frequently-Used
MRU: Most-Recently-Used
上述策略,“人如其名”,知道名字的意思就知道策略怎么执行。
图片来啦:

6. Workload Examples
下图是没有局限性:

从上图可以得出一些结论:
- 当工作负载没有局限性时,使用哪种策略都无关紧要。
- 当缓存足够大以适合整个工作负载时,使用哪种策略也无关紧要。
- 当所有需要调用的page都放入高速缓存中时,所有策略的cache hit都是100%。
- 最佳策略比现有实际策略都要好,当然未来可期。
下图为“二八法则”:

下图是“顺序循环”:

7. Implementing Historical Algorithms
要实现上述所说的策略,需要良好的数据结构与算法和硬件支持。
特别要说的就是LRU策略,如果page数量非常大,我们不可能遍历所有page以便找出最近很少使用的page进行替换。
8. Approximating LRU
对于上述问题,近似LRU方法从计算开销的角度来看更可行,这也是许多现代操作系统所做的。这个方法需要 use bit 形式的一些硬件支持。
那么OS如何使用use bit来近似LRU呢?
有许多方法可以实现,最常用的方法就是 clock algorithm 。
该方法的实现:把所有page放入到一个循环列表中,有个clock hand指向一些特别的page开始对列表进行循环,当替换策略发生时,检查clock hand当前指向的page的use bit是否为1。如果为1,表明该page最近使用不能替换,clock hand将其use bit从1变成0,然后指向下一个page;如果下一页page的use bit为0,那么对该page进行替换。
当然不止这一种方法,该方法是早期的一种算法,取得了成功,并且具有不重复扫描所有内存以查找未使用page的优势。

9. Considering Dirty Pages
对于上述的clock算法可以进行以下改进。
我们知道对于每个page,都有一个dirty bit来表示其是否有数据存在过。如果替换的page中有数据存在,那么如果该page又要被调用,性能开销就增大了。所以,一般而言,都是替换哪些没有数据存在过的page。
简而言之,就是更改clock算法,使其扫描到的未使用又干净的page首先被踢出。
10. Other VM Policies
VM不是仅仅只有page replacement策略,只是它是VM中最重要的。还有其他方面的策略,例如OS还要决定什么时候page被调用到内存中,什么时候page写入到磁盘中。
11. Thrashing
最后,要处理一些问题:
- 内存不足时,OS需要执行什么操作?
- 如果运行中的进程对内存的需求超过了可用的物理内存,OS需要执行什么操作?
对于上述问题,OS需要不断增加page的数量,这种情况叫做thrashing。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号