python利用PyPDF2快速检索pdf名单,告别肉眼搜索
 日常生活和工作中,常遇到处理 PDF 文件的难题,比如比赛获奖名单以 PDF 格式呈现,查找自己名字时需手动滚动页面;日常工作中从大量数据里逐条查找所需信息等。不仅效率低,还易漏掉关键信息。不过,作者分享了一种利用 Python 的 PyPDF2 库的方法,该方法既能解放双眼,又能确保不遗漏所需数据。
日常生活和工作中,常遇到处理 PDF 文件的难题,比如比赛获奖名单以 PDF 格式呈现,查找自己名字时需手动滚动页面;日常工作中从大量数据里逐条查找所需信息等。不仅效率低,还易漏掉关键信息。不过,作者分享了一种利用 Python 的 PyPDF2 库的方法,该方法既能解放双眼,又能确保不遗漏所需数据。
问题描述:
大家有没有在日常生活中碰到这样的问题:
●当一个比赛公布获奖名单时,pdf格式的获奖名单上有上万条人名,手指头在滚动条上机械地滑动,眼睛瞪得像铜铃,在密密麻麻的名单上从第一页翻到最后一页来查找自己的名字;
●亦或是在日常工作中,我们想要从数据海洋中查找我们想要的数据时,从上万条数据中一条一条的找,不仅眼睛酸痛效率还低,时常会漏掉一些关键信息。
下面分享一下我刚刚学习到的方法,既能释放双眼,并且不会漏掉任何一个我们想要的数据:
本文就是利用了python中一个非常好用的库:PyPDF2
PyPDF2 是一个用 Python 编写的开源库,它可以帮助开发者通过编程的方式来操作 PDF 文件。这个库使用纯 Python实现,依赖于第三方包 PyCryptodome 进行加密功能的支持。
它支持 Python 2 和 Python 3,并且可以独立于任何
PDF 阅读器或编辑器使用,这意味着你无需额外安装 Adobe Acrobat 等软件,就能在 Python 代码里对 PDF文件进行各种操作
详细内容请点击PyPDF2官方网站:PyPDF2
开始复现
最近,我参加了某比赛,公众号上发布了pdf获奖名单,下载打开后,二百多页几千条数据,于是我花了几乎几十分钟的时间才找到自己。事后我想找一个方便迅速的方法来一键检索我想要得到的信息,于是就寻觅到了PyPDF2:
这次复现过程就以pdf文件为例:
a.先下载一下这个python库,加上清华源下载速度快得多了:
pip install PyPDF2 -i https://pypi.tuna.tsinghua.edu.cn/simple
b. 编写代码:
首先这个代码,我打算分两块去写,也就是构造两个函数,
一个函数(read_pdf())读取并处理pdf文件,一个函数(check_name())实行具体的操作(用户通过输入自己的姓名和院校来检索自己是否获奖)。最后通过主程序块运行。
b.1).读取并处理pdf文件:
读取指定路径下的 PDF 文件,并将文件中每一页的文本按行分割后存储在一个列表里,最后返回该列表。
def read_pdf():
"""读取pdf文件"""
try:
with open(r"D:\my_spider\winning_list.pdf", 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
page_text = pdf_reader.pages
results = []
for p in range(len(page_text)):
text = page_text[p].extract_text()
text_list = text.split('\n')
results.extend(text_list)
return results
except Exception as e:
print(f'出现{e}错误!!!')
with open(r"D:\my_spider\winning_list.pdf", 'rb') as file: # 改成你自己的路径
1.借助 open() 函数打开一个名为winning_list的文件。
●'rb' 是文件打开模式,其中 'r' 代表以只读模式打开文件,'b' 表示以二进制模式打开。由于 PDF 文件属于二进制文件,所以需要使用二进制模式来打开。
●with语句会在代码块结束时自动关闭文件,这样能避免手动管理文件的关闭操作,降低资源泄漏的风险。
pdf_reader = PyPDF2.PdfReader(file)
●此代码行创建了一个 PyPDF2.PdfReader 类的实例 pdf_reader,并将打开的文件对象 file 作为参数传入。
●PdfReader 对象用于读取 PDF 文件的内容。
page_text = pdf_reader.pages
获取 PDF 文件的所有页面。
results = []
for p in range(len(page_text)):
text = page_text[p].extract_text()
text_list = text.split('\n')
results.extend(text_list)
为什么要写成列表的形式,因为text返回的内容是字符串,所以这个列表表示遍历pdf的每一页内容,并逐页将数据以列表的形式存储起来,方便之后检索。
text = page_text[p].extract_text()
用到了extract_text()方法来提取当前页的文本内容。
text返回的内容(pdf某页):

可以看到text返回的内容是一行一行的字符串。
text_list = text.split('\n')
将当前页的文本按换行符分割成多个字符串。
results.extend(text_list)
把分割后的字符串追加到 results 列表中。
b.2).实现检索功能:
依据用户输入的姓名和院校信息,在 PDF 文件读取的内容中查找匹配的条目,并给出相应的提示信息。
def check_name(name, school):
print("正在搜索中......")
original = read_pdf()
filtered_list = []
for item in original:
if f'{name}' in item and f'{school}' in item:
filtered_list.append(item)
if len(filtered_list) == 0:
print(f"\t😰😰😰\n很遗憾,{name}({school}), 未在名单上寻得您的名字。。。")
else:
print(f'\t✅✅✅\n 祝贺你,{name}({school})!!!, 我们在名单中发现了你,下面是您的具体信息:\n {filtered_list} ')
original = read_pdf()
调用 read_pdf 函数,读取 PDF 文件的内容。
filtered_list = []
初始化一个空列表,用于存储匹配的条目。
for item in original
遍历读取的所有文本行。
if f'{name}' in item and f'{school}' in item
判断当前文本行是否同时包含用户输入的姓名和院校信息。
filtered_list.append(item)
若匹配,则将该文本行添加到 filtered_list 列表中。
if len(filtered_list) == 0
判断 filtered_list 列表是否为空:
●若为空,打印未找到的提示信息,说明没有获奖
●若不为空,打印找到的提示信息,说明获奖,并显示匹配的具体条目。
c.主程序块:
if __name__ == '__main__':
name = input(f"\t欢迎您!!!\n请输入您的姓名:")
school = input(f"请输入您的院校:")
check_name(name, school)
即通过input()方法来获取两个变量:用户的姓名和院校,获取之后将这两个变量传递给check_name()方法来检索。
源代码:
import PyPDF2
def read_pdf():
"""读取pdf文件"""
try:
with open(r"D:\my_spider\winning_list.pdf", 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
page_text = pdf_reader.pages
results = []
for p in range(len(page_text)):
text = page_text[p].extract_text()
text_list = text.split('\n')
results.extend(text_list)
return results
except Exception as e:
print(f'出现{e}错误!!!')
def check_name(name, school):
print("正在搜索中......")
original = read_pdf()
filtered_list = []
for item in original:
if f'{name}' in item and f'{school}' in item:
filtered_list.append(item)
if len(filtered_list) == 0:
print(f"\t😰😰😰\n很遗憾,{name}({school}), 未在名单上寻得您的名字。。。")
else:
print(f'\t✅✅✅\n 祝贺你,{name}({school})!!!, 我们在名单中发现了你,下面是您的具体信息:\n {filtered_list} ')
if __name__ == '__main__':
name = input(f"\t欢迎您!!!\n请输入您的姓名:")
school = input(f"请输入您的院校:")
check_name(name, school)
效果展示:
输入姓名和院校之后可以成功检索到信息:
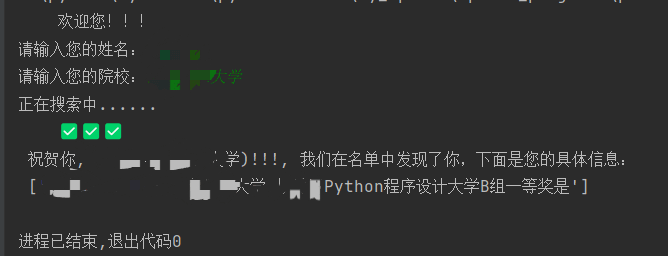
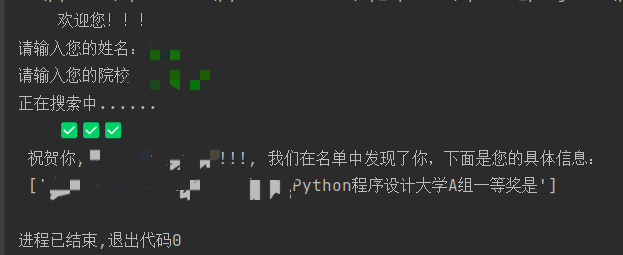
名单中没有的人也会回显:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号