
python基础二
1. 基础数据类型
1.1 数字int
记住一个方法就是 bit_length() , 求得对应二进制最小位数
1 i = 5 2 i.bit_length() 3 print( i.bit_length()) # 5 = 101 结果为3
1.2 字符串str
1.2.1 字符串索引和切片
| 切片规则: 顾头不顾尾 |


1 s = 'ABCDRFGHIJK' 2 3 # 索引 4 s1 = s[0] 5 print(s1) 6 7 # ABCD 切片规则: 顾头不顾尾 8 s3 = s[0: 4] 9 print(s3) 10 11 # 全部取出,两种方法 12 s31 = s[0:] 13 print(s31) 14 s32 = s[:] 15 print(s32) 16 17 # K 取最后一位就是 -1, 倒着取就是-1,-2,-3 ··· 18 s4 = s[-1] 19 print(s4) 20 # 取倒数三位 [-3:] 取倒数两位[-2:] 21 s5 = s[-3:] 22 print(s5) 23 24 # 等距跳着取 [首:尾:步长] 等长 25 s6 = s[0::2] 26 print(s6) 27 28 # 倒着取 (仍注意顾头不顾尾) 29 s7 = s[3::-1] 30 print(s7) 31 s8 = s[-1::-1] 32 print(s8)
1.2.2 字符串常用的操作
1 # 字符串的操作 2 3 # 将首字母大写,其余全部小写输出 4 s = 'alexWUsir' 5 s1 = s.capitalize() 6 print(s1) 7 8 # 全大写,全小写 9 s2 = s.upper() 10 s21 = s.lower() 11 print(s2, s21) 12 13 # 大小写翻转 14 s3 = s.swapcase() 15 print(s3) 16 17 # 每个被(特殊字符或数字)隔开的单词首字母大写 18 s = 'alex egon wusir' 19 s4 = s.title() 20 print(s4) 21 22 # 居中,空白填充 23 s = 'alexWUsir' 24 s5 = s.center(20,'-') # (self, width, fillchar=None) 25 print(s5) 26 27 # 公共方法(求字符长度) 28 s = '982kkq二哥' 29 l = len(s) 30 print(l) 31 32 33 # 以什么开头结尾 startwith,endwith 34 s = 'alexWUsir' 35 s7 = s.startswith('alex') 36 s71 = s.startswith('e',2,5) # 也可以在切片内进行判断 37 print(s7,s71) 38 39 # find 通过元素找索引,找不到返回-1 40 # index 通过元素找索引,找不到就会报错 41 s = 'alexWUsir' 42 s8 = s.find('W') 43 print(s8) 44 45 # strip 去前后端的空格,特殊字符,字母··· (前后端同时进行) 46 # rstrip 从左删, lstrip 从右删 47 s = ' alexWUsir ' 48 s9 = s.strip() 49 print(s9) 50 51 s = '***&%*a%lexWusir%' 52 s91 = s.strip('*%') 53 print(s91) 54 55 # 计数 56 s = 'alexaa wusirl' 57 s10 = s.count('a') 58 print(s10) 59 60 # spilt 分割 [str ---> list] 可加参数,按照第几个字符进行分割 61 s = ':alex: wusir: taibai' 62 s11 = s.split('a') 63 print(s11) 64 65 # repalce 替换 (默认全部替换,可添加参数选择替换前几个) 66 s = '大家好我是好我是孩我是子' 67 ss = s.replace('我是','阿拉', 2) 68 print(ss) 69 70 # isdigit() 判断字符是否为数字,返回True/False 71 i = '789' 72 print(i.isdigit()) # True 73 ii = '8hui01s' 74 print(ii.isdigit()) # False
| spilt 分割方法, str --> list |
1 s = ':alex: wusir: taibai' 2 s11 = s.split('a') 3 print(s11) # [':', 'lex: wusir: t', 'ib', 'i'] 4 5 # 可添加参数,按照第几个进行分割 6 s = ':alex: wusir: taibai' 7 s11 = s.split('a', 2) 8 print(s11) # [':', 'lex: wusir: t', 'ibai'] 9 10 s = 'alex wusir taibai' 11 s11 = s.split(' ') 12 print(s11) # ['alex', 'wusir', 'taibai']
1.3 列表 list
列表是python中的基础数据类型之一,而且他里面可以存放各种数据类型比如:
li = [‘alex’,123,Ture,(1,2,3,’wusir’),[1,2,3,’小明’,],{‘name’:’alex’}]
列表相比于字符串,不仅可以储存不同的数据类型,而且可以储存大量数据,而且列表是有序的,有索引值,可切片,方便取值。
1.3.1 增
1 ''' 增加 ''' 2 # 增加 append (没有返回值) 3 li.append('日天') 4 li.append(12) 5 print(li) 6 7 # 插入 insert (插入的位置,内容) 8 li.insert(5,'春哥') 9 print(li) 10 11 # 可迭代插入,分解到最终的元素进行插入 (123无法加入,因为不可分,只能插入'123') 12 li.extend('二哥') 13 print(li)
1.3.2 删
''' 删除 4个方法 ''' # pop 安索引删除元素,有返回值,返回被删除的元素 li = ['alex',[1,2,3,],'wusir','egon','女神','taibai'] li.pop(1) name = li.pop() # 默认删除最后一个 print(li,name ) # remove 按元素去删除 li.remove('egon') print(li) # clear 清空 ,列表保留 li.clear() print(li) # del 从内存中清除列表 del li # 切片删除 del li[0:2] # 顾头不顾尾 print(li)
1.3.3 改
''' 修改 ''' li[0] = '男神' #直接覆盖 li[0] = [1,2,3] li[0:2] = '云姐pl' # 取相应切片个数替代后,其余按迭代方法添加(划分到元素) # ['云', '姐', 'p', 'l', 'wusir', 'egon', '女神', 'taibai'] li[0:3] = [1,2,3,'春哥','咸鱼哥'] # [1, 2, 3, '春哥', '县区', 'egon', '女神', 'taibai'] print(li)
1.3.4 查
''' 查 ''' for i in li: print(i) print(li[0:2])
1.3.5 其他操作
count(数)(方法统计某个元素在列表中出现的次数)。
a = ["q","w","q","r","t","y"] print(a.count("q"))
index(方法用于从列表中找出某个值第一个匹配项的索引位置) (不存在就报错)
a = ["q","w","r","t","y"] print(a.index("r"))
正向排序 & 倒序排序 & 反转(不排序)
# 正向排序 li = [1, 5, 4, 7, 6, 2, 3] li.sort() print(li) # 倒序排序 li.sort(reverse=True) # 将参数设为True print(li) # 反转 (不排序) li.reverse() print(li)
列表的嵌套
# 列表的嵌套 li = ['taibai', '武藤兰', '袁浩', ['alex','egon',89],23] print(li[1][1]) # 例子 name = li[2].replace('浩', '日天') li[2] = name print(li) li[3][0] = li[3][0].upper() print(li)
1.3.6 join 操作, 列表转化为字符串
| join 连接方法 , list --> str |
# join 列表转化成字符串
li = ['alex','wusir','egon','女神','taibai']
s = ''.join(li) # 不会改变li , 得到的结果存在s中
print(s) # 结果:alexwusiregon女神taibai
s = '*'.join(li)
print(s) # 结果:alex*wusir*egon*女神*taibai
1.4 元组 tuple
元组被称为只读列表,即数据可以被查询,但不能被修改,所以,字符串的切片操作同样适用于元组。例:(1,2,3)("a","b","c")
一些重要的信息可以放在里面!
# 儿子不能改,孙子可能可以改 tu = (1,2,3,'alex',[2,3,4],'egon') # 'alex'这一项就不能改,但是[2,3,4]就可以修改
一种用法:
# range 按顺序排列的数字列表,顾头不顾尾 for i in range( 0,100): print(i)
1.5 字典 dict
字典是python中唯一的映射类型,采用键值对(key-value)的形式存储数据。python对key进行哈希函数运算,根据计算的结果决定value的存储地址,所以字典是无序存储的,且key必须是可哈希的。可哈希表示key必须是不可变类型,如:数字、字符串、元组。
|
1.5.1 增
dic1 = {'age': 18, 'name': 'jin', 'sex': 'male'}
dic1['high'] = 185 # 没有键值对,添加 dic1['age'] = 16 # 有键值,覆盖 print(dic1) dic1.setdefault('weight') #如有键值对,不做任何改变,没有才添加。 dic1.setdefault('weight',150) dic1.setdefault('name','哥') print(dic1)
1.5.2 删
print(dic1.pop('age')) # 有返回值,按键去删除 print(dic1.pop('二哥',None)) # 可设置返回值,一般设为None,如果有则直接删除 print(dic1) print(dic1.popitem()) # 随机删除,返回被删的键值对 print(dic1) dic1.clear() # 清空字典
1.5.3 改
update 添加并更新
1 dic = {'name': 'jin', 'age': 18, 'sex': 'male'} 2 dic2 = {'name': 'alex', 'weight': 75} 3 dic2.update(dic) # 在dic2 上添加并更新 4 print(dic) 5 print(dic2)
1.5.4 查
1 dic1 = {'age': 18, 'name': 'jin', 'sex': 'male'} 2 print(dic1.keys(), type(dic1.keys())) 3 print(dic1.values()) 4 print(dic1.items()) # items : 键值对 5 6 for i in dic1: # 打印出全部的键 或 for in dic1.keys(): 7 print(i) 8 9 for i in dic1.values(): # 打印全部的值 10 print(i) 11 12 for i in dic1.items(): 13 print(i) 14 15 for k,v in dic1.items(): # 去掉括号,分别打印出来 16 print(k,v) 17 18 v1 = dic1['name'] 19 print(v1) # 假如没有这个值,报错 20 21 print(dic1.get('name')) # 假如不存在,默认返回nong,或者自定义返回值 22 23 print(dic1.get('name1','没有这个键值'))
1.5.5 嵌套
1 dic = { 2 'name':['alex','wusir','taibai'], 3 'py9':{'time':'1213','learn_mony':19800, 'address':'CBD',}, 4 'age':21, 5 } 6 dic['age'] = 56 7 8 dic['name'].append('ritian') # name中追加'ritian' 9 print(dic) 10 11 dic['name'][1] = dic['name'][1].upper() # 注意要赋值回去 12 print(dic)
1.5.6 字典的循环
1 dic = {"name":"jin","age":18,"sex":"male"}
2 for key in dic:
3 print(key)
4 for item in dic.items():
5 print(item)
6 for key,value in dic.items():
7 print(key,value)
1.6 小知识总结
1.6.1 python 2/3 差别
python 2 |
python 3 |
1.6.2 内容比较问题 --> 引出小数据池概念
= 赋值
==比较值是否相等
is 比较的是内存地址
id( 内容 )
小数据池 --> 为了节省内存
针对数字,字符串
数字的范围 -5 -- 256 ,创建多个变量使用同一内存
字符串: 1, 不能含有特殊字符
2. s*20 还是同一个地址,s*21 以后都是两个地址
剩下的 list dict tuple set 均没有小数据池的概念
1.6 编码问题补充
ascii
A : 00000010 8位一个字节
unicode
A : 00000000 00000000 00000010 00000000 32位 四个字节
中文 :00000000 00000001 00000010 00000110 32位 四个字节
utf - 8
A 0010 0000 8位 一个字节
中文 00000001 00000010 00000110 24位 三个字节
gbk
A 00000110 8位 一个字节
中文 00000010 00000110 16位 两个字节
1,各个编码之间的二进制,是不能互相识别的,会产生乱码
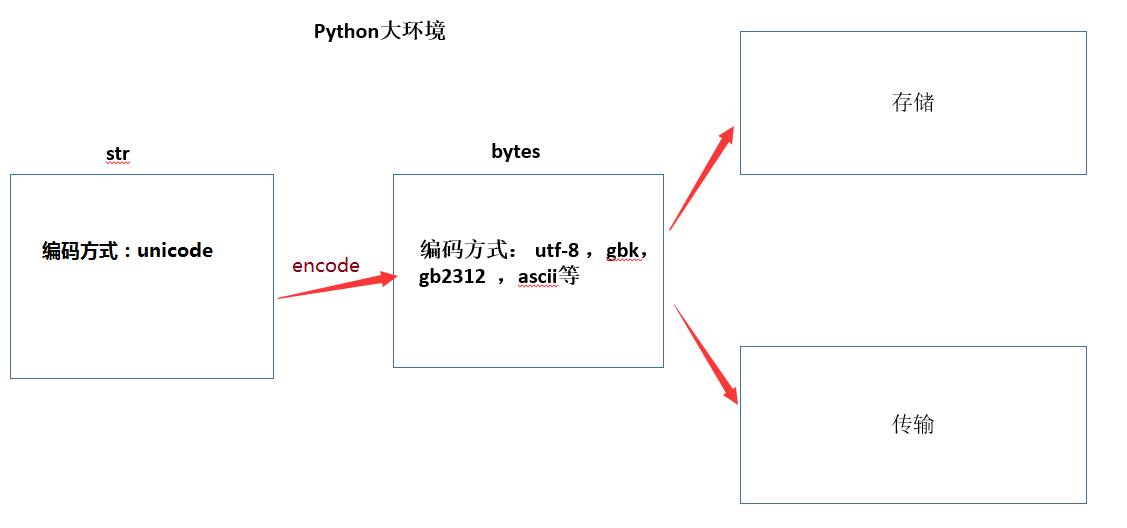
2,文件的储存和传输,不能是unicode(只能是utf - 8,gbk,gb2312,ascii等)
在Python3以后,字符串和bytes类型彻底分开了。字符串是以字符为单位进行处理的,bytes类型是以字节为单位处理的。bytes数据类型在所有的操作和使用甚至内置方法上和字符串数据类型基本一样,也是不可变的序列对象。bytes对象只负责以二进制字节序列的形式记录所需记录的对象,至于该对象到底表示什么(比如到底是什么字符)则由相应的编码格式解码所决定。
Python3中,bytes通常用于网络数据传输、二进制图片和文件的保存等等。
可以通过调用bytes()生成bytes实例,其值形式为 b'xxxxx',其中 'xxxxx' 为一至多个转义的十六进制字符串(单个 x 的形式为:\x12,其中\x为小写的十六进制转义字符,12为二位十六进制数)组成的序列,每个十六进制数代表一个字节(八位二进制数,取值范围0-255),对于同一个字符串如果采用不同的编码方式生成bytes对象,就会形成不同的值.
python3 :
str在内存中是用unicode编码的 (一个文件也是一个大的字符串)
bytes类型(也是一种数据类型)
对于英文:
str : 表现形式 s ='alex'
编码方式 010101010 unicode
bytes:表现形式 s = b'alex'
编码方式 000101010 utf-8/gbk/···
对于中文:
str : 表现形式 s ='中国'
编码方式 010101010 unicode
bytes:表现形式 s = b'x\e91\e91\e01\e21\e31\e32' (这个表现形式是看不懂的,需要经过计算)
编码方式 000101010 utf-8/gbk/···

 浙公网安备 33010602011771号
浙公网安备 33010602011771号