RISC-V扩展指令集说明
1 RISC-V扩展指令集列表
RISC-V扩展指令集列表:
| 类别 | 扩展名 | 英文全称 | 功能描述 | 详细用途 | 状态 |
|---|---|---|---|---|---|
| 基础整数扩展 | I | Base Integer | RV32I/RV64I核心指令集 | 提供基础整数运算(加减/逻辑运算)和控制流(跳转/分支),所有RISC-V处理器的基础运行环境。 | 强制实现 |
| E | Embedded | 精简为16个通用寄存器 | 降低嵌入式设备资源开销(减少寄存器面积40%),适用于IoT传感器、低功耗MCU等资源受限场景。 | 可选 | |
| 标准扩展 | M | Multiply/Divide | 硬件乘除法指令 | 加速整数乘除运算(10-100x速度提升),用于加密算法、数据压缩等计算密集型任务。 | 广泛实现 |
| A | Atomic Operations | 原子内存操作 | 实现多核同步原语(锁/信号量),支持SMP系统、实时操作系统中的资源共享。 | 广泛实现 | |
| C | Compressed Instructions | 16位压缩指令 | 减少代码体积(平均30%),提高指令缓存效率,适用于嵌入式设备和内存受限系统。 | 广泛实现 | |
| B | Bit-manipulation | 位操作(含Zba/Zbb) | 加速位字段操作(如CRC32)、加密算法(比特置换)和数据处理(位计数/循环移位),用于网络协议处理、密码学实现。 | 可选 | |
| 特权架构 | M-mode | Machine Mode | 最高特权级(硬件初始化/异常处理) | 处理器启动、异常处理、安全监控核心,所有RISC-V系统的底层控制层。 | 强制实现 |
| S | Supervisor Mode | 操作系统内核级 | 运行操作系统内核,管理虚拟内存(MMU)和进程调度,支持Linux/FreeBSD等多任务系统。 | 可选 | |
| U | User Mode | 应用程序级 | 运行用户态程序,提供内存隔离保护,防止应用程序直接访问硬件资源。 | 可选 | |
| H | Hypervisor | 虚拟机管理 | 支持硬件虚拟化(KVM/Xen),实现云服务器、容器化环境中的虚拟机隔离和管理。 | 可选 | |
| 系统扩展 | Zicsr | Control and Status Registers | 控制和状态寄存器访问 | 配置硬件参数(中断使能/优先级),性能计数器访问,系统级调试和控制(如mstatus/mcause寄存器操作)。 | 广泛实现 |
| Zifencei | Instruction-Fetch Fence | 指令流同步屏障 | 保证自修改代码安全(JIT编译器),确保指令缓存与内存一致性,防止指令预取错误。 | 广泛实现 | |
| 浮点扩展 | F | Single-Precision FP | 单精度浮点 | 基础科学计算(32位浮点运算),用于图形处理、传感器数据处理等场景。 | 可选 |
| D | Double-Precision FP | 双精度浮点 | 高精度科学计算(64位浮点),用于金融建模、气候模拟等需要高精度的领域。 | 可选 | |
| Zcd | Compressed Double-precision | 压缩双精度浮点指令集 | 在D扩展基础上添加压缩指令,减少代码体积。 | ||
| Zfd | Additional Floating-point Instructions | 附加浮点指令扩展 | 为D/F扩展补充新操作,优化性能。 | ||
| Zfh/Zfhmin | Half-Precision FP (minimal) | 半精度浮点(完整/最小集) | AI推理加速(减少50%模型存储)、移动端图形渲染,适用于边缘AI设备。 | 可选 | |
| 浮点优化 | Zfa | Additional FP Instructions | 浮点常数加载/比较优化 | 提升浮点性能(减少指令数20%),优化科学计算库和AI框架的常数加载效率。 | 需F/D |
| Zfinx | FP in Integer Registers | 浮点操作使用整数寄存器 | 节省浮点寄存器文件面积(减少芯片面积30%),用于超低功耗嵌入式设备。 | 可选 | |
| Zdinx | DP in Integer Registers | 双精度浮点使用整数寄存器 | 在嵌入式系统中实现高精度计算(如工业控制),保持Zfinx的面积优势。 | 需Zfinx | |
| Zhinx/Zhinxmin | HP in Integer Registers | 半精度浮点使用整数寄存器 | 在边缘AI设备中平衡计算精度和功耗,支持轻量级AI推理。 | 需Zfinx | |
| 性能监控 | Zicntr | Base Counters/Timers | 基础硬件计数器(cycle/time/instret) | 性能分析(CPI测量)、实时系统调度(时间片管理)、功耗管理的基础设施。 | 强制实现 |
| Zihpm | Hardware Perf Monitoring | 性能监控计数器 | 系统级性能剖析(缓存命中率/分支预测率),用于服务器调优和AI芯片性能优化。 | 可选 | |
| 提示指令 | Zihintntl | Non-Temporal Locality Hint | 标记短期数据内存访问 | 优化流式数据处理(视频编解码),减少缓存污染,提升GPU-CPU数据交互效率。 | 可选 |
| Zihintpause | Pause Hint | 优化低功耗忙等待循环 | 降低自旋锁功耗(减少40%等待能耗),优化多核同步效率。 | 可选 | |
| 矩阵操作 | Zimop | Matrix Operations | 矩阵乘加/转置指令 | 加速AI训练(MatMul算子性能提升8x)、科学计算(矩阵分解),替代专用AI加速器。 | 提案中 |
| 条件操作 | Zicond | Conditional Operations | 零开销条件移动(czero.eqz/nez) | 消除分支预测惩罚,优化数据库查询、编译器生成的条件代码性能。 | 可选 |
| 内存模型 | Ztso | Total Store Ordering | 强化内存一致性(全序存储) | 确保多核内存顺序一致性,简化高并发编程(数据库/Web服务器),替代复杂的内存屏障逻辑。 | 可选 |
| 缓存管理 | Zicbom | Cache Block Management | 缓存块操作(清除/刷回/无效化) | 维护多核缓存一致性,防止DMA操作的数据冲突,实时系统的关键保障。 | 可选 |
| Zcmop | Cache Management Operations | 缓存管理操作扩展 | 优化缓存维护指令效率,减少缓存操作延迟(30%),提升异构计算效率。 | 可选 | |
| 压缩扩展 | Zc | Compressed Subset | 16位压缩指令子集 | 极致代码密度优化(适用于≤32KB内存设备),用于智能卡、超低功耗传感器节点。 | 可选 |
| 安全扩展 | Smepmp | Enhanced Physical Memory Protection | PMP增强(64条目+锁域) | 构建TEE安全飞地(如机密计算),实现硬件级内存隔离,防止物理攻击。 | 需M-mode |
| Zicfilp | Frontend Load Filtering | 防Spectre攻击 | 阻止推测执行侧信道攻击,保护加密密钥安全,符合金融/医疗设备安全标准。 | 可选 | |
| Smstateen | State Enable Control | 扩展功能动态开关 | 按需启用向量/加密单元,减少攻击面,满足功能安全认证(ISO 26262)。 | 需M-mode | |
| Zabha | Byte/Halfword Atomic Ops | 细粒度原子操作 | 实现高效无锁数据结构(RCU/队列),优化实时系统和高并发中间件性能。 | 可选 | |
| Smcdeleg | Exception Delegation | M→S模式异常委托 | 减少特权切换开销(提升30%中断响应速度),优化实时操作系统性能。 | 可选 | |
| 调试追踪 | Zilsd | Instruction/Load-Store Debug | 指令与内存访问调试 | 设置硬件断点、监控内存访问错误,用于汽车电子、工业控制器的安全审计。 | 可选 |
| Zclsd | Compressed Load-Store Debug | 压缩指令调试支持 | 优化C扩展代码的调试体验,减少嵌入式开发调试时间。 | 可选 | |
| 动态语言 | J | Dynamic Languages | Java/JS硬件加速 | 加速JVM字节码执行(提升3x性能),用于智能卡Java应用、边缘计算JavaScript环境。 | 可选 |
| 十进制浮点 | L | Decimal Floating-Point | IEEE 754-2019十进制浮点 | 精确财务计算(避免二进制浮点误差),用于金融交易系统、税务软件。 | 可选 |
| 用户中断 | N | User-Level Interrupts | 用户态直接处理中断 | 实现高效实时系统(<5μs中断延迟),用于工业控制器、汽车ECU的实时响应。 | 可选 |
| 向量扩展 | V | Vector Operations | SIMD并行指令集 | 数据并行计算(AI推理/图像处理),替代GPU的轻量级加速方案,支持LLVM自动向量化。 | 可选 |
| 密码 | K | Scalar Cryptography Extension | 标量密码学扩展 | 提供硬件级加密加速指令。 | |
| 原子比较 | Zacas | Atomic Compare-and-Dual-Write | 原子比较双写 | 增强原子操作能力。 |
2 RISC-V C/Zc压缩扩展指令集
RISC-V 压缩指令扩展(通常称为 C 扩展)是 RISC-V 指令集架构(ISA)的一个可选标准扩展,其核心思想是引入长度为 16 位的指令,与标准的 32 位 RISC-V 指令(称为基础指令)混合使用。
| 特性 | 说明 |
|---|---|
| 指令长度 | 固定 16 位(标准 RISC-V 指令为 32 位)。 |
| 设计目标 | 减少代码体积(平均 20-30% 压缩率),提升 I-Cache 效率。 |
| 扩展名称 | 基础扩展 C(又名 Zca),子扩展包括 Zcb(字节操作)、Zcf/Zcd(浮点)。 |
| 指令数量 | 基础指令 40 条(可扩展至 60+ 条)。 |
| 寄存器支持 | 仅使用 8 个常用寄存器(x8-x15, f8-f15)优化编码空间。 |
| 兼容性 | 无缝混合 16/32 位指令(处理器自动检测高两位 11 为 32 位,否则为 16 位)。 |
优点
-
显著减小代码大小: 这是最主要的目标。典型应用程序的代码大小平均可减少 25% - 30%,效果非常显著。
-
降低存储成本: 更小的程序意味着可以使用更小、更便宜的 ROM/Flash。
-
降低内存带宽需求: 读取指令所需的数据量减少。
-
降低功耗: 减少内存访问是降低系统功耗的有效手段。
-
提升缓存效率: 在相同大小的指令缓存中能容纳更多有效指令。
-
无缝兼容: C 扩展指令与标准 32 位指令共存于同一个指令流中。编译器/汇编器自动选择使用 16 位还是 32 位指令,程序员通常无需关心(只需在编译时指定支持 C 扩展)。所有标准的 32 位寄存器(x0-x31)和地址空间均可访问。
-
广泛支持: 是 RISC-V 基金会定义的标准扩展,得到主流工具链(编译器 GCC/LLVM、调试器)和大多数 RISC-V 处理器实现的支持。
缺点
-
增加硬件复杂度:
-
解码器更复杂: 处理器需要能同时解码相邻的 16 位和 32 位指令(指令边界不再是固定的 32 位),增加了取指和解码逻辑的复杂度。
-
指令对齐: 16 位指令的引入使得指令地址可能不再总是 32 位(4 字节)对齐,需要硬件处理非对齐的指令访问(虽然通常发生在取指阶段内部)。
-
-
潜在的轻微性能开销: 更复杂的解码逻辑在极端追求高频的设计中可能带来轻微的速度或功耗代价(但通常被代码密度带来的缓存和带宽收益所抵消)。
-
可选扩展: 虽然很流行,但 C 扩展仍然是可选的。并非所有的 RISC-V 核心都实现它(尽管绝大多数通用和嵌入式核心都会实现)。
-
有限的表达能力: 16 位指令所能携带的操作码、寄存器地址和立即数信息远少于 32 位指令。C 扩展精心挑选了最常用、操作数需求最简单的基础指令(如常用算术运算、加载/存储小偏移量、条件跳转短距离、寄存器操作等)进行压缩。复杂操作仍需 32 位指令。
C扩展以及Zc扩展族关系
- C 扩展 (Base “C” Standard Extension)是最早定义的标准压缩指令集(RV32C/RV64C),提供 16 位版本的常用 32 位指令(如 lw, sw, addi, j, beqz 等)。是所有其他压缩扩展的基石和超集。Zcmp, Zcmt, Zcd 等都是在 C 扩展预留的编码空间内定义的新 16 位指令。
- 随着需求细化,RISC-V 将压缩扩展分层(stratified),拆分成更小、更专注的独立扩展(通常以 Zc 命名),允许芯片根据应用场景选择性地实现。包含 Zca, Zcb, Zcf, Zcd, Zcmp, Zcmt, Zcmpe 等都属于 ZC 家族。大部分 ZC 扩展依赖 Zca (见下文)。
-
Zca 扩展 (Core “C” Instructions):是 C 扩展的一个子集,包含了 C 扩展中最核心、最通用的压缩指令(如压缩加载/存储、跳转、整数运算)。是其他 ZC 扩展(如 Zcmp, Zcmt, Zcd, Zcb)的强制依赖项。如果一个实现支持 Zcmp,它必须同时支持 Zca (以及基础的 C 环境)。提供最小化的、必需的压缩指令核心集,作为构建其他专用压缩扩展的基础。
-
Zcmp 扩展 (Multi-Push/Pop):专注于函数调用序言/尾声优化,提供 cm.push, cm.pop, cm.popret 等指令,单指令保存/恢复多个寄存器并调整栈指针。需要 Zca。专用优化,显著减少函数调用开销和代码大小。
-
Zcmt 扩展 (Table Jump):提供 cm.jt 和 cm.jalt 指令,实现基于表格的间接跳转。跳转目标地址存储在一个专用的、由 mtvt CSR 指向的内存表中。主要用于中断/异常向量表或函数指针跳转表,用一条 16 位指令替代原本需要的多条指令(加载地址 + 跳转)。需要 Zca。专用优化,高效处理跳转表和中断向量。
-
Zcd 扩展 (Compressed Double-Precision Floating-Point):提供 D 扩展 (双精度浮点) 中常用指令的 16 位压缩版本(如 c.fld, c.fsd, c.fldsp, c.fsdsp)。必须同时实现 D 扩展和 Zca 扩展。Zcd 只是 D 指令的压缩形式,没有 D 就没有意义。减少浮点密集型代码(尤其是涉及双精度浮点加载/存储)的体积。
-
Zcb 扩展 (Compressed Basic Bit-Manipulation):提供常用位操作指令(如 c.zext.b, c.sext.b, c.zext.h, c.sext.h, c.and, c.or, c.xor, c.not, c.mul) 的 16 位压缩版本。依赖Zca。可能还需要基础位操作扩展(如 Zbb)支持其功能。减少常用位操作和整数乘法的代码大小。
-
Zcf 扩展 (Compressed Single-Precision Floating-Point):提供 F 扩展 (单精度浮点) 中常用指令的 16 位压缩版本(如 c.flw, c.fsw, c.flwsp, c.fswsp)。必须同时实现 F 扩展和 Zca 扩展。减少单精度浮点加载/存储代码体积。
-
Zcmpe 扩展:一个可选扩展,主要在中断处理上下文中提供额外的 cm.push / cm.pop 变体,支持保存/恢复 a0-a5 等 caller-saved 寄存器。依赖 Zcmp (因此也依赖 Zca)。
-
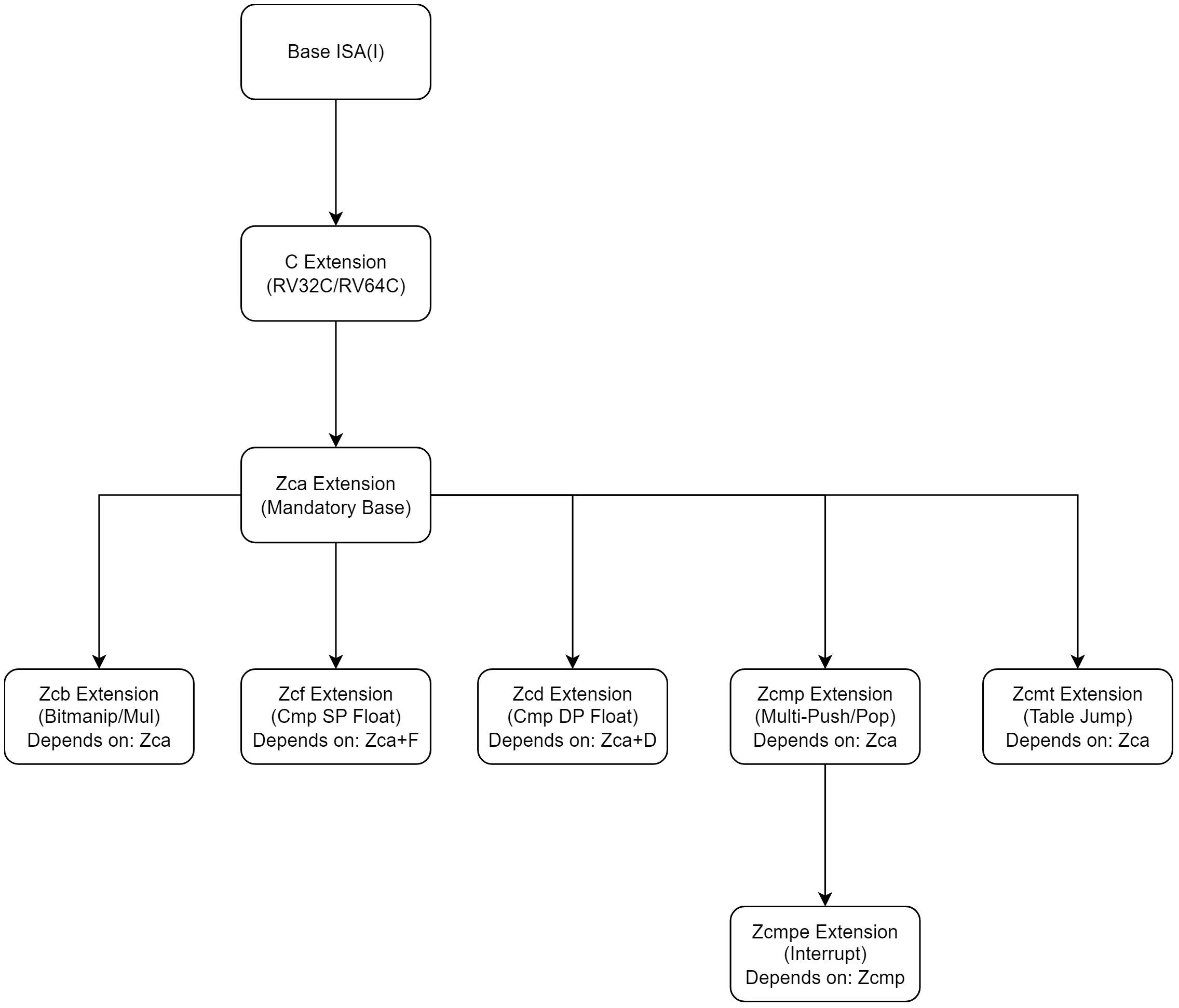
- C 是总框架: 所有压缩指令(包括 Zc)都遵循 C 扩展的编码规则和空间。
- Zca 是基石: 几乎所有的专用 ZC 扩展 (Zcb, Zcf, Zcd, Zcmp, Zcmt) 都强制依赖 Zca。Zca 提供了最基础的压缩指令环境。
- 功能分工明确:
- Zcmp:函数调用栈管理优化。
- Zcmt:跳转表/中断向量优化。
- Zcd:双精度浮点加载/存储压缩 (需 D 扩展)。
- Zcf:单精度浮点加载/存储压缩 (需 F 扩展)。
- Zcb:常用位操作和整数乘法压缩。
- Zcmpe:Zcmp 的中断处理增强。
RISC-V指令列表
| 类别 | 指令 | 格式 | 功能说明 | 等效指令 | 数据位宽 | 必需扩展 |
|---|---|---|---|---|---|---|
| 整数计算 | c.addi4spn |
c.addi4spn rd, imm |
基于栈指针的地址计算 | addi rd, sp, imm |
- | Zca |
c.addi |
c.addi rd, imm |
寄存器加小立即数 | addi rd, rd, imm |
- | Zca | |
c.addiw |
c.addiw rd, imm |
64位寄存器加立即数 (RV64) | addiw rd, rd, imm |
- | Zca + RV64 | |
c.addi16sp |
c.addi16sp imm |
栈指针大范围调整 | addi sp, sp, imm |
- | Zca | |
c.li |
c.li rd, imm |
加载小立即数到寄存器 | addi rd, x0, imm |
- | Zca | |
c.lui |
c.lui rd, imm |
加载高位立即数 | lui rd, imm |
- | Zca | |
c.slli |
c.slli rd, shamt |
逻辑左移 | slli rd, rd, shamt |
- | Zca | |
c.mv |
c.mv rd, rs |
寄存器间数据移动 | add rd, x0, rs |
- | Zca | |
c.add |
c.add rd, rs |
寄存器加法 | add rd, rd, rs |
- | Zca | |
c.andi |
c.andi rd, imm |
与立即数操作 | andi rd, rd, imm |
- | Zca | |
c.sub |
c.sub rd, rs |
整数减法 | sub rd, rd, rs |
- | Zca | |
c.xor |
c.xor rd, rs |
异或运算 | xor rd, rd, rs |
- | Zca | |
c.or |
c.or rd, rs |
或运算 | or rd, rd, rs |
- | Zca | |
c.and |
c.and rd, rs |
与运算 | and rd, rd, rs |
- | Zca | |
| 控制流 | c.j |
c.j imm |
无条件跳转 | jal x0, imm |
- | Zca |
c.jal |
c.jal imm |
链接跳转 (RV32专用) | jal x1, imm |
- | Zca + RV32 | |
c.jr |
c.jr rs |
寄存器间接跳转 | jalr x0, rs, 0 |
- | Zca | |
c.jalr |
c.jalr rs |
链接寄存器跳转 | jalr x1, rs, 0 |
- | Zca | |
c.beqz |
c.beqz rs, imm |
等于零时跳转 | beq rs, x0, imm |
- | Zca | |
c.bnez |
c.bnez rs, imm |
不等于零时跳转 | bne rs, x0, imm |
- | Zca | |
| 整数加载/存储 | c.lw |
c.lw rd, rs1(imm) |
加载字数据 | lw rd, imm(rs1) |
32-bit | Zca |
c.ld |
c.ld rd, rs1(imm) |
加载双字数据 (RV64) | ld rd, imm(rs1) |
64-bit | Zca + RV64 | |
c.sw |
c.sw rs2, rs1(imm) |
存储字数据 | sw rs2, imm(rs1) |
32-bit | Zca | |
c.sd |
c.sd rs2, rs1(imm) |
存储双字数据 (RV64) | sd rs2, imm(rs1) |
64-bit | Zca + RV64 | |
c.lwsp |
c.lwsp rd, imm(sp) |
基于栈指针加载字 | lw rd, imm(sp) |
32-bit | Zca | |
c.ldsp |
c.ldsp rd, imm(sp) |
基于栈指针加载双字 (RV64) | ld rd, imm(sp) |
64-bit | Zca + RV64 | |
c.swsp |
c.swsp rs2, imm(sp) |
基于栈指针存储字 | sw rs2, imm(sp) |
32-bit | Zca | |
c.sdsp |
c.sdsp rs2, imm(sp) |
基于栈指针存储双字 (RV64) | sd rs2, imm(sp) |
64-bit | Zca + RV64 | |
| Zcb扩展 | c.lbu |
c.lbu rd, rs1(imm) |
加载无符号字节 | lbu rd, imm(rs1) |
8-bit | Zca + Zcb |
c.lhu |
c.lhu rd, rs1(imm) |
加载无符号半字 | lhu rd, imm(rs1) |
16-bit | Zca + Zcb | |
c.lh |
c.lh rd, rs1(imm) |
加载符号半字 | lh rd, imm(rs1) |
16-bit | Zca + Zcb | |
c.sb |
c.sb rs2, rs1(imm) |
存储字节数据 | sb rs2, imm(rs1) |
8-bit | Zca + Zcb | |
c.sh |
c.sh rs2, rs1(imm) |
存储半字数据 | sh rs2, imm(rs1) |
16-bit | Zca + Zcb | |
| 浮点加载/存储 | c.flw |
c.flw rd, rs1(imm) |
加载单精度浮点数 | flw rd, imm(rs1) |
32-bit | Zca + F + Zcf |
c.fsw |
c.fsw rs2, rs1(imm) |
存储单精度浮点数 | fsw rs2, imm(rs1) |
32-bit | Zca + F + Zcf | |
c.flwsp |
c.flwsp rd, imm(sp) |
基于栈指针加载单精度浮点数 | flw rd, imm(sp) |
32-bit | Zca + F + Zcf | |
c.fswsp |
c.fswsp rs2, imm(sp) |
基于栈指针存储单精度浮点数 | fsw rs2, imm(sp) |
32-bit | Zca + F + Zcf | |
c.fld |
c.fld rd, rs1(imm) |
加载双精度浮点数 | fld rd, imm(rs1) |
64-bit | Zca + D + Zcd | |
c.fsd |
c.fsd rs2, rs1(imm) |
存储双精度浮点数 | fsd rs2, imm(rs1) |
64-bit | Zca + D + Zcd | |
c.fldsp |
c.fldsp rd, imm(sp) |
基于栈指针加载双精度浮点数 | fld rd, imm(sp) |
64-bit | Zca + D + Zcd | |
c.fsdsp |
c.fsdsp rs2, imm(sp) |
基于栈指针存储双精度浮点数 | fsd rs2, imm(sp) |
64-bit | Zca + D + Zcd | |
| 特殊功能 | c.nop |
c.nop |
空操作指令 | addi x0, x0, 0 |
- | Zca |
c.ebreak |
c.ebreak |
触发调试断点 | ebreak |
- | Zca | |
c.zext.b |
c.zext.b rd |
字节零扩展 | andi rd, rd, 0xFF |
- | Zca + Zcb | |
c.sext.b |
c.sext.b rd |
字节符号扩展 | 专用优化序列 | - | Zca + Zcb | |
c.zext.h |
c.zext.h rd |
半字零扩展 | 专用优化序列 | - | Zca + Zcb | |
c.sext.h |
c.sext.h rd |
半字符号扩展 | 专用优化序列 | - | Zca + Zcb | |
c.not |
c.not rd |
按位取反操作 | xori rd, rd, -1 |
- | Zca + Zcb |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号