MySQL读写分离-简单思考
本文图片资源均来自互联网,没有干货,只是提供一种简单的思路。
基础原理
两台MySQL机器一个主,一个从实现数据实时同步比较简单,代码层面无需任何修改,添加一台机器简单配置配置即可,但是MySQL数据库实现读写分离,就有那么点麻烦了。
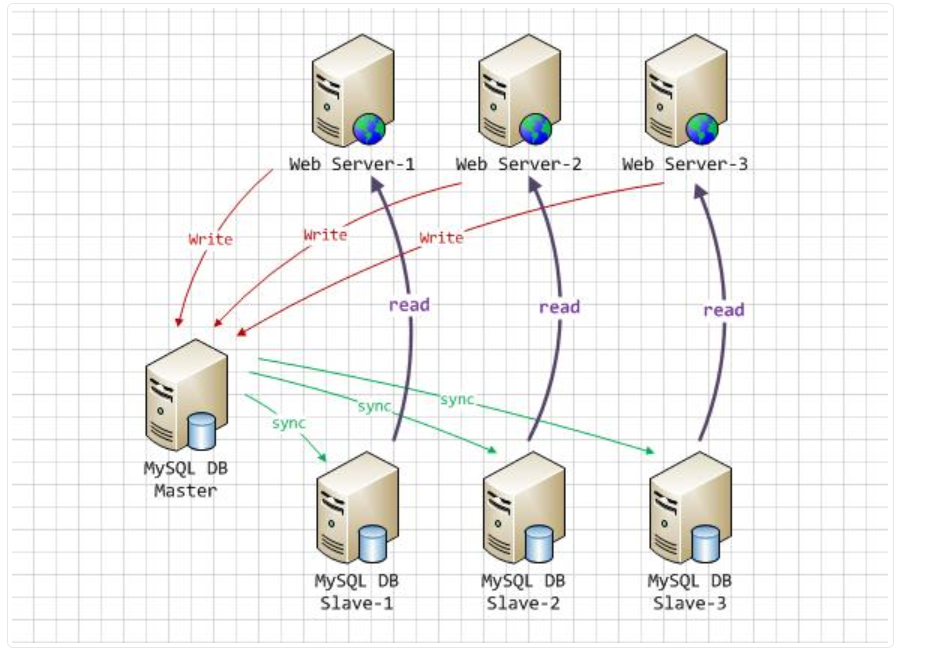
如上面这张图。
1 三台Slave机器通过日志记录的方式,实时同步Master数据库的数据,容易实现。
2 三台WEB机器写入数据时,全都写入到Master数据库里,也容易实现。在上述架构中,主数据库只能有一个,否则容易出现数据不同步问题。
3 最关键的问题在于3台WEB机器需要读数据时,我们的目标是3台WEB机器读数据时从3台Slave机器上读取,而且是负载均衡的形式,3台Slave机器分担读取压力。
有两种方法可以实现数据库读写分离,基于程序代码内部实现和基于中间代理层实现。
改动代码实现,一般可以用一些开发框架,对数据库操作进行路由,即读相关操作路由到Slave集群上去,而写相关操作路由Master数据库机器,显然这种操作主要是由开发来实现,开发和运维有那么点耦合,运维至少还要告知开发哪些IP地址是Slave机器,Slave机器增加或删除都需要通知开发做相关处理。
另外一种方式就是基于中间代理层实现,这就有点相当于WEB前端的负载均衡,但还不太一样,就是另起一台机器,在上面安装数据库代理软件,所有操作数据库的请求不管是读还是写,都先走到这台数据库代理机器上,然后再由数据代理机器往后端抛,写操作抛给Master,读操作负载给Slave集群。如下图:
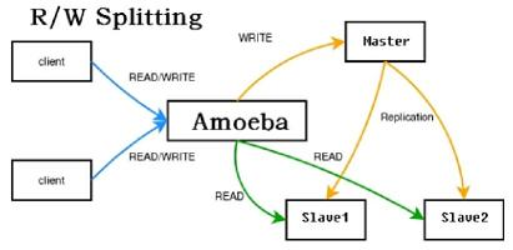
可以看到Amodeba这款软件就充当数据库代理的作用,以此实现读写分离。充当数据库中间代理层可以是成品软件如Amodeba,Atlas,还可也是自己写的lua脚本。
读写分离优秀图
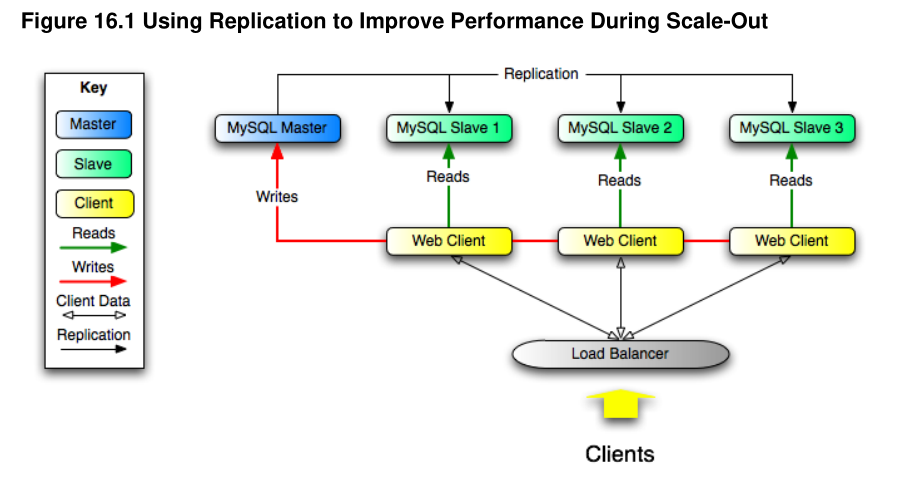
上图来自MySQL官方文旦手册,看到某组织用上图,还打上自己的logo,简直不要脸。
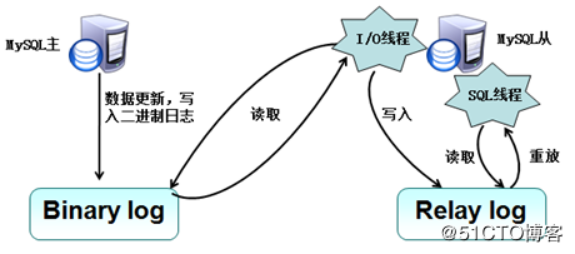
参考链接
http://blog.51cto.com/13557884/2069131
https://blog.csdn.net/anzhen0429/article/details/77014565
http://heylinux.com/archives/1004.html
https://blog.csdn.net/starlh35/article/details/78735510
https://blog.csdn.net/shukebai/article/details/66007638
最后一次更新 20181021

 浙公网安备 33010602011771号
浙公网安备 33010602011771号