浅谈原理--hashCode方法
我们时常会判断一个元素是否相等重复,可以用equals方法。
每增加一个元素,我们就可以通过equals方法判断集合中的每一个元素是否重复,但是如果集合中有10000个元素了,我们每添加一个元素的时候,就需要进行10000此的equals方法的调用,显示效率非常的低下了。
于是基于这种问题,java集合的设计者采用了哈希表来实现。
哈希表也称为散列算法,是依据数据特定算法产生的结果直接指定到一块地址上,这个结果由hashCode方法产生。
这样一来,当集合每添加一个新的元素的时候,就可以通过hashCode方法直接定位到该存放的物理位置上,而不需要大量的equals板的比较。
上面说到了hashCode方法,它是Object类中的一个被native修饰的方法,
那么也就是说,我们每个对象都会继承了这个方法,我们也就可以重写它了
Object类的hashCode方法代码:
public native int hashCode();
hashCode的比较方式
比如下方是在用HashSet存值
- 计算出来的位置上,如果这个位置上没有元素,它就可以直接存储在这个位置上了,不用进行任何的比较
- 如果这个位置有元素了,就调用它的(这个对象)equals方法与新的元素进行比较,相同的话就不存了
- 如果equals方法比较后,不相同,也就是放生了hashKey相同,导致冲突的情况。那么就在这个hashKey的地方产生一个链表,将所有产生相同的hashKey的对象添加到这个链表上,串在一起(很少会出现)。这样一来实际上我们调用equals方法的几率就大大降低了。
下面以简单的图来表示
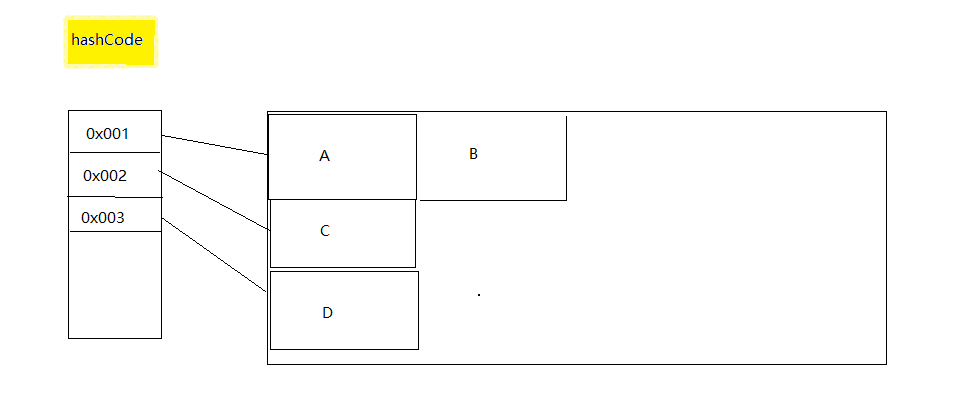
这里有A B C D四个对象,分别通过hashCode方法产生了3个值
注意A和B对象调用hashCode产生的值是相同的,即 A.hashCode = B.hashCode()= 0x001
发生了哈希冲突,这时候由于最先插入了A,在插入B的时候,我们发现B要插入A的位置,而A已经插入,也就是这个位置已经有对象了。
这个时候就通过调用equals方法判断A和B是否相同,如果相同就不插入B,如果不同则将B插入到A后面的位置。
所以对于equals方法和hashCode方法有如下的要求:
一、hashCode要求
- 在程序运行期间,只要对象(字段)变化不会影响到equals方法的决策结果,那么在这个期间,无论调用多少次hashCode,都必须返回相同的散列码的hashCode
- 通过equals调用返回true的2个对象的hashCode一定相同
- 通过equals返回false的2个对象的hashCode不需要不同,也就是允许hashCode相同。
因此得到以下结论
- 两个对象相等,其hashCode一定相同
- 两个对象不相等,其hashCode可能相等
- hashCode相等的两个对象,不一定相同
- hashCode不相等的两个对象,一定不同
可能会有人疑问,对于不能重复的集合,为什么不直接通过 hashCode 对于每个元素都产生唯一的值,如果重复就是相同的值,这样不就不需要调用 equals 方法来判断是否相同了吗?
实际上对于元素不是很多的情况下,直接通过 hashCode 产生唯一的索引值,通过这个索引值能直接找到元素,而且还能判断是否相同。比如数据库存储的数据,ID 是有序排列的,我们能通过 ID 直接找到某个元素,如果新插入的元素 ID 已经有了,那就表示是重复数据,这是很完美的办法。但现实是存储的元素很难有这样的 ID 关键字,也就很难这种实现 hashCode 的唯一算法,再者就算能实现,但是产生的 hashCode 码是非常大的,这会大的超过 Java 所能表示的范围(因为返回值是int类型,大小只能是232),很占内存空间,所以也是不予考虑的。
二、重写hashCode
我们应该注意:
- 不同对象的hashCode码应该尽量不同,避免hash冲突,也就是算法获得元素要尽量均匀。
- hash值是一个int类型,在java中占用4个字节,也就是232 次方,要避免溢出
下面是String的hashCode实现
public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h; }
这里有个数字 31 ,为什么选择31作为乘积因子,而且没有用一个常量来声明?主要原因有两个:
①、31是一个不大不小的质数,是作为 hashCode 乘子的优选质数之一。
②、31可以被 JVM 优化,31 * i = (i << 5) - i。因为移位运算比乘法运行更快更省性能。
具体解释可以参考这篇文章。
ps:
对于Map集合,我们可以选择Java中的基本类型,还有引用类型String作为key,因为它们都按照规范重写了equals方法和hashCode方法。
但是如果我们自定义对象作为key,那么一定要覆盖equals方法和hahshCode方法,要不然会有未知的suprise等着你。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号