红书推荐系列(三):System R
前
1970年,Codd提出用一套关系代数来表示数据库查询管理问题引起了广泛关注,当时有一些以关系代数为原型的系统被开发证明了Codd理论的正确性,但是还没有一个适用于整个数据库的系统出现。1972年,IBM开发了System R应该是第一个完整的关系型查询处理系统(没有严谨查证过)。System R对后来的数据库设计影响深远,尤其是事务部分的实现仍被今天的商用数据库采用。此外System R的查询优化技术也成了现代数据库优化的标准。
Architecture
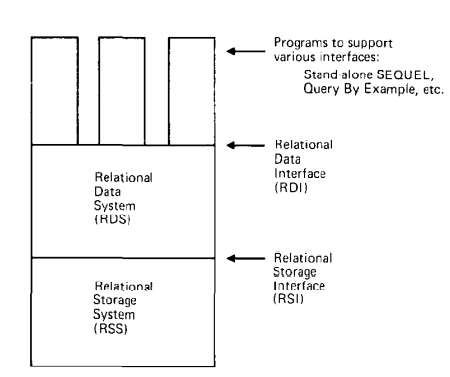
System R的架构已经可以看见现代数据库的雏形,它将数据库分为三个部分:用户程序、关系数据系统(RDS)、关系存储系统(RSS),和两个接口:关系数据接口(RDI)、关系存储系统(RSI),如上如所示。
RDS是RDI的实现,负责身份认证、事务、数据校验、触发机制等功能。RSS是RSI的实现,负责存储空间管理、事务控制、锁机制和系统恢复等功能。站在现在的角度看,System R的模块拆分有点糟糕,RSS包含了很多其它模块的功能。当然,这不是我们关注的重点,System R有不少设计都显得过时,这里点名批评System R的RDI,暴露给用户太多的细节(比如Cursor),运行一个简单的SQL查询要写一大串代码。
System R开发时期,SQL还处于早期发展时期,所以paper花费了大量的笔墨介绍了SQL的用法,从现在看来,这一部分我们没有详细介绍的必要了,对SQL早期发展感兴趣的同学可以读一下System R的介绍。
我们主要关注System R的optimizer和transaction manager两个最经典的部分。
Optimizer
System R的optimizer非常经典,数据库早期查询优化有两个方向。一个是SQL被解析后成中间代码后,优化中间代码,就像汇编语言的优化那样。这种方法和当时编译器的思想相同。第二个优化方向就是System R提出的cost-based。
为找到一个代价较低(花费时间较少)的查询执行方案,System R计算二级存储中加载到内存中的page的期望数和CPU运行指令的代价,通过比较不同执行路径的代价,选出代价最低的路径。
Optimizer在计算代价路径时,需要考虑以下几点:
- R:表的tuple数量
- D:表所占的page的数量
- T:每个page包含的平均数量(R/D)
- I:索引中不同的检索字段的数量
- H:CPU的运行效率
Optimizer根据可使用的索引来决定使用哪种扫描方式:
- 连续索引,且比较运算符为'=',那么取得所有tuple的期望花费为为R/(T×I)次page访问。
- 连续索引,且比较运算符不为'='。假设有一半的tuple满足条件,那么期望花费为R/(2×T)。
- 非连续索引,且比较运算符为’=‘。那么期望花费为R/I。
- 非连续索引,且比较运算符不为'='。期望花费为R/2。
- 连续索引,且索引和预测表达式不匹配。期望花费为(R/T)+H×R×N,其中N为预测条件数。
- 非连续索引,且索引和预测表达式不匹配。期望花费为R+H×R×N。
- 直接扫描且没有其它的表。期望花费为(R/T)+H×R×N。
- 直接扫描且和其它的表共享资源。花费未知,但大于(R/T)+H×R×N。
Optimizer根据以下规则选择上面的一种方法:
- 如果方法一可用,选择方法一。
- 如果方法二、三、五、七可用,选择其中代价最小的。
- 如果上面两条都不满足,那么按顺序寻找方法四、六、八,如果有可用的就直接选择。
例子2:列出住在Evanston的程序员的名字、工资和部门名称。
SELECT NAME, SAL, DNAME FROM EMP, DEPT WHERE EMP.JOB = 'PROGRAMMER' AND DEPT.LOC = 'EVANSTON' AND EMP.DNO = DEPT.DNO
这个例子中涉及到了JOIN运算,我们这里考虑四种可能的运算方法。
- Nested loop。循环每一对DEPT和EMP的值,如果符合上述条件,那么将该对的值加入结果。
- Merge join。选出所有EMP中符合EMP.JOB='PROGRAMMER'的行,选出DEPT中所有符合DEPT.LOC='EVANSTON'的行,对这两个结果排序,再对排序后的结果做join运算。
- multiple passes。这个方法我可能没见过,尴尬。如果内存中能装下所有符合条件的DEPT的行,那么把这些数据全部装入内存中,如果不行,选择DNO最小的行装入内存中,再遍历EMP进行比对。
- TID算法。每个表只保存符合条件的tuple ID值TID,再对TID进行遍历。(感觉这种方法好蠢)
这些方法需要在适合的时候才能使用,比如有些方法需要用到索引(我没写出来)才能使用。下面我们讨论一下上述各个方法适用的情况。
- 当EMP.DNO和DEPRT.DNO都有连续索引,且EMP.JOB和DEPT.LOC没有时,总是选择方法一。
- 当EMP.DNO和DEPRT.DNO都有非连续索引,且EMP.JOB和DEPT.LOC没有时,如果方法三能够装下所有的tuple,就使用方法三,否则就使用方法二。
- 当EMP.DNO和DEPRT.DNO都有连续索引,且EMP.JOB和DEPT.LOC也有非连续索引时,总是选择方法一。
- 当EMP.DNO,DEPRT.DNO,EMP.JOB和DEPT.LOC都有非连续索引时,如果方法三能够装下所有的tuple,就使用方法三,否则如果每个disk page期望存有超过一个满足条件的tuple,就选择方法二,否则选择方法四。
以上我们看到System R中已经出现了比较完整的基于代价的优化选择,虽然和今天的算法略有区别,但毫无疑问地确立了DBMS优化器的核心方法,为以后DBMS的高效运行提供了保证。
Transaction Manager
Transaction manager是System R另外一个重大贡献,目前仍有许多的商业数据库还沿用其设计。
Transaction是RSI作为一个用户向RSS发送的一系列调用。一个RSS transaction以START_TRANS开头,以END_TRANS结尾。Transaction也提供了恢复机制,使得transaction能够退回到任意一个save point,这一点在长transaction中尤其有用。Transaction的save point通过SAVE_TRANS标记。Transaction recovery发生在RDS或Monitor产生一个RESTORE_TRANS命令。
并发控制
System R中的并发控制分别从逻辑上和物理上描述了控制方法,这里我不明白为什么要分成两个部分,感觉将的是同一个方面。保持并发的方法简单的说就是加锁,至于怎么加锁可以参考红书的后面一篇paper,也可以看看我的随笔。
多个事务并行时,一致性度有多个等级,但System R和后面的一致性划分好像有点不一样,这里还是记录一下。
Level 1 脏数据可以被其它事务读。
Level 2 事务读的都是被提交的数据。
Level 3 可线性化。
Checkpoint和recovery
数据库设置备份点是一个非常耗时的操作,System R用两种方法来缓解这个问题。第一种用硬盘数据恢复内存数据丢失,第二种是用tape恢复硬盘数据。第一种方法感觉像是WAL,第二种方法我不大了解,所以不确定这个技术现在是否还在使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号