
一、系统环境:
操作系统:ubuntu 22.04
K8S版本: 1.25.9
ingress版本:1.8.1
二、问题现象
访问静态文件总会有pending情况, 需要多次刷新解决
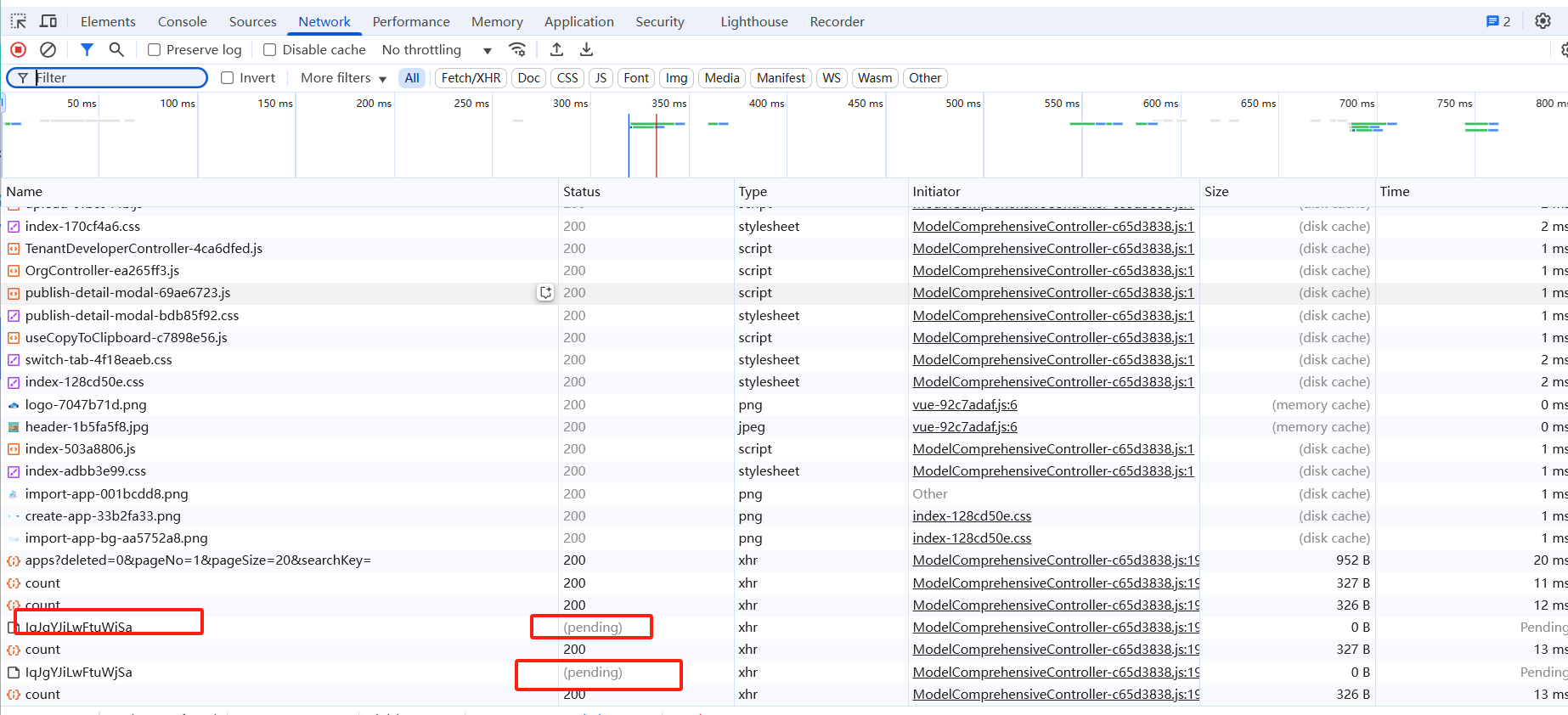
pending时候,ingress日志看不到请求内容
三、ingress启动异常日志


2025/03/11 05:10:05 [alert] 39#39: sendmsg() failed (9: Bad file descriptor) 2025/03/11 05:10:05 [alert] 39#39: sendmsg() failed (9: Bad file descriptor) 2025/03/11 05:10:05 [alert] 39#39: sendmsg() failed (9: Bad file descriptor) 2025/03/11 05:10:05 [alert] 39#39: sendmsg() failed (9: Bad file descriptor) 2025/03/11 05:10:05 [alert] 39#39: sendmsg() failed (9: Bad file descriptor) 2025/03/11 05:10:05 [alert] 39#39: sendmsg() failed (9: Bad file descriptor) 2025/03/11 05:10:05 [alert] 39#39: sendmsg() failed (9: Bad file descriptor) 2025/03/11 05:10:05 [alert] 39#39: sendmsg() failed (9: Bad file descriptor) 2025/03/11 05:10:05 [alert] 39#39: sendmsg() failed (9: Bad file descriptor) 2025/03/11 05:10:05 [alert] 39#39: sendmsg() failed (9: Bad file descriptor) 2025/03/11 05:10:05 [alert] 39#39: sendmsg() failed (9: Bad file descriptor) 2025/03/11 05:10:05 [alert] 39#39: sendmsg() failed (9: Bad file descriptor) 2025/03/11 05:10:05 [alert] 39#39: sendmsg() failed (9: Bad file descriptor) 2025/03/11 05:10:05 [alert] 39#39: sendmsg() failed (9: Bad file descriptor) 2025/03/11 05:10:05 [alert] 39#39: sendmsg() failed (9: Bad file descriptor) 2025/03/11 05:10:05 [alert] 1225#1225: pthread_create() failed (11: Resource temporarily unavailable) 2025/03/11 05:10:05 [alert] 1231#1231: pthread_create() failed (11: Resource temporarily unavailable) 2025/03/11 05:10:05 [alert] 39#39: worker process 691 exited with fatal code 2 and cannot be respawned 2025/03/11 05:10:05 [alert] 39#39: worker process 723 exited with fatal code 2 and cannot be respawned 2025/03/11 05:10:05 [alert] 39#39: worker process 756 exited with fatal code 2 and cannot be respawned 2025/03/11 05:10:05 [alert] 39#39: worker process 809 exited with fatal code 2 and cannot be respawned 2025/03/11 05:10:05 [alert] 39#39: worker process 860 exited with fatal code 2 and cannot be respawned 2025/03/11 05:10:05 [alert] 39#39: worker process 885 exited with fatal code 2 and cannot be respawned 2025/03/11 05:10:05 [alert] 39#39: worker process 929 exited with fatal code 2 and cannot be respawned 2025/03/11 05:10:05 [alert] 39#39: worker process 974 exited with fatal code 2 and cannot be respawned
发现worker_processes 值等于cpu数量, 默认应该是auto模式了
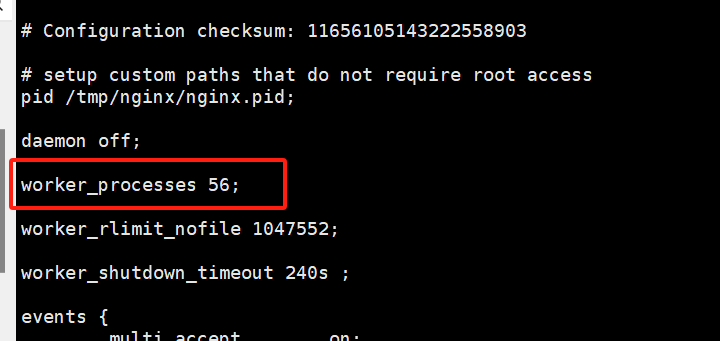
四、临时解决办法
修改configmap: ingress-nginx-controller
worker_processes要小于cpu个数
data:
worker-processes: "4"
重新ingress, 进入容器查看是否修改成功
查看日志是否还有相关的报错,如没有,正常
kubectl rollout restart deploy -n ingress-nginx ingress-nginx-controller
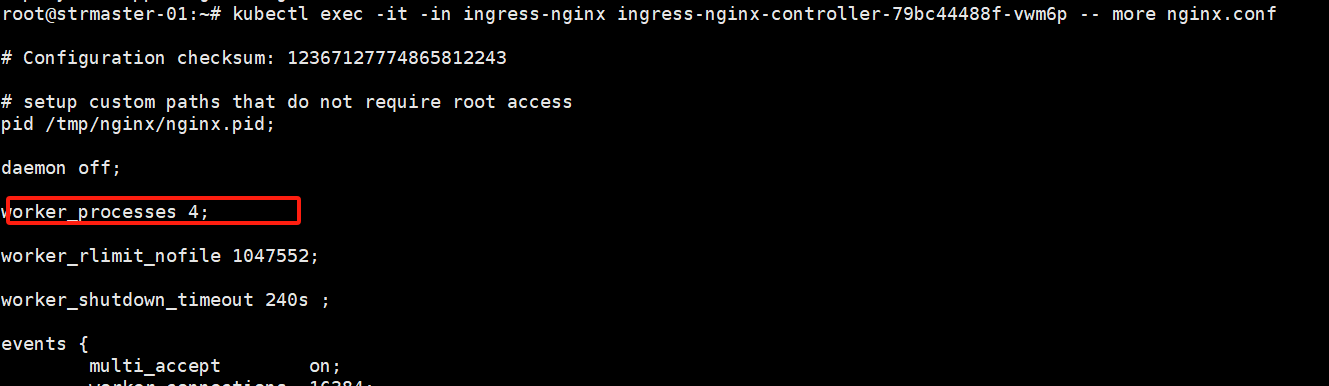
等待半分钟,验证,发现访问流畅
五、查找根因
1.内存够大,排除
2.系统文件描述符设置够大

3.发现有些服务日志产生报错:
failed to create fsnotify watcher: too many open files
解决办法:
fs.inotify.max_user_watches:单个用户可监控的文件/目录数量。
fs.inotify.max_user_instances:单个用户可创建的 inotify 实例数。默认只有128
修改宿主机:
# 临时生效 sudo sysctl -w fs.inotify.max_user_watches=524288 sudo sysctl -w fs.inotify.max_user_instances=1024 # 永久生效 echo "fs.inotify.max_user_watches = 524288" >> /etc/sysctl.conf echo "fs.inotify.max_user_instances = 1024" >> /etc/sysctl.conf sysctl -p
4.dmesg -T 发现ingress重启产生cgroup日志
cgroup: fork rejected by pids controller in /kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod9ed3a9b7_46f9_4e31_83b5_048fa4bbfe44.slice/cri-containerd-a11fdc33537da800a422443fcb261e8167909df0138fa15faa784923e48d80a2.scope
todo
结论:
目前只发现跟ubuntu系统有关, centos没问题, 怀疑此版本系统有相关bug或者兼容性问题
