如何使用vLLM部署通义千问大模型Qwen?使用docker的Python基础镜像部署大模型
1. 准备环境
在开始之前,请确保您已经安装了Docker(不适用docker可以不安装)和CUDA,以及python和pip供下载模型文件。
2. 下载模型
由于网络问题,需要使用huggingface-cli来下载模型。首先安装所需的库。
pip install -U huggingface_hub hf_transfer -i https://mirrors.aliyun.com/pypi/simple设置变量,
export HF_ENDPOINT=https://hf-mirror.com 下载模型,该过程需要较长时间。
huggingface-cli download --resume-download Qwen/Qwen2.5-32B-Instruct-GPTQ-Int4 --local-dir /home/rkty/qwen 参数说明:--resume-download 若出现问题中断下载可以在第二次执行时继续下载
Qwen/Qwen2.5-32B-Instruct-GPTQ-Int4表示你要下载的模型名
--local-dir 表示你要把模型下载到的路径
3. 下载vLLM
vLLM要求python版本在3.9-3.12,不需要额外安装pytorch,下载vllm会自动安装合适版本的依赖。使用pip安装vllm,此过程需要较长时间。
pip install vllm若想要使用docker的python3.10镜像部署,则需要拉取并运行python3.10的容器
docker run --gpus all -it --name vllm-qwen -v /home/rkty/qwen:/workspace/qwen -d -p 9997:8000 --ipc=host python:3.10 参数解释:--gpus all 容器使用所有GPU
--name 设定容器名
-v 映射文件,把刚才下载的模型文件映射到容器内。
-p 映射端口
--ipc=host,容器共享内存,一定要带着。
而后进入容器内pip安装vllm即可。
4. 启动vlLLM
vllm serve /workspace/qwen --served-model-name Qwen/Qwen2.5-32B-Instruct-GPTQ-Int4 --quantization gptq --tensor-parallel-size 4 --max-model-len 32768 --gpu-memory-utilization 0.9 参数说明:--served-model-name 设定模型名
--quantization gptq 我的模型选用的gptq量化模型,若你的模型不是量化模型则不需要携带
--tensor-parallel-size,选择使用几个GPU
--gpu-memory-utilization 0.9 占用90%比例的显存,若显存被其他服务占用则可以降低该值
若要使用特定GPU,则使用nvidia-smi查看GPU的编号,并执行以下命令后再次启动vLLM。
export CUDA_VISIBLE_DEVICES=编号1,编号2 到此为止,vLLM应该启动成功
遇到的错误
1. 报了显存不足的问题,此时要么是你的GPU的显存无法支持你的模型,要么是你让vLLM占用的显存比例太大,而你的显存没有剩下那么多,此时应降低启动时的--gpu-memory-utilization
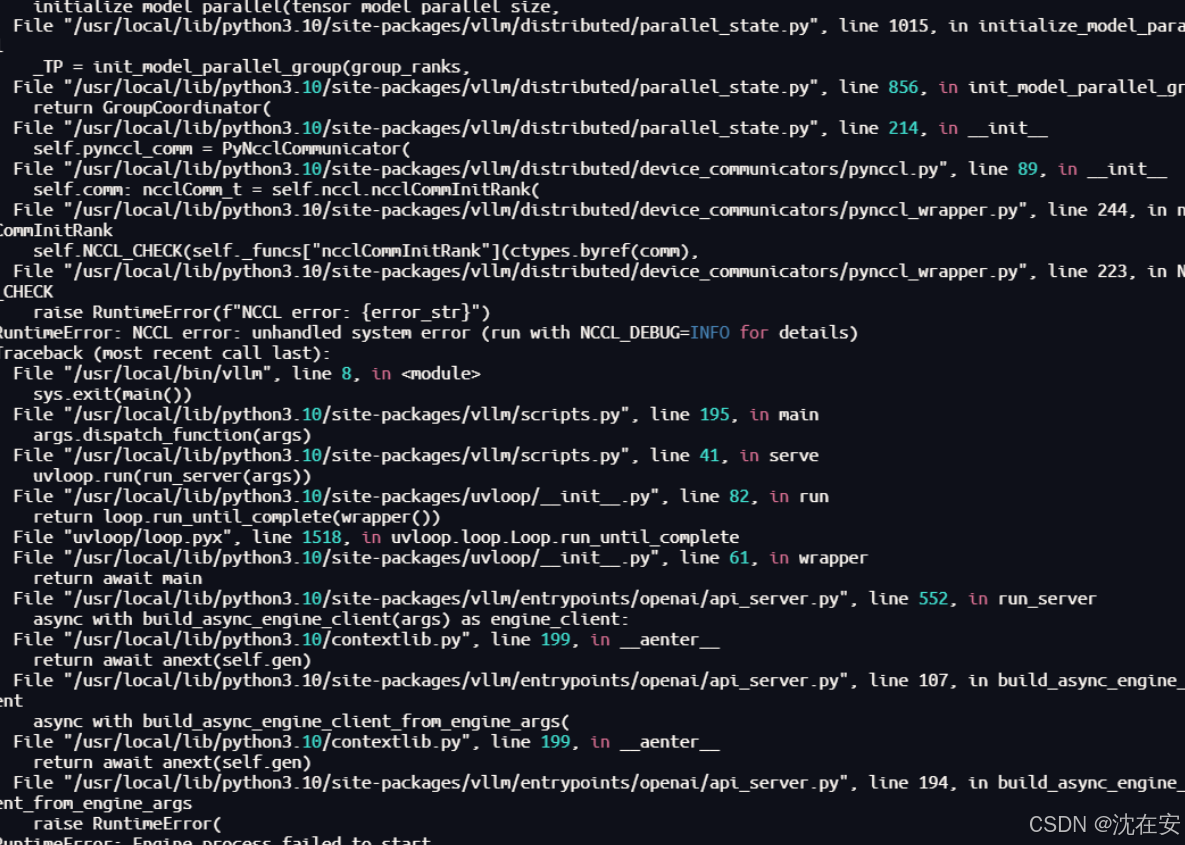
2. docker内共享内存不足的问题,原因是创建容器时没增加--ipc=host,无法满足NCLL的需求。报错如下(一小小部分,重要的没截下来)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号