
第三次作业
• 作业①:
– 要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
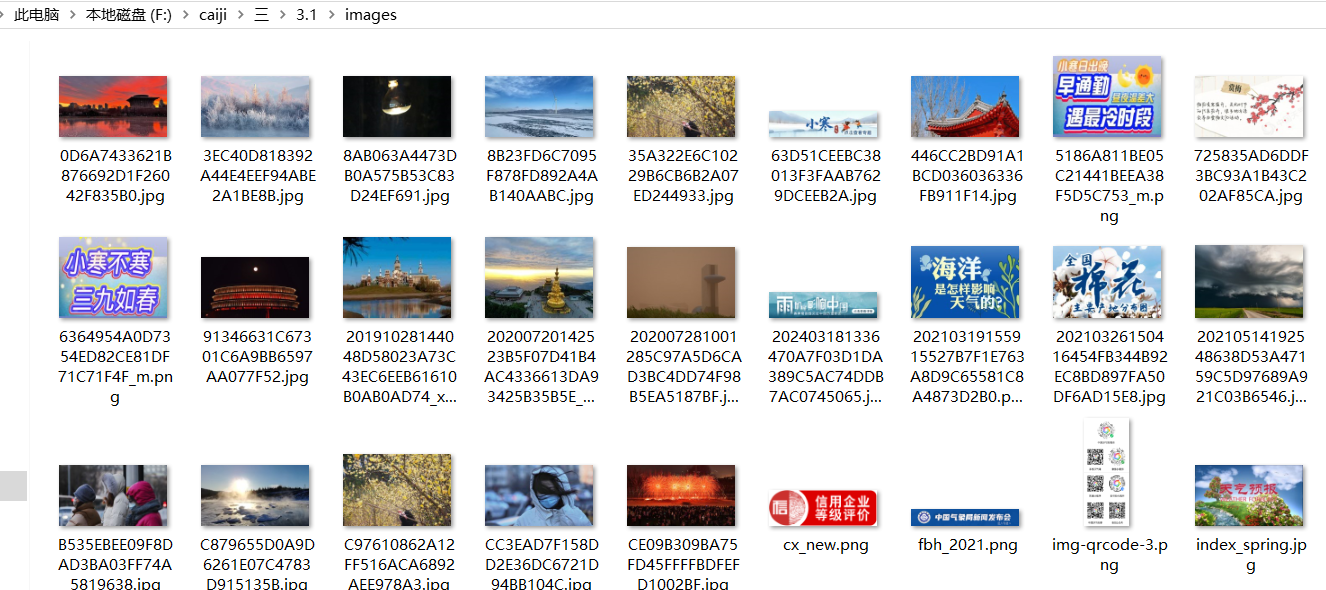
– 输出信息:将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
核心代码`def download_image(img_url, save_dir):
"""下载单张图片并保存到指定目录"""
try:
# 设置请求头,模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
response = requests.get(img_url, headers=headers, timeout=10)
response.raise_for_status() # 检查请求是否成功
# 从URL提取图片文件名
filename = os.path.join(save_dir, os.path.basename(urlparse(img_url).path))
# 如果文件名不包含扩展名,尝试从Content-Type推断
if not os.path.splitext(filename)[1]:
content_type = response.headers.get('content-type')
if content_type and 'image' in content_type:
ext = content_type.split('/')[-1]
filename = f"{filename}.{ext if ext != 'jpeg' else 'jpg'}"
# 保存图片
with open(filename, 'wb') as f:
f.write(response.content)
return img_url, filename, None
except Exception as e:
return img_url, None, str(e)
def single_threaded_crawl(url, save_dir):
"""单线程爬取"""
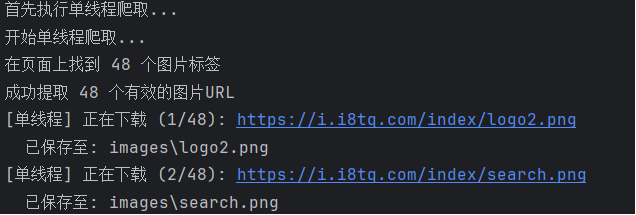
print("开始单线程爬取...")
try:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
img_tags = soup.find_all('img')
print(f"在页面上找到 {len(img_tags)} 个图片标签")
# 收集所有有效的图片URL
img_urls = []
for img in img_tags:
src = img.get('src') or img.get('data-src') # 有些图片可能存储在data-src属性中
if src:
# 转换为绝对URL
full_url = urljoin(url, src)
if is_valid_url(full_url):
img_urls.append(full_url)
print(f"成功提取 {len(img_urls)} 个有效的图片URL")
# 单线程下载
for i, img_url in enumerate(img_urls, 1):
print(f"[单线程] 正在下载 ({i}/{len(img_urls)}): {img_url}")
original_url, saved_path, error = download_image(img_url, save_dir)
if error:
print(f" 下载失败: {error}")
else:
print(f" 已保存至: {saved_path}")
return len(img_urls)
except Exception as e:
print(f"单线程爬取过程中发生错误: {e}")
return 0
def multi_threaded_crawl(url, save_dir, max_workers=5):
"""多线程爬取"""
print(f"\n开始多线程爬取 (最大线程数: {max_workers})...")
try:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
img_tags = soup.find_all('img')
print(f"在页面上找到 {len(img_tags)} 个图片标签")
# 收集所有有效的图片URL
img_urls = []
for img in img_tags:
src = img.get('src') or img.get('data-src')
if src:
full_url = urljoin(url, src)
if is_valid_url(full_url):
img_urls.append(full_url)
print(f"成功提取 {len(img_urls)} 个有效的图片URL")
# 多线程下载
successful = 0
failed = 0
with ThreadPoolExecutor(max_workers=max_workers) as executor:
# 提交所有下载任务
future_to_url = {executor.submit(download_image, img_url, save_dir): img_url
for img_url in img_urls}
# 处理完成的任务
for i, future in enumerate(as_completed(future_to_url), 1):
img_url = future_to_url[future]
original_url, saved_path, error = future.result()
if error:
print(f"[多线程] 下载失败 ({i}/{len(img_urls)}): {img_url}")
print(f" 错误信息: {error}")
failed += 1
else:
print(f"[多线程] 下载成功 ({i}/{len(img_urls)}): {original_url}")
print(f" 保存路径: {saved_path}")
successful += 1
print(f"\n多线程下载完成! 成功: {successful}, 失败: {failed}")
return successful
except Exception as e:
print(f"多线程爬取过程中发生错误: {e}")
return 0`
运行结果
• 作业②
– 要求:熟练掌握scrapy中Item、Pipeline数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
– 候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
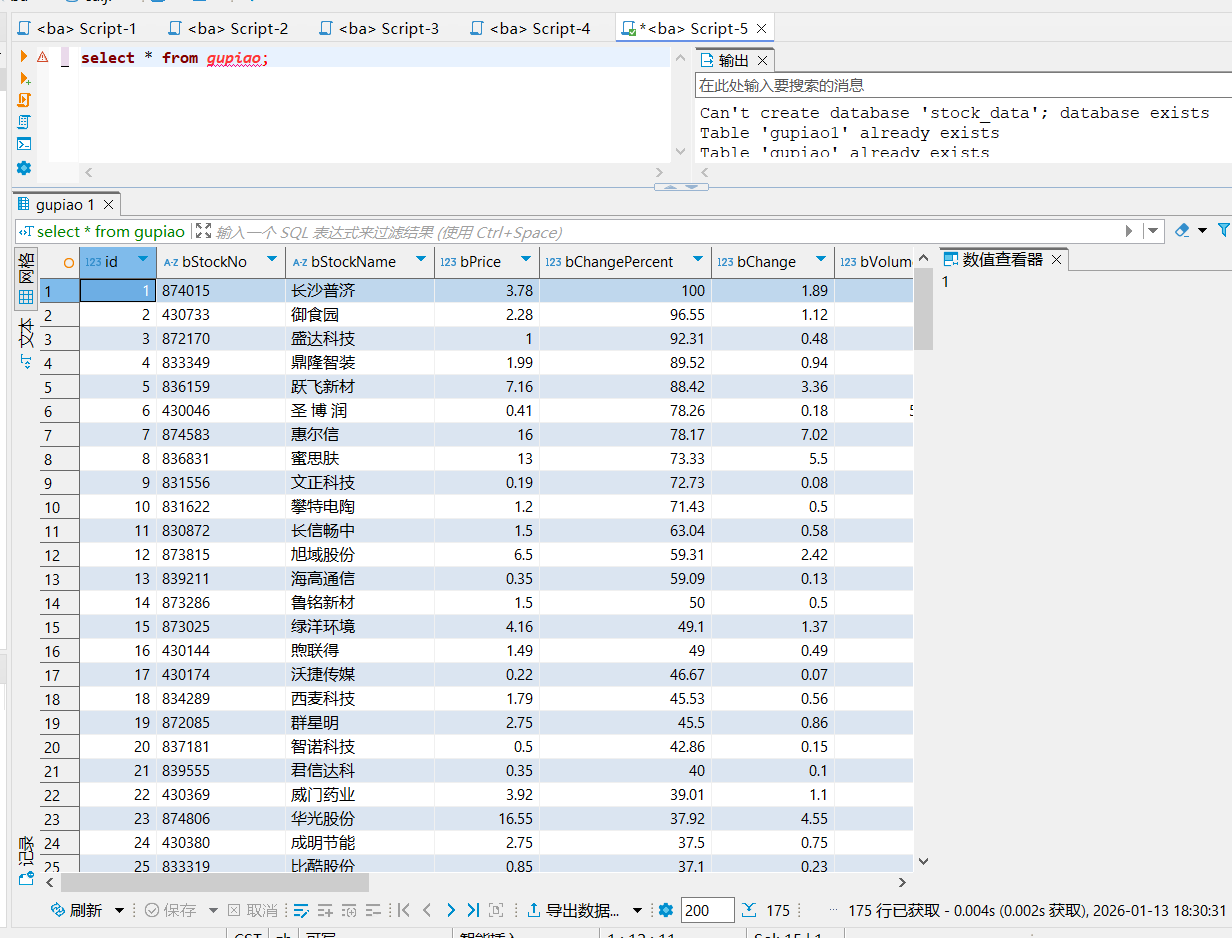
– 输出信息:MySQL数据库存储和输出格式如下:表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 振幅 最高 最低 今开 昨收
1 688093 N世华 28.47 10.92 26.13万 7.6亿 22.34 32.0 28.08 30.20 17.55
2……
选择东方财富网
核心代码
`import scrapy
import json
import time
from ..items import GupiaoItem
class EastmoneyStockSpider(scrapy.Spider):
name = 'eastmoney'
allowed_domains = ['push2.eastmoney.com']
def start_requests(self):
"""生成起始请求"""
base_url = 'http://89.push2.eastmoney.com/api/qt/clist/get'
for page in range(1, 10): # 先爬取前9页测试
params = {
'pn': str(page),
'pz': '20',
'po': '1',
'np': '1',
'ut': 'bd1d9ddb04089700cf9c27f6f7426281',
'fltt': '2',
'invt': '2',
'fid': 'f3',
'fs': 'm:0 t:6,m:0 t:80,m:1 t:2,m:1 t:23,m:0 t:81 s:2048',
'fields': 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152',
'_': str(int(time.time() * 1000))
}
# 构建完整的URL
url = f"{base_url}?{'&'.join([f'{k}={v}' for k, v in params.items()])}"
yield scrapy.Request(
url=url,
callback=self.parse,
meta={'page': page}
)
def parse(self, response):
"""解析响应数据"""
try:
data = json.loads(response.text)
stocks = data.get('data', {}).get('diff', [])
if not stocks:
self.logger.warning(f"第 {response.meta['page']} 页没有数据")
return
self.logger.info(f"第 {response.meta['page']} 页获取到 {len(stocks)} 条股票数据")
for idx, stock in enumerate(stocks):
item = GupiaoItem()
# 计算序号
page = response.meta['page']
item['id'] = (page - 1) * 20 + idx + 1
# 解析各个字段
item['bStockNo'] = stock.get('f12', '') # 股票代码
item['bStockName'] = stock.get('f14', '') # 股票名称
item['bPrice'] = stock.get('f2', 0) # 最新价
item['bChangePercent'] = stock.get('f3', 0) # 涨跌幅
item['bChange'] = stock.get('f4', 0) # 涨跌额
item['bVolume'] = stock.get('f5', 0) # 成交量(手)
item['bTurnover'] = stock.get('f6', 0) # 成交额
item['bAmplitude'] = stock.get('f7', 0) # 振幅
item['bHigh'] = stock.get('f15', 0) # 最高
item['bLow'] = stock.get('f16', 0) # 最低
item['bOpen'] = stock.get('f17', 0) # 今开
item['bPrevClose'] = stock.get('f18', 0) # 昨收
item['bPE'] = stock.get('f9', 0) # 市盈率
item['bPB'] = stock.get('f22', 0) # 市净率
item['bMarketCap'] = stock.get('f20', 0) # 总市值
item['bCirculationMarketCap'] = stock.get('f21', 0) # 流通市值
# 添加时间戳
from datetime import datetime
item['bUpdateTime'] = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
yield item
except json.JSONDecodeError as e:
self.logger.error(f"JSON解析错误: {e}")
self.logger.error(f"响应内容: {response.text[:500]}")`
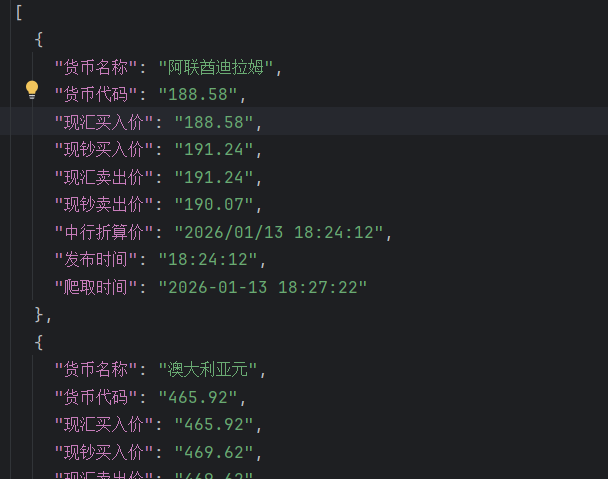
运行结果
• 作业③:
– 要求:熟练掌握scrapy中Item、Pipeline数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
– 候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
核心代码
`class BocForexSpider(scrapy.Spider):
name = 'boc_forex'
allowed_domains = ['boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
# 自定义设置
custom_settings = {
'ITEM_PIPELINES': {
'boc_forex_scraper.pipelines.MySQLPipeline': 300,
'boc_forex_scraper.pipelines.JsonWriterPipeline': 400,
},
'DOWNLOAD_DELAY': 2, # 下载延迟,避免被封
'CONCURRENT_REQUESTS': 1,
'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
def parse(self, response):
"""
解析外汇数据页面
"""
# 获取表格中的所有行(跳过表头)
rows = response.xpath('//table[@class="publishTable"]//tr')
for row in rows[1:]: # 跳过表头行
columns = row.xpath('./td')
if len(columns) >= 7: # 确保有足够的数据列
item = ForexItem()
# 使用XPath提取数据
item['currency_name'] = columns[0].xpath('string(.)').get().strip()
item['currency_code'] = columns[1].xpath('string(.)').get().strip()
item['buying_rate'] = columns[2].xpath('string(.)').get()
item['cash_buying_rate'] = columns[3].xpath('string(.)').get()
item['selling_rate'] = columns[4].xpath('string(.)').get()
item['cash_selling_rate'] = columns[5].xpath('string(.)').get()
item['boc_rate'] = columns[6].xpath('string(.)').get()
item['publish_time'] = columns[7].xpath('string(.)').get()
# 添加爬取时间
item['crawl_time'] = datetime.now()
yield item
# 可以添加分页逻辑(如果需要爬取历史数据)
# next_page = response.xpath('//a[@class="next"]/@href').get()
# if next_page:
# yield scrapy.Request(url=response.urljoin(next_page), callback=self.parse)
class BocHistoricalSpider(scrapy.Spider):
"""
如果需要爬取历史数据,可以使用这个爬虫
"""
name = 'boc_forex_historical'
def start_requests(self):
# 生成历史日期范围
base_url = 'https://www.boc.cn/sourcedb/whpj/index{}.html'
# 假设网站有分页,格式为index1.html, index2.html等
for page in range(1, 10): # 爬取前10页
url = base_url.format(page) if page > 1 else 'https://www.boc.cn/sourcedb/whpj/'
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
# 使用相同的解析逻辑
rows = response.xpath('//table[@class="publishTable"]//tr')
for row in rows[1:]:
columns = row.xpath('./td')
if len(columns) >= 7:
item = ForexItem()
item['currency_name'] = columns[0].xpath('string(.)').get().strip()
item['currency_code'] = columns[1].xpath('string(.)').get().strip()
item['buying_rate'] = columns[2].xpath('string(.)').get()
item['cash_buying_rate'] = columns[3].xpath('string(.)').get()
item['selling_rate'] = columns[4].xpath('string(.)').get()
item['cash_selling_rate'] = columns[5].xpath('string(.)').get()
item['boc_rate'] = columns[6].xpath('string(.)').get()
item['publish_time'] = columns[7].xpath('string(.)').get()
item['crawl_time'] = datetime.now()
yield item`
运行结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号