ROCm Compute Profiler概述:Standalone GUI(Web UI)
Standalone GUI 的目标是:
- 从几 MB 到几百 MB 的 profiling trace / counter 数据中,构建可视化的 Timeline / Counter / Heatmap / 指标图表;
- 在浏览器中提供 可交互 的体验(缩放、过滤、选择 kernel/GPU/metric);
- 在开发效率和性能之间取得平衡:后端 Python + 前端 Dash/Plotly + 数据层 DataFrame 分析。
1. Standalone GUI启动
执行rocprof-compute analyze -p workloads/vcopy/MI200/ --gui启动Profile Workload的分析:
__ _ _ __ ___ ___ _ __ _ __ ___ / _| ___ ___ _ __ ___ _ __ _ _| |_ ___ | '__/ _ \ / __| '_ \| '__/ _ \| |_ _____ / __/ _ \| '_ ` _ \| '_ \| | | | __/ _ \ | | | (_) | (__| |_) | | | (_) | _|_____| (_| (_) | | | | | | |_) | |_| | || __/ |_| \___/ \___| .__/|_| \___/|_| \___\___/|_| |_| |_| .__/ \__,_|\__\___| |_| |_| INFO Analysis mode = web_ui WARNING Detected mismatch in sysinfo versioning. You need to reprofile to update data. INFO [analysis] deriving rocprofiler-compute metrics... INFO Could not find profiling_config.yaml in /home/lbq/rocm/rocm-systems/projects/rocprofiler-compute/tests/workloads/vcopy/MI200 for filtering analysis report WARNING PC sampling: can not detect pc sampling method without /home/lbq/rocm/rocm-systems/projects/rocprofiler-compute/tests/workloads/vcopy/MI200/ps_file_pc_sampling_host_trap.csv Dash is running on http://0.0.0.0:8050/ ...
在浏览器中打开:
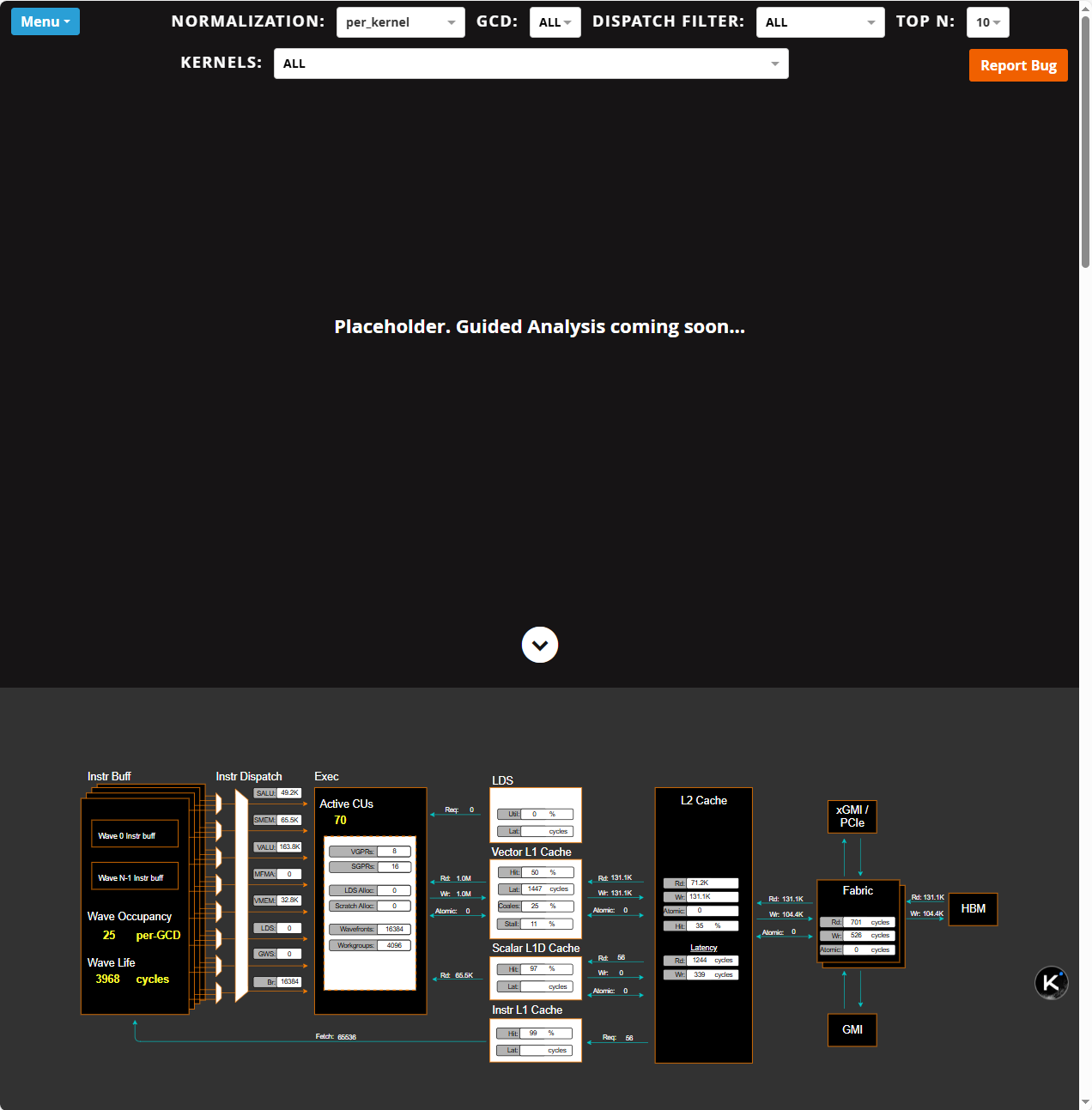
2. 整体架构
2.1 关键文件清单--入口与控制
关键文件清单(快速索引) -- 入口与控制
-
bin/rocprof-compute — 主脚本
-
libexec/rocprofiler-compute/rocprof_compute_base.py — RocProfCompute 控制器与主流程
-
libexec/rocprofiler-compute/rocprof_compute_analyze/analysis_webui.py — webui_analysis(GUI 主逻辑、回调)
-
libexec/rocprofiler-compute/rocprof_compute_analyze/analysis_base.py — OmniAnalyze_Base(通用分析方法)
-
IO / 数据组装
-
libexec/rocprofiler-compute/utils/file_io.py
- create_df_pmc(...) — 读 CSV(pmc_perf.csv, SQ*.csv 等),用 pandas 合并为“mega” DataFrame
- create_df_kernel_top_stats(...) — 生成 pmc_kernel_top.csv 与 pmc_dispatch_info.csv
- load_panel_configs(...) — 读取 panel YAML 配置
-
指标解析 / 计算
-
libexec/rocprofiler-compute/utils/parser.py
- load_table_data(...) — 入口:load_kernel_top() + eval_metric(...)
- eval_metric(...) / AST 转换 / 表达式求值 / apply_filters(...)(CPU/内存密集)
-
绘图 / UI 生成
-
libexec/rocprofiler-compute/utils/gui.py — build_bar_chart, build_table_chart
-
libexec/rocprofiler-compute/utils/gui_components/* — header、memory chart 等小组件
2.2 Standalone GUI架构图
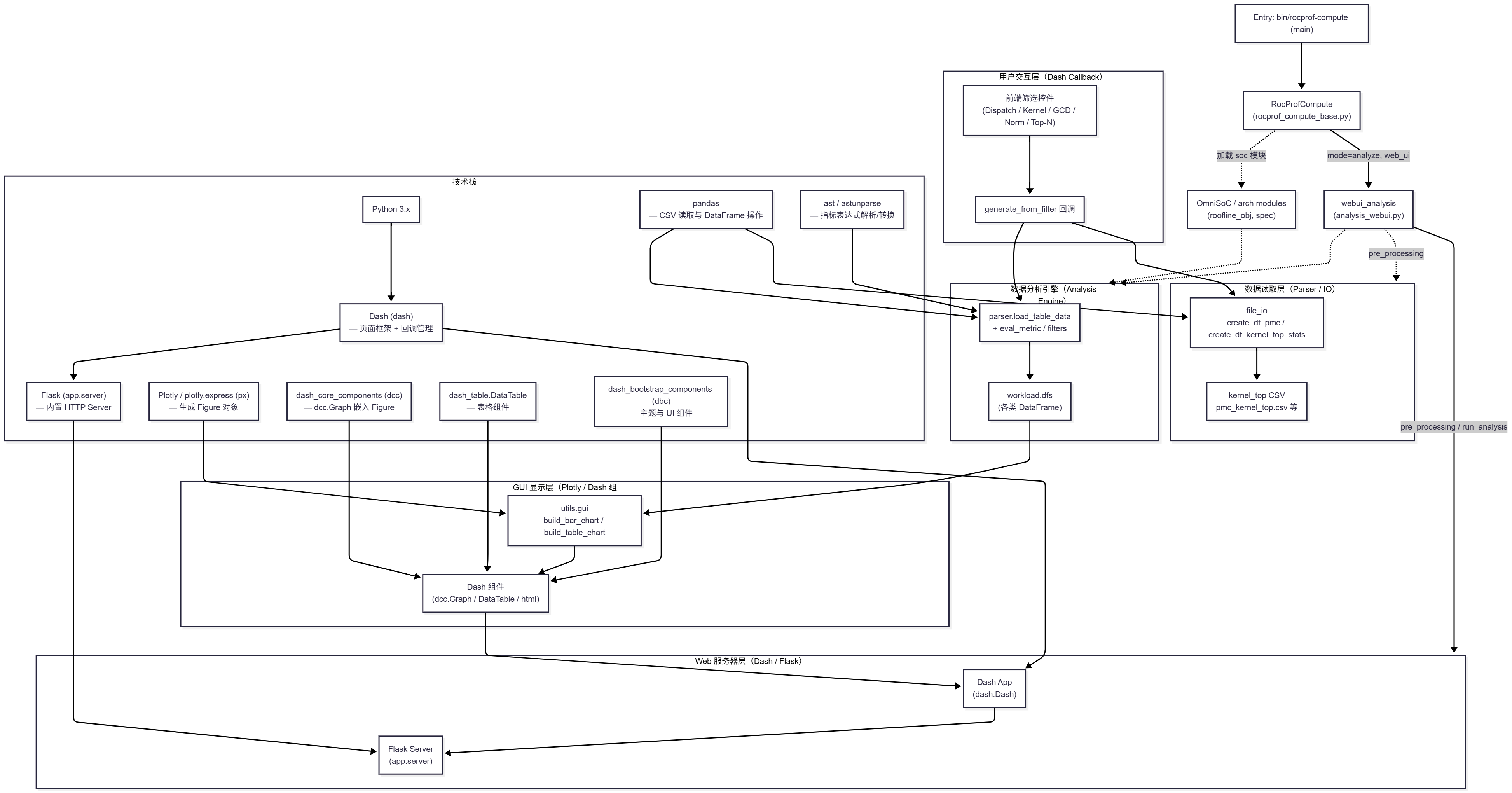
总体架构图从“分层 + 入口控制器 + 技术栈”的角度,可以分块理解:
- 入口与分层说明:
Entry对应脚本bin/rocprof-compute,RocProfCompute是主控制器类,负责根据mode选择webui_analysis;webui_analysis在pre_processing中调用 DataIO/Analysis 层,在run_analysis中初始化并运行 WebServer 层(Dash/Flask);Socs节点代表 OmniSoC/架构模块(roofline_obj、spec),在 pre_processing 和 roofline 相关图表中被 Analysis 层使用。- WebServer 层通过 Dash/Flask 把下方 DataIO/Analysis/GUI/UX 的计算结果暴露为 Web UI。
- 图中的
FileIO、KernelTop、Workload等节点体现了数据从 CSV → DataFrame → 业务指标 → 图表的流转; - DataIO 层由
file_io.create_df_pmc、create_df_kernel_top_stats等函数组成,将磁盘 CSV 转换为内存 DataFrame/统计 CSV; - Analysis 层使用
parser.load_table_data和eval_metric把原始计数器数据转换为面向 GUI 的业务指标表,存放在workload.dfs中; - GUI 层通过
utils.gui和 Dash 组件把业务表渲染为 Plotly 图表/表格; - UX 层由
generate_from_filter回调和前端筛选控件共同构成,负责收集用户输入并驱动各层重新计算。
- 技术栈映射:
- Python 3.x 作为语言运行时;Dash/Flask 提供 Web 框架和 HTTP Server;Plotly/dcc/dash_table/dbc 构成前端可视化和 UI 组件;
- pandas 提供 CSV 读取和 DataFrame 运算,ast/astunparse 提供指标表达式解析与转换,共同支撑 Analysis 层的指标计算。
3. 控制流 & 数据流
3.1 控制流
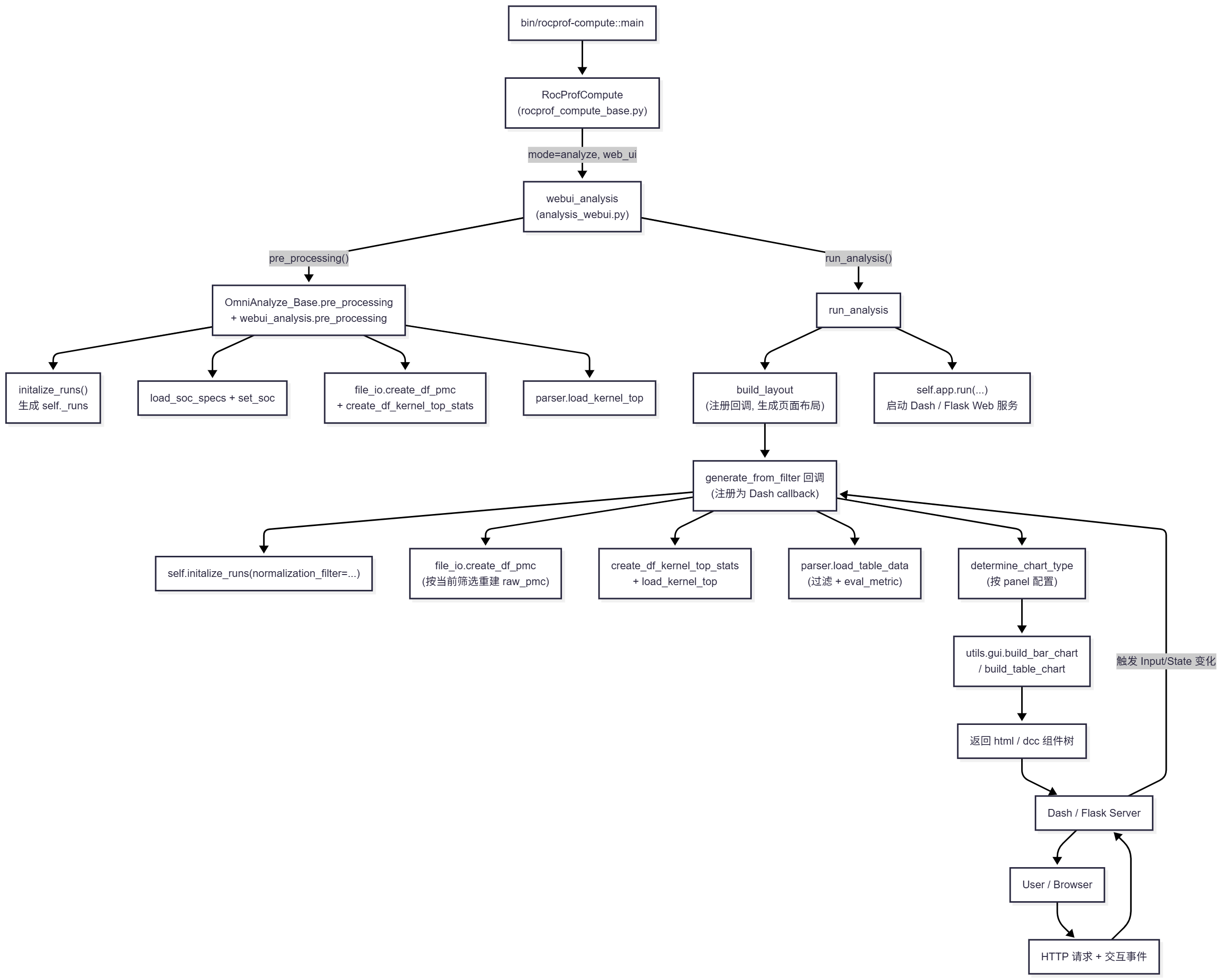
该控制流图从 CLI 到浏览器的完整执行步骤可以细分为:
- 命令行入口与模式分发:
-
- 用户调用
bin/rocprof-compute --mode analyze --web-ui ...; main()中构造RocProfCompute实例,根据mode/子参数选择webui_analysis作为分析器。
- 用户调用
- 分析器初始化与预处理:
-
- 在
webui_analysis.__init__中创建dash.Dash应用并持有self.app;self.app是通过dash.Dash(...)创建的 Dash 应用实例。Dash 本身封装了一个 Flask 应用在self.app.server(类型为flask.app.Flask)。
- 调用
pre_processing():- 通过
OmniAnalyze_Base.pre_processing加载 profiling 配置、sysinfo、SoC 定义; - 调用
initalize_runs()为每个输入目录创建self._runs[...]结构; - 通过
file_io.create_df_pmc/create_df_kernel_top_stats构建初始raw_pmc与 kernel top CSV; - 再由
parser.load_kernel_top将 kernel top 读入 DataFrame,并设置self.arch等元信息。
- 通过
- 在
- 启动 Web 服务:
-
run_analysis()中根据当前架构配置调用build_layout(...)构建页面布局:- 生成页面 header(
utils.gui_components.header.get_header) - 插入 spinner 与
html.Div(id="container") - 注册 Dash 回调
generate_from_filter(监听多个 Input/State)
- 生成页面 header(
- 调用
self.app.run(...)启动 Dash/Flask Web Server,监听指定端口等待浏览器请求。- 调用
self.app.run(...)最终等效于对底层 Flask 应用的run方法(flask.app.Flask.run)进行调用——该方法会用 werkzeug 的开发服务器(werkzeug.serving.run_simple)监听你传入的host/port并处理请求。
- 调用
- 浏览器访问与事件派发:
-
- 浏览器访问
http://host:port,Dash/Flask 返回初始布局 HTML + JS; - 用户在前端页面上操作筛选控件(Dispatch 下拉框、Kernel 过滤、GCD 选择、Normalization、Top-N 等),这些操作被 Dash 前端 JS 打包成 HTTP 请求发回后端。
- 浏览器访问
- 回调执行与结果返回:
-
- Dash Server 收到请求后,根据触发的 Input/State 调用服务器端的
generate_from_filter(...):- 重新初始化 runs:
base_data = self.initalize_runs(normalization_filter=norm_filt) - 复制 panel configs:
panel_configs = copy.deepcopy(arch_configs.panel_configs) - 重新生成原始 pmc dataframe:
base_data[base_run].raw_pmc = file_io.create_df_pmc(self.dest_dir, nodes, ...)- 若需要:
spatial_multiplex_merge_counters(...)
- 设置过滤条件(kernel/gpu/dispatch/top_n)
- 重新生成 Top Stats(
file_io.create_df_kernel_top_stats(...)) - 条件下只保留基本指标(若无筛选)
- 关键一步:
parser.load_table_data(workload=base_data[base_run], dir=self.dest_dir, is_gui=True, args=self.get_args())load_table_data会调用load_kernel_top(...)(除 skip),然后eval_metric(...)eval_metric(...)在内存 DataFrame 上执行 AST 转换、表达式求值、groupby/agg 等,最后更新workload.dfs
- 生成 UI 元素:
- memory chart:
get_memchart(...)(utils/gui_components/memchart.py) - roofline(可选):
self.get_socs()[self.arch].empirical_roofline(...) - 遍历 panel_configs,每个 table:
original_df = base_data[base_run].dfs[table_config["id"]]determine_chart_type(...)→ 内部调用:utils.gui.build_bar_chart(...)或utils.gui.build_table_chart(...)
- 组装返回的 Plotly 图/表到
div_children
- memory chart:
- 返回
div_children给 Dash(更新前端)
- 重新初始化 runs:
- Dash 将更新后的组件树序列化回前端,浏览器据此更新页面中的 Graph/Table 部分,实现一次交互闭环。
- Dash Server 收到请求后,根据触发的 Input/State 调用服务器端的
3.2 数据流(强调 CSV → Pandas)
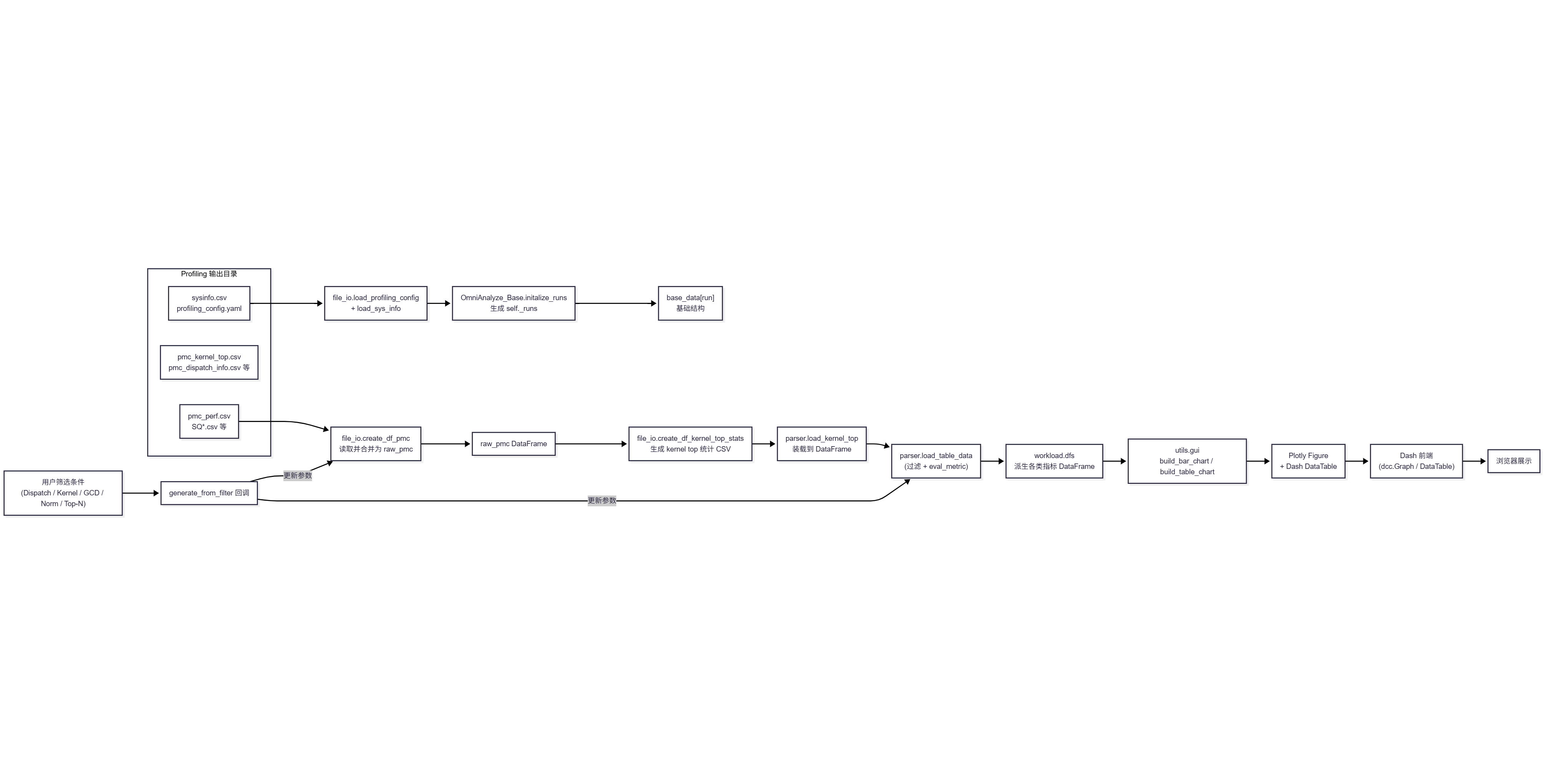
这张数据流图强调“数据对象”的生命周期,各阶段可以总结为:
- 输入阶段(磁盘 CSV / 配置):
- Profiling 输出目录中包含
pmc_perf.csv、各类SQ*.csv、pmc_kernel_top.csv、pmc_dispatch_info.csv、sysinfo.csv、profiling_config.yaml等文件; - 这些文件由 Profiling Pipeline 生成,是 GUI 端所有分析的原始数据源。
- Profiling 输出目录中包含
- 装载与预聚合阶段(DataIO):
file_io.create_df_pmc扫描指定目录的多个 CSV,依据节点/时间/计数器类型等信息合并为一个多层列索引的raw_pmcDataFrame;file_io.create_df_kernel_top_stats基于raw_pmc计算 kernel top、dispatch 级别的统计信息,输出新的 CSV 文件;parser.load_kernel_top将这些统计 CSV 装载到 DataFrame 中,挂到对应的 run 结构下。
- 分析计算阶段(Analysis Engine):
parser.load_table_data根据 panel 配置和当前筛选条件,对raw_pmc、kernel top 等 DataFrame 进行过滤、分组聚合和表达式求值(eval_metric);- 计算结果以多张命名 DataFrame 的形式存入
workload.dfs[...],这些表直接驱动后续 GUI 渲染。
- 可视化阶段(GUI):
utils.gui.build_bar_chart/build_table_chart等函数从workload.dfs中取出指定 ID 的 DataFrame,转换为 Plotly Figure 或 Dash DataTable;- 这些 Figure/表与周围的布局组件(标题、说明、控制按钮等)一起构成返回给前端的组件树。
- 交互闭环阶段(前端筛选 → 后端重算):
- 用户在浏览器中修改 Dispatch/Kernel/GCD/Normalization/Top-N 等筛选控件,Dash 前端 JS 将新状态发送到后端;
- 后端重新执行上述 DataIO + Analysis + GUI 过程,返回新的图表和表格;
- 因为核心数据读取/合并逻辑依赖
create_df_pmc,如果没有缓存机制,这一阶段会重复大量 CSV IO 和 Pandas 计算,是潜在性能瓶颈。
数据流与性能热点(要点)
-
数据流简述:
- 原始 profiling 输出(目录下
pmc_perf.csv,SQ*.csv,pmc_kernel_top.csv等) →file_io.create_df_pmc用 pandas 读入并合并为raw_pmc→parser.load_table_data(apply_filters + eval_metric)计算并填充各个workload.dfs→utils.gui生成 Plotly figure → Dash 前端渲染。
- 原始 profiling 输出(目录下
-
性能热点(可改进点):
- create_df_pmc: 每次 Dash 回调都会读 CSV 并合并(高 IO 开销)。
- parser.eval_metric: 在内存 pandas 上做大量 groupby/表达式求值,CPU 密集。
- Dash 回调是同步阻塞:回调执行期间页面无响应,可能超时或卡顿。
4. 关键技术栈 & 业内对比
| 分类 | 当前 | 短期建议 | 长期建议 | 简要理由 |
|---|---|---|---|---|
| 数据格式 | CSV + pandas DataFrame | 保留 CSV 原始输入;在 create_df_pmc 输出写 Parquet 做缓存 |
Parquet 为主持久层,按 workload/参数分区;支持 DuckDB/Polars | Parquet 列式、高压缩、与加速引擎兼容,减少重复 IO |
| 数据处理 | pandas + 自定义 AST | 优先命中 Parquet 缓存;关键聚合可用 DuckDB SQL | 把热点计算迁移到 Polars 或 DuckDB(并行化) | 提升并行与内存效率,降低 GIL/CPU 瓶颈 |
| 存储 / 查询引擎 | 无专门引擎(文件为主) | 本地使用 Parquet + 可选嵌入 DuckDB 做聚合 | 引入 DuckDB 为主或 ClickHouse(规模大时) | DuckDB 对本地分析友好,ClickHouse 支持高并发 OLAP |
| 缓存 / 状态 | 无或有限(内存) | 使用 Parquet 文件做持久缓存;短期可引入 Redis 作小对象缓存 | Redis + 本地/对象存储(S3)做缓存层,结合 CDN/反向代理 | 减少重复计算与IO,提升并发响应 |
| 异步任务队列 | 无(回调同步阻塞) | 将重计算任务封装为后台任务(RQ/Celery + Redis),前端轮询/WS | 完整异步架构:任务队列 + 可扩展 worker 池 + 结果持久化 | 避免回调阻塞,提高并发与用户体验 |
| Server(API) | Dash (Flask),dev server self.app.run |
明确使用 self.app.run_server();生产用 gunicorn/nginx |
拆为 FastAPI 后端 + worker;ASGI (uvicorn) + gunicorn 管理 | 短期稳定化,长期可异步并水平扩展 |
| Client(交互层) | Dash 前端(dcc、dash_table、dbc) | 保留 Dash;减少阻塞逻辑,使用 WS/轮询展示后台任务结果 | 前端改用 React + Plotly.js/Vega;采用 WebSocket 推送 | Dash 快速开发,React 更灵活、高性能的生产级 UI |
| GUI / 可视化 | Plotly / plotly.express,custom helpers | Plotly + WebGL(scattergl)/服务端下采样 | Plotly.js/Deck.gl/Vega 联合,GPU 加速前端渲染 | 支持大量点和复杂图交互 |
| 部署 / 编排 | 手动 / dev server | 使用 gunicorn 多 worker + nginx 反向代理 | Docker + Kubernetes / Nomad + CI/CD | 生产化、可扩展、自动化部署 |
| 观测 / 日志 / 追踪 | 基本日志 | 增加结构化日志(JSON)、指标(Prometheus)和简单追踪 | Prometheus + Grafana + Jaeger/OpenTelemetry | 监控性能、定位瓶颈、报警与用户可视化 |
| 认证 / 安全 | 未见专门机制 | 在前端/服务层增加简单访问控制(IP 或 基本 auth) | OAuth2 / JWT + HTTPS + RBAC + 审计日志 | 保护数据和远程访问,合规和生产安全需求 |
| 测试 / CI | 未见完备测试 | 增加单元测试与集成测试(关键 compute 函数) | 完整 CI/CD(lint/test/build/deploy)与回归套件 | 保证改动安全、降低回归风险 |
| 数据采集 / 预处理 | CSV 由 profiler 输出 | 保持 profiler 输出;在 ingest 层做预检和元数据生成 | 建立 ETL/调度(定期预处理、增量导入) | 稳定数据输入,便于后续缓存与查询 |
| 硬件 / 加速 | CPU + pandas(无特化加速) | 对昂贵计算使用多核或分批处理 | 使用 SIMD/Rust(Polars)、GPU 加速(如 Rapids)在需要时 | 加速大数据集处理,缩短响应时间 |
| 包 / 依赖 / 环境 | requirements.txt / pyproject | 明确 requirements.txt、虚拟环境和可复现镜像 |
使用 lockfile(pipenv/poetry/pip-tools),提供 Docker 镜像 | 可复现环境,便于部署与协作 |
5 增强
5.1 打开Debug mode
修改/opt/rocm-7.0.1/libexec/rocprofiler-compute/rocprof_compute_analyze/analysis_webui.py:
def run_analysis(self): """Run CLI analysis.""" super().run_analysis() args = self.get_args() input_filters = { "kernel": self._runs[self.dest_dir].filter_kernel_ids, "gpu": self._runs[self.dest_dir].filter_gpu_ids, "dispatch": self._runs[self.dest_dir].filter_dispatch_ids, "normalization": args.normal_unit, "top_n": args.max_stat_num, } self.build_layout( input_filters, self._arch_configs[self.arch], ) if args.random_port: self.app.run(debug=True, host="0.0.0.0", port=random.randint(1024, 49151)) else: self.app.run(debug=True, host="0.0.0.0", port=args.gui)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号