
第四次作业
业①:
o 要求:
熟练掌握Selenium查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
o 候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
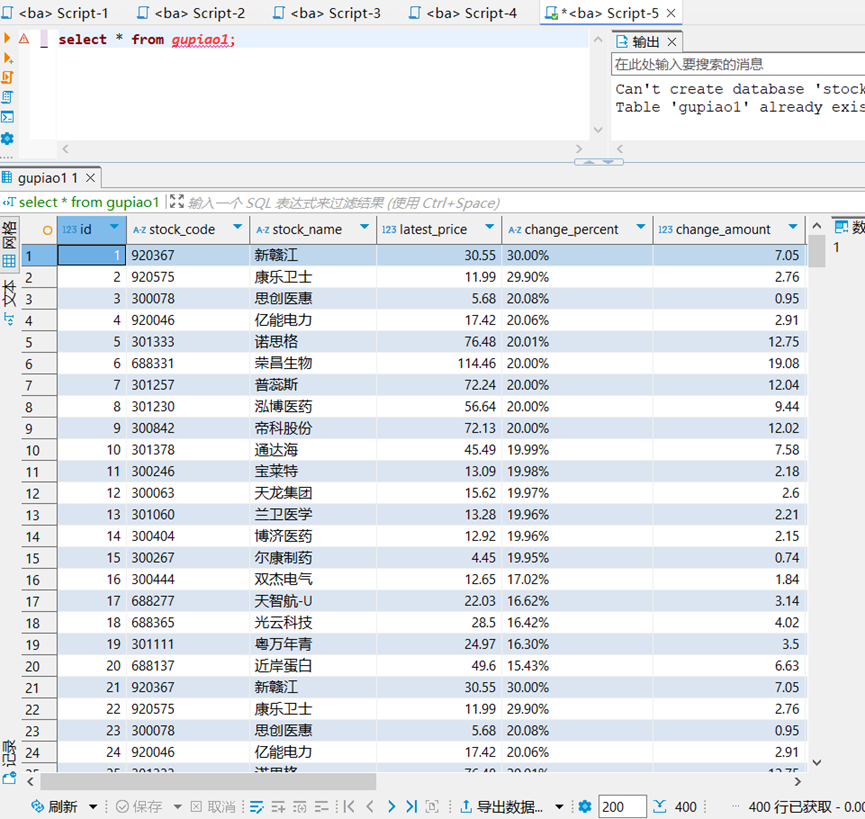
o 输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
首先查找Xpath,进入网站,点击F12,在弹出来的页面的右上角找到箭头并点击,然后点击沪深京个股,在elements中搜索相关名字,就能找到对应的Xpath
沪深京A股
上证A股
深证A股
>
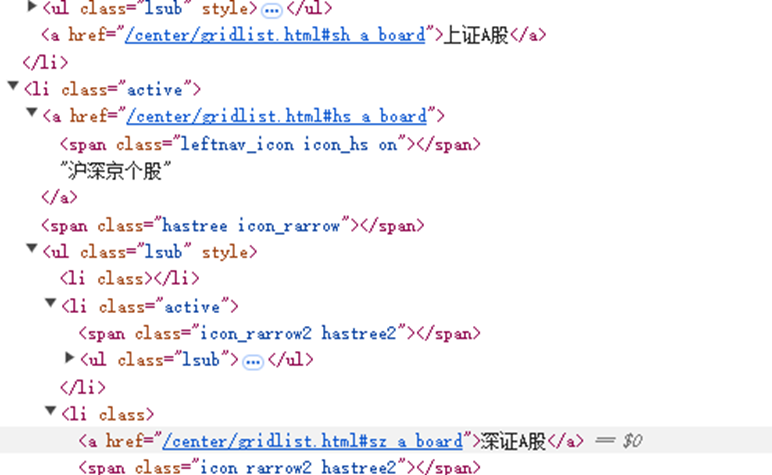
然后用同样的方法点击下一页按钮,就能中找到下一页的Xpath

程序运行前需要下载Chrome
核心代码
` def scrape_board(self, board_code, board_name):
"""爬取指定板块的数据"""
logger.info(f"\n{'=' * 60}")
logger.info(f"开始爬取 {board_name} ({board_code})")
logger.info(f"{'=' * 60}")
# 构造板块URL
url = f"{self.base_url}#{board_code}"
logger.info(f"访问URL: {url}")
try:
self.driver.get(url)
# 等待页面完全加载
self.random_delay(3, 5)
# 等待表格加载
table_element = self.wait_for_table_load()
if not table_element:
logger.error(f"表格加载失败: {board_name}")
return []
# 滚动页面以确保内容加载
self.driver.execute_script("window.scrollTo(0, document.body.scrollHeight/3);")
self.random_delay(2, 3)
self.driver.execute_script("window.scrollTo(0, document.body.scrollHeight/2);")
self.random_delay(2, 3)
except Exception as e:
logger.error(f"访问页面失败: {e}")
return []
stock_data = []
page_num = 1
max_pages = 10 # 限制爬取页数,避免无限循环
while page_num <= max_pages:
logger.info(f"正在处理 {board_name} 第 {page_num} 页...")
# 尝试多种XPath定位策略
row_selectors = [
'//div[@class="listview"]//table/tbody/tr',
'//table[contains(@class, "table")]/tbody/tr',
'//div[contains(@class, "dataview")]//tr',
'//table/tbody/tr',
'//tbody/tr',
'//tr[contains(@class, "row")]'
]
rows = []
for selector in row_selectors:
try:
rows = self.driver.find_elements(By.XPATH, selector)
if rows and len(rows) > 5: # 确保找到足够多的行
logger.info(f"使用选择器找到 {len(rows)} 行数据: {selector}")
break
except Exception:
continue
if not rows or len(rows) < 5:
logger.warning(f"第 {page_num} 页未找到足够数据行,尝试重新查找...")
# 尝试重新加载
try:
self.driver.refresh()
self.random_delay(3, 5)
rows = self.driver.find_elements(By.XPATH, row_selectors[0])
except Exception:
break
# 解析每一行数据
page_records = 0
for i, row in enumerate(rows):
try:
# 跳过表头行
row_class = row.get_attribute("class") or ""
if "head" in row_class.lower() or "header" in row_class.lower():
continue
# 获取所有单元格
cells = row.find_elements(By.XPATH, './/td')
if len(cells) < 10: # 至少需要10个单元格
# 尝试其他定位方式
cells = row.find_elements(By.TAG_NAME, "td")
if len(cells) < 10:
continue
# 提取数据 - 根据实际网页结构调整索引
stock_info = self.extract_stock_info(cells, board_name)
if stock_info:
stock_data.append(stock_info)
page_records += 1
except StaleElementReferenceException:
logger.warning(f"第{i + 1}行元素已过时,跳过...")
continue
except Exception as e:
logger.warning(f"解析第{i + 1}行数据时出错: {e}")
continue
logger.info(f"第 {page_num} 页解析完成,获得 {page_records} 条记录")
# 尝试查找并点击下一页 - 更新了选择器,优先使用 data-pi="2"
try:
next_button = None
next_selectors = [
'//a[@data-pi="2"]', # 优先使用这个选择器
'//a[@title="下一页"]',
'//a[contains(text(), "下一页")]',
'//a[contains(@class, "next")]',
'//button[contains(text(), "下一页")]',
'//a[text()=">"]'
]
for selector in next_selectors:
try:
next_button = self.driver.find_element(By.XPATH, selector)
if next_button.is_displayed() and next_button.is_enabled():
logger.info(f"找到下一页按钮,使用选择器: {selector}")
break
else:
next_button = None
except:
continue
if not next_button:
logger.info(f"{board_name} 没有下一页按钮,爬取完成")
break
# 检查按钮是否禁用
button_class = next_button.get_attribute("class") or ""
if "disabled" in button_class or "禁" in button_class:
logger.info(f"{board_name} 已到最后一页")
break
# 点击下一页
logger.info("点击下一页...")
self.driver.execute_script("arguments[0].scrollIntoView();", next_button)
self.random_delay(1, 2) # 修正了拼写错误
next_button.click()
# 等待下一页加载
self.random_delay(4, 6) # 增加等待时间
page_num += 1
# 每3页添加一个额外等待
if page_num % 3 == 0:
self.random_delay(5, 8)
except ElementClickInterceptedException:
logger.warning("下一页按钮点击被拦截,尝试JavaScript点击")
try:
self.driver.execute_script("arguments[0].click();", next_button)
self.random_delay(4, 6)
page_num += 1
except:
logger.error("JavaScript点击也失败,停止翻页")
break
except NoSuchElementException:
logger.info(f"{board_name} 没有找到下一页按钮,爬取完成")
break
except Exception as e:
logger.error(f"翻页时出错: {e}")
break
logger.info(f"{board_name} 数据爬取完成,共 {len(stock_data)} 条记录")
return stock_data`
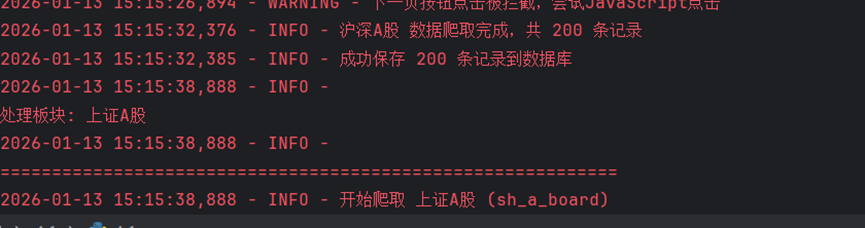
运行结果

• 作业②:
o 要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
o 候选网站:中国mooc网:https://www.icourse163.org
获取登录,课程信息等xpath
核心代码`# 从URL提取课程ID
if '/course/' in course_url:
parts = course_url.split('/course/')
if len(parts) > 1:
course_data['course_id'] = parts[1].split('?')[0]
# 爬取课程名称
try:
# 尝试多种可能的XPath选择器
name_selectors = [
"//h1[contains(@class, 'course-title')]",
"//div[contains(@class, 'course-title')]",
"//h1[@class='u-course-title']",
"//h1"
]
for selector in name_selectors:
try:
course_name_elem = self.driver.find_element(By.XPATH, selector)
if course_name_elem.text.strip():
course_data['course_name'] = course_name_elem.text.strip()
break
except:
continue
if not course_data['course_name']:
# 从URL中提取课程名
course_data['course_name'] = course_url.split('/')[-1].replace('-', ' ')
except Exception as e:
logger.warning(f"获取课程名称失败: {e}")
# 爬取学校名称
try:
university_selectors = [
"//a[contains(@class, 'u-course-university')]",
"//div[contains(@class, 'university')]",
"//span[contains(text(), '大学') or contains(text(), '学院')]",
"//a[contains(@href, 'university')]"
]
for selector in university_selectors:
try:
uni_elem = self.driver.find_element(By.XPATH, selector)
if uni_elem.text.strip():
course_data['university_name'] = uni_elem.text.strip()
break
except:
continue
except Exception as e:
logger.warning(f"获取学校名称失败: {e}")
# 爬取主讲教师和团队成员
try:
teacher_selectors = [
"//div[contains(@class, 'teacher')]",
"//span[contains(text(), '教授') or contains(text(), '老师')]",
"//div[contains(@class, 'lecturer')]"
]
teachers = []
for selector in teacher_selectors:
try:
teacher_elems = self.driver.find_elements(By.XPATH, selector)
for elem in teacher_elems:
if elem.text.strip() and len(elem.text.strip()) < 50: # 防止抓到太长文本
teachers.append(elem.text.strip())
except:
continue
if teachers:
course_data['main_teacher'] = teachers[0] if len(teachers) > 0 else ''
course_data['team_members'] = '; '.join(teachers[1:]) if len(teachers) > 1 else ''
except Exception as e:
logger.warning(f"获取教师信息失败: {e}")
# 爬取参加人数
try:
participants_selectors = [
"//span[contains(text(), '人参加')]",
"//div[contains(text(), '人参加')]",
"//span[contains(@class, 'participants')]"
]
for selector in participants_selectors:
try:
participants_elem = self.driver.find_element(By.XPATH, selector)
text = participants_elem.text.strip()
# 提取数字
import re
numbers = re.findall(r'\d+', text)
if numbers:
course_data['participants_count'] = int(''.join(numbers[:3]))
break
except:
continue
except Exception as e:
logger.warning(f"获取参加人数失败: {e}")
# 爬取课程进度
try:
progress_selectors = [
"//span[contains(text(), '进行至')]",
"//div[contains(text(), '第') and contains(text(), '周')]",
"//span[contains(@class, 'progress')]"
]
for selector in progress_selectors:
try:
progress_elem = self.driver.find_element(By.XPATH, selector)
if progress_elem.text.strip():
course_data['course_progress'] = progress_elem.text.strip()
break
except:
continue
except Exception as e:
logger.warning(f"获取课程进度失败: {e}")
# 爬取课程简介
try:
# 根据你提供的HTML结构
description_selectors = [
"//span[contains(@style, 'font-size: 16px; font-family: 宋体')]",
"//div[contains(@class, 'course-description')]",
"//div[contains(@class, 'overview')]",
"//meta[@name='description']/@content"
]
for selector in description_selectors:
try:
if selector.startswith('//meta'):
desc_elem = self.driver.find_element(By.XPATH, "//meta[@name='description']")
description = desc_elem.get_attribute('content')
else:
desc_elem = self.driver.find_element(By.XPATH, selector)
description = desc_elem.text.strip()
if description:
course_data['course_description'] = description[:1000] # 限制长度
break
except:
continue
except Exception as e:
logger.warning(f"获取课程简介失败: {e}")
return course_data
except Exception as e:
logger.error(f"爬取课程详情失败 {course_url}: {e}")
return None
def scrape_course_list(self, start_url="https://www.icourse163.org"):
"""爬取课程列表"""
try:
self.driver.get(start_url)
time.sleep(3)
# 等待页面加载
self.wait.until(EC.presence_of_element_located((By.TAG_NAME, "body")))
# 查找课程链接
course_links = []
# 多种可能的课程链接选择器
link_selectors = [
"//a[contains(@href, '/course/')]",
"//a[contains(@class, 'course-card')]",
"//div[contains(@class, 'course-item')]//a"
]
for selector in link_selectors:
try:
links = self.driver.find_elements(By.XPATH, selector)
for link in links:
href = link.get_attribute('href')
if href and '/course/' in href and href not in course_links:
course_links.append(href)
if course_links: # 如果找到链接就停止
break
except:
continue
logger.info(f"找到 {len(course_links)} 个课程链接")
return course_links[:10] # 限制爬取数量,防止被封
except Exception as e:
logger.error(f"爬取课程列表失败: {e}")
return []`
运行结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号