

DBC python解析
由于设计自定义开发,使用系统库经常遇到格式/占位问题,一气之下结合AI自定义一个类,够用即可,不够续加代码解析。
测试结果:
常规解析结果跟系统库一致的,但是由于懒得判断,统一使用float来处理,结果显示多个0其实无碍
2025-07-25 修改:eval接口尽量不用,否则解码速度很低,最好约定标准格式
Intel格式
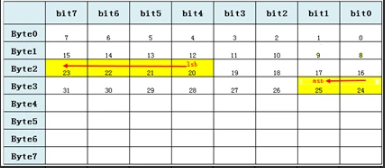
Intel格式即小端,MSB存放在高字节单元,反映到矩阵图中就是以起始位为原点,自上而下填充。Intel格式,msb在lsb下面。
比如46这个数字,换为二进制为:101110,长度为6个bit
如果起始位为20的话,那么格式如下图:对应CAN数据为:00 00 E0 02 00 00 00
Motorola格式
Motorola格式即大端,MSB存放在低字节单元,反映到矩阵图中就是以起始位为原点,自下而上填充。Motorola格式,msb在lsb上面。
Motorola_LSB排列格式
比如46这个数字,换为二进制为:101110,长度为6个bit
如果起始位为20的话,那么格式如下图:对应CAN数据为:00 02 E0 00 00 00 00

Motorola_MSB排列格式
比如46这个数字,换为二进制为:101110,长度为6个bit
如果起始位为20的话,那么格式如下图:对应CAN数据为:00 00 17 00 00 00 00

描述取自:Intel格式与Motorola格式的区别 - 哔哩哔哩 (bilibili.com)
import re
from typing import Optional, Tuple
class DBCParser:
"""解析DBC文件并存储其中的报文和信号信息"""
def __init__(self):
self.messages = {} # 存储报文信息:message_id -> message_info
self.signal_formulas = {} # 存储信号的物理值计算公式:(message_id, signal_name) -> formula_info
def parse(self, file_path: str) -> None:
"""
解析DBC文件
Args:
file_path: DBC文件路径
"""
import chardet
with open(file_path, "rb") as f:
result = chardet.detect(f.read(10000)) # 检测前10KB内容
with open(file_path, 'r', encoding = result['encoding']) as file:
lines = file.readlines()
i = 0
while i < len(lines):
line = lines[i].strip()
# 解析报文定义
if line.startswith("BO_ "):
message_id = int(line.split()[1])
message_name = line.split()[2].rstrip(':')
message_size = int(line.split()[3])
# 收集报文中的信号行
signals = []
i += 1
while i < len(lines) and lines[i].strip().startswith("SG_ "):
signals.append(lines[i].strip())
i += 1
# 解析信号
parsed_signals = {}
for signal_line in signals:
signal_info = self._parse_signal(signal_line)
parsed_signals[signal_info["name"]] = signal_info
# 存储报文信息
self.messages[message_id] = {
"name" : message_name,
"size" : message_size,
"signals": parsed_signals
}
# 解析信号值描述(可选)
# 解析信号值描述(可选)
elif line.startswith("VAL_ "):
# 这里可以添加对信号值描述的解析
val_pattern = re.compile(r'VAL_\s+(\d+)\s+(\w+)\s+(.*?)\s*;', re.DOTALL)
val_entries = val_pattern.findall(line)
for msg_id, sig_name, val_def in val_entries: # 取决于自定义格式
if int(msg_id) not in self.messages.keys():
continue # 不符合原来的属性
dsig = self.messages[int(msg_id)]['signals']
if sig_name not in dsig.keys():
continue # 不符合原来的属性
# 解析数值与描述的映射
dsig[sig_name]['val_map'] = {}
parts = re.findall(r'(\d+)\s+"([^"]*)"', val_def)
for num_val, text_desc in parts:
dsig[sig_name]['val_map'][float(num_val)] = text_desc
i += 1
# 解析信号计算公式
elif line.startswith("BA_DEF_ SG_ "):
i += 1
# 解析信号CM_
elif line.startswith("CM_"):
# 解析信号注释
sg_comments = re.findall(r'^\s*CM_\s.+?\s(.+?)\s(.+?)\s"([^"]*)"', line)
for msg_id, sig_name, comment in sg_comments:
if int(msg_id) not in self.messages.keys():
continue # 不符合原来的属性
dsig = self.messages[int(msg_id)]['signals']
if sig_name not in dsig.keys():
continue # 不符合原来的属性
# 解析数值与描述的映射 长命
dsig[sig_name]['lname'] = comment
i += 1
else:
i += 1
def _parse_signal(self, line: str) -> dict:
"""解析信号定义行"""
def get_val_typ(ssval: str, ityp=0):
sval = ssval.replace(' ', '')
if ityp == 0:
return int(sval)
else:
return float(sval)
lre = re.compile(r'^\s*SG_\s(.+?):\s(.+?)\|(.+?)@(.+?)([+-]).?\((.+?),(.+?)\).?\[(.+?)\|(.+?)\].?"([^"]*)"(.*)', re.IGNORECASE)
fre = lre.findall(line, endpos = len(line))[0]
if len(fre):
start_bit = get_val_typ(fre[1])
bit_length = get_val_typ(fre[2])
# 提前预解析
isbig_msb = True
if '0' in fre[3]: # @0 为大端
# big_msb 不是顺序bit big_lsb 是反向解析
cal_start_bit = (start_bit // 8) * 8 + (7 - start_bit % 8)
cal_end_bit = cal_start_bit + bit_length
else:
cal_start_bit = start_bit
cal_end_bit = start_bit + bit_length
return {
"name" : str(fre[0]).strip(),
"cal_s_bit" : cal_start_bit,
"cal_e_bit": cal_end_bit,
"isbig_or": '0' in fre[3], # @0 为大端
"isigned" : '-' in fre[4],
"isbig_msb" : isbig_msb,
"sign_mask": 1 << (bit_length - 1),
"sign_val": 1 << bit_length,
"factor" : get_val_typ(fre[5], 1),
"offset" : get_val_typ(fre[6], 1),
"min" : get_val_typ(fre[7], 1),
"max" : get_val_typ(fre[8], 1),
"unit" : fre[9]
}
return {}
def _parse_formula_definition(self, line: str) -> Optional[dict]:
"""解析公式定义"""
if "GenSigFunc" not in line:
return None
# 提取公式名称
formula_name_match = re.search(r'"([^"]*)"', line)
if not formula_name_match:
return None
formula_name = formula_name_match.group(1)
# 提取参数
param_pattern = r'$([^)]+)$'
param_match = re.search(param_pattern, line)
if not param_match:
return None
params = [p.strip() for p in param_match.group(1).split(",")]
return {
"name" : formula_name,
"params": params
}
def _parse_signal_formula(self, line: str, formula_info: dict) -> Tuple[int, str]:
"""解析信号的公式应用"""
# 提取消息ID和信号名称
pattern = r'BA_\s+"{}"\s+SG_\s+(\d+)\s+(\w+);'.format(formula_info["name"])
match = re.search(pattern, line)
if not match:
return None
message_id = int(match.group(1))
signal_name = match.group(2)
# 将公式与特定信号关联
self.signal_formulas[(message_id, signal_name)] = {
"formula_name": formula_info["name"],
"params" : formula_info["params"]
}
return (message_id, signal_name)
def get_message_info(self, message_id: int) -> dict:
"""获取报文信息"""
return self.messages.get(message_id, None)
def get_all_messages(self) -> dict:
"""获取所有报文信息"""
return self.messages
def parse_data(self, message_id: int, recv_data: bytes) -> dict:
"""
解析原始CAN数据帧,返回各信号的物理值
Args:
message_id: 报文ID
recv_data: 原始CAN数据 (bytes, 长度为1~8)
Returns:
dict: {信号名: 物理值}
"""
if message_id not in self.messages.keys():
# raise ValueError(f"未找到报文ID {hex(message_id)} 的定义")
return {}
signals = self.messages[message_id].get("signals", {})
result = {}
int_allbits = ''
big_allbits = ''
for i in recv_data:
bits = f"{i:08b}"
big_allbits += bits
int_allbits += bits[::-1]
for signal_name, signal_info in signals.items():
if signal_info["isbig_or"] :
cal_value = big_allbits[signal_info['cal_s_bit']: signal_info['cal_e_bit']]
if not signal_info['isbig_msb']:
cal_value = cal_value[::-1]
else:
cal_value = int_allbits[signal_info['cal_s_bit']: signal_info['cal_e_bit']][::-1]
cal_value = int(cal_value, 2) # 2为底的
# 6. 处理有符号数(补码)
if signal_info["isigned"] and cal_value & signal_info["sign_mask"]:
cal_value -= signal_info["sign_val"]
# 7. 应用公式计算物理值
end_val = signal_info['factor'] * cal_value + signal_info['offset']
if end_val > signal_info["max"]:
end_val = signal_info["max"]
elif end_val < signal_info["min"]:
end_val = signal_info["min"]
if signal_info.get('val_map', False):
end_val = signal_info['val_map'].get(end_val, end_val)
signal_name = signal_info.get('lname', signal_name)
result[signal_name] = (end_val, str(signal_info['unit']).replace('N/A', ''))
return result
# 使用示例
if __name__ == "__main__":
data = bytearray([33] * 8)
msg_id = 100
parser = DBCParser()
parser.parse("tets.dbc") # 替换为实际的DBC文件路径
parsed_values = parser.parse_data(msg_id, data)
for signal, value in parsed_values.items():
print(f"解码 {signal}: {value}")
VERSION "1.0"
NS_ :
NS_DESC_
CM_
BA_DEF_
BA_
VAL_
CAT_DEF_
CAT_
FILTER
BA_DEF_DEF_
EV_DATA_
ENVVAR_DATA_
SGTYPE_
SGTYPE_VAL_
BA_DEF_SGTYPE_
BA_SGTYPE_
SIG_TYPE_REF_
VAL_TABLE_
SIG_GROUP_
SIG_VALTYPE_
SIGTYPE_VALTYPE_
BO_TX_BU_
BA_DEF_REL_
BA_REL_
BA_DEF_DEF_REL_
BU_SG_REL_
BU_EV_REL_
BU_BO_REL_
SG_MUL_VAL_
BS_:
BU_: Engine ECU Transmission
BO_ 100 EngineSpeedMsg: 8 Engine
SG_ Signal1 : 0|8@0+ (1,0) [0|255000000] "Unit1" ECU2
SG_ Signal2 : 20|16@0+ (1,0) [0|25500000] "Unit1" ECU2
import re
from typing import Optional, Tuple
class DBCParser:
"""解析DBC文件并存储其中的报文和信号信息"""
def __init__(self):
self.messages = {} # 存储报文信息:message_id -> message_info
self.signal_formulas = {} # 存储信号的物理值计算公式:(message_id, signal_name) -> formula_info
def parse(self, file_path: str) -> None:
"""
解析DBC文件
Args:
file_path: DBC文件路径
"""
import chardet
with open(file_path, "rb") as f:
result = chardet.detect(f.read(10000)) # 检测前10KB内容
with open(file_path, 'r', encoding = result['encoding']) as file:
lines = file.readlines()
i = 0
while i < len(lines):
line = lines[i].strip()
# 解析报文定义
if line.startswith("BO_ "):
message_id = int(line.split()[1])
message_name = line.split()[2].rstrip(':')
message_size = int(line.split()[3])
# 收集报文中的信号行
signals = []
i += 1
while i < len(lines) and lines[i].strip().startswith("SG_ "):
signals.append(lines[i].strip())
i += 1
# 解析信号
parsed_signals = {}
for signal_line in signals:
signal_info = self._parse_signal(signal_line)
parsed_signals[signal_info["name"]] = signal_info
# 存储报文信息
self.messages[message_id] = {
"name" : message_name,
"size" : message_size,
"signals": parsed_signals
}
# 解析信号值描述(可选)
# 解析信号值描述(可选)
elif line.startswith("VAL_ "):
# 这里可以添加对信号值描述的解析
val_pattern = re.compile(r'VAL_\s+(\d+)\s+(\w+)\s+(.*?)\s*;', re.DOTALL)
val_entries = val_pattern.findall(line)
for msg_id, sig_name, val_def in val_entries: # 取决于自定义格式
if int(msg_id) not in self.messages.keys():
continue # 不符合原来的属性
dsig = self.messages[int(msg_id)]['signals']
if sig_name not in dsig.keys():
continue # 不符合原来的属性
# 解析数值与描述的映射
dsig[sig_name]['val_map'] = {}
parts = re.findall(r'(\d+)\s+"([^"]*)"', val_def)
for num_val, text_desc in parts:
dsig[sig_name]['val_map'][float(num_val)] = text_desc
i += 1
# 解析信号计算公式
elif line.startswith("BA_DEF_ SG_ "):
i += 1
# 解析信号CM_
elif line.startswith("CM_"):
# 解析信号注释
sg_comments = re.findall(r'^\s*CM_\s.+?\s(.+?)\s(.+?)\s"([^"]*)"', line)
for msg_id, sig_name, comment in sg_comments:
if int(msg_id) not in self.messages.keys():
continue # 不符合原来的属性
dsig = self.messages[int(msg_id)]['signals']
if sig_name not in dsig.keys():
continue # 不符合原来的属性
# 解析数值与描述的映射 长命
dsig[sig_name]['lname'] = comment
i += 1
else:
i += 1
def _parse_signal(self, line: str) -> dict:
"""解析信号定义行"""
def get_val_typ(ssval: str, ityp=0):
sval = ssval.replace(' ', '')
if ityp == 0:
return int(sval)
else:
return float(sval)
lre = re.compile(r'^\s*SG_\s(.+?):\s(.+?)\|(.+?)@(.+?)([+-]).?\((.+?),(.+?)\).?\[(.+?)\|(.+?)\].?"([^"]*)"(.*)', re.IGNORECASE)
fre = lre.findall(line, endpos = len(line))[0]
if len(fre):
start_bit = get_val_typ(fre[1])
bit_length = get_val_typ(fre[2])
# 提前预解析
isbig_msb = True
if '0' in fre[3]: # @0 为大端
# big_msb 不是顺序bit big_lsb 是反向解析
cal_start_bit = (start_bit // 8) * 8 + (7 - start_bit % 8)
cal_end_bit = cal_start_bit + bit_length
else:
cal_start_bit = start_bit
cal_end_bit = start_bit + bit_length
return {
"name" : str(fre[0]).strip(),
"cal_s_bit" : cal_start_bit,
"cal_e_bit": cal_end_bit,
"isbig_or": '0' in fre[3], # @0 为大端
"isigned" : '-' in fre[4],
"isbig_msb" : isbig_msb,
"sign_mask": 1 << (bit_length - 1),
"sign_val": 1 << bit_length,
"factor" : get_val_typ(fre[5], 1),
"offset" : get_val_typ(fre[6], 1),
"min" : get_val_typ(fre[7], 1),
"max" : get_val_typ(fre[8], 1),
"unit" : fre[9]
}
return {}
def _parse_formula_definition(self, line: str) -> Optional[dict]:
"""解析公式定义"""
if "GenSigFunc" not in line:
return None
# 提取公式名称
formula_name_match = re.search(r'"([^"]*)"', line)
if not formula_name_match:
return None
formula_name = formula_name_match.group(1)
# 提取参数
param_pattern = r'$([^)]+)$'
param_match = re.search(param_pattern, line)
if not param_match:
return None
params = [p.strip() for p in param_match.group(1).split(",")]
return {
"name" : formula_name,
"params": params
}
def _parse_signal_formula(self, line: str, formula_info: dict) -> Tuple[int, str]:
"""解析信号的公式应用"""
# 提取消息ID和信号名称
pattern = r'BA_\s+"{}"\s+SG_\s+(\d+)\s+(\w+);'.format(formula_info["name"])
match = re.search(pattern, line)
if not match:
return None
message_id = int(match.group(1))
signal_name = match.group(2)
# 将公式与特定信号关联
self.signal_formulas[(message_id, signal_name)] = {
"formula_name": formula_info["name"],
"params" : formula_info["params"]
}
return (message_id, signal_name)
def get_message_info(self, message_id: int) -> dict:
"""获取报文信息"""
return self.messages.get(message_id, None)
def get_all_messages(self) -> dict:
"""获取所有报文信息"""
return self.messages
def parse_data(self, message_id: int, recv_data: bytes) -> dict:
"""
解析原始CAN数据帧,返回各信号的物理值
Args:
message_id: 报文ID
recv_data: 原始CAN数据 (bytes, 长度为1~8)
Returns:
dict: {信号名: 物理值}
"""
if message_id not in self.messages.keys():
# raise ValueError(f"未找到报文ID {hex(message_id)} 的定义")
return {}
signals = self.messages[message_id].get("signals", {})
result = {}
int_allbits = ''
big_allbits = ''
for i in recv_data:
bits = f"{i:08b}"
big_allbits += bits
int_allbits += bits[::-1]
for signal_name, signal_info in signals.items():
if signal_info["isbig_or"] :
cal_value = big_allbits[signal_info['cal_s_bit']: signal_info['cal_e_bit']]
if not signal_info['isbig_msb']:
cal_value = cal_value[::-1]
else:
cal_value = int_allbits[signal_info['cal_s_bit']: signal_info['cal_e_bit']][::-1]
cal_value = int(cal_value, 2) # 2为底的
# 6. 处理有符号数(补码)
if signal_info["isigned"] and cal_value & signal_info["sign_mask"]:
cal_value -= signal_info["sign_val"]
# 7. 应用公式计算物理值
end_val = signal_info['factor'] * cal_value + signal_info['offset']
if end_val > signal_info["max"]:
end_val = signal_info["max"]
elif end_val < signal_info["min"]:
end_val = signal_info["min"]
if signal_info.get('val_map', False):
end_val = signal_info['val_map'].get(end_val, end_val)
signal_name = signal_info.get('lname', signal_name)
result[signal_name] = (end_val, str(signal_info['unit']).replace('N/A', ''))
return result
本文来自博客园,作者:{archer},转载请注明原文链接:https://www.cnblogs.com/archer-mowei/p/18976368

 浙公网安备 33010602011771号
浙公网安备 33010602011771号