红书推荐系列(二):Architecture of a Database System
前
数据库管理系统(DBMS)一直以来作为计算机的重要部分,在工业界和学术界都经过了长时间的发展,里面许多的设计技术如scalability、reliability都用到了其它的系统里。
The Life of a Query
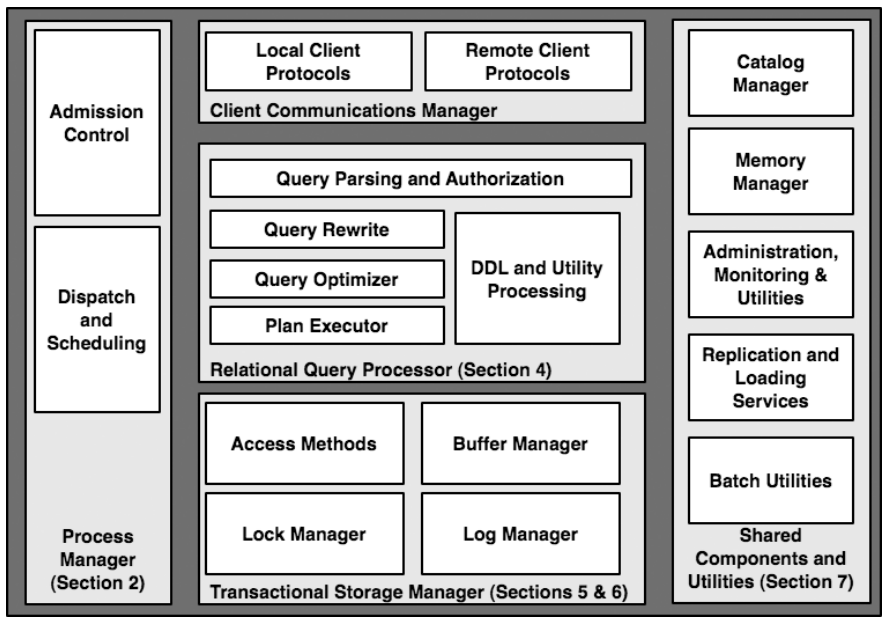
数据库管理系统,尤其是关系型数据库管理系统(RDBMS)在当前的绝大多数应用中都占据核心地位。RDBMS有5个核心组件(如上图所示)。对于一个简单查询,处理流程如下:
- Client和DBMS建立连接,发送SQL命令。连接的方法有很多种,比如直接连接、通过网络连接、ODBC连接、通过代理连接。
- 一旦收到了SQL命令,DBMS就分配一个线程(进程亦可)执行该命令。这部分的工作由上图左边完成,包括访问权限、分配足够的计算资源,如果计算资源不够,这部分会等到足够的资源才开始继续计算。
- 一旦被分配的线程开始工作,就进入到查询处理阶段。这个阶段先将查询文本编译成查询plan,然后执行该plan。
- 在执行该plan的过程中会涉及到数据的存取,这一部分由上图的底部完成,其中的transaction保证也在这一部分完成。
- 最后,查询结果被存入一个buffer中,等待发给client。
Process Models
单处理器
多用户模型一直是数据库管理系统重点之一。为简化问题,假设CPU只有一个核,一个DBMS只有一个process,但是有多个thread。
一个DBMS有三种进程模型:每个worker单线程、每个worker单进程、进程池。
单worker单进程
单进程模型出现的很早,因为可以直接调用OS的进程接口,由OS scheduler安排每个worker的工作时间。同时进程间内存独立、锁、缓存等功能也由OS提供。
单进程模型在大规模用户缺乏扩展性,目前支持这种模型的数据库有DB2,PostgreSQL,Oracle。
单worker单线程
worker每收到一个连接请求,就单独分配一个线程来处理这个请求任务。
单线程的问题在于内存空间不独立,难以debug,race condition等问题。
进程池
与单进程不同的是,进程池保持一定数量的进程,当线程超过这个数量时,就需要等待其它进程结束才能开始执行。
Shared Data and Process Boundaries
数据共享对于单线程模式非常方便,但是对于其它的模式就很麻烦。对于三种进程模型,将数据从DBMS移动到client会涉及到许多buffer。单实际上,所有的共享数据都会设计缓冲区。
Disk I/O buffer是所有的模型都会涉及到的,因为所有的模型肯定可以访问同一数据库下所有的数据。Disk buffer主要分为两类:数据库请求、日志请求。
对于数据库请求,共享数据通过所有worker都可以访问的内存地址进行交流,也即Buffer Pool。
对于日志请求,日志在transaction中会产生日志,这些日志先被存在内存中(log tail),然后周期性的被写入disk中。
在线程模型中,log tail以堆中数据结构存在。在其它进程模型中,通过共享内存来交流日志。
Lock table在所有的worker中共享。
Parallel process and memory coordination
多进程的存储模式分为三种:shared-memory,shared-nothing,shared-disk,分别对应三种不同程度的数据共享模式。
NUMA
Non-Uniform Memory Access(NUMA)提供了一种cluster中带有独立内存的共享内存编程模型。Cluster内的每个system都可以快速本地内存,但是要访问其它内存速度会相对降低。
Relational Query Processor
Query Parsing and Authorization
当paser得到一个SQL语句后,做的事情有:
- 检查SQL语句正确。
- 解决名字和引用。
- 将语句转换成optimizer使用的内部格式。
- 确认用户有权限执行该语句。
对于一个SQL语句,parser首先考虑的就是FROM子句里的表引用,它将表的名称完全展开成server.database.schema.table的格式(根据不同的DB,格式会略有不同)。
然后query processor在catalog manager中找表是否存在,catalog的信息通常会存在一个只存有catalog的cache中,避免在访问大规模数据时被数据换出。
此外,数据类型也会被用来确定一些有歧义的表达式,比如(salary * 1.15) < 7500,这个式子中根据salary属于整型还是浮点数会调用不同的乘法函数。
Query Rewrite
Rewriter要做的事情很多,但是在实际的DB中rewriter的功能要么在parser部分,要么在optimizer部分。但作为逻辑上单独的一个模块,我们关注一下它的职责即可。
- 展开VIEW。这个是rewriter最重要的工作,递归地把VIEW中的表名、表达式展开,直到最后没有VIEW可以再展开。
- 常数计算。把一些常量计算出来,如1+2这个表达式可以直接用3替代。再PostgreSQL中,这部分的功能是在optimizer的预处理部分完成的。
- 逻辑重写。将可以在编译时期可以直接推算结果的表达式重写,如salary<1000 AND salary>2000可以直接用false替代。
- 子查询展开。子查询展开是为了保证最终的表达式的简洁,即SELECT FROM WHERE格式,以便最终的optimizer优化。
Query Optimizer
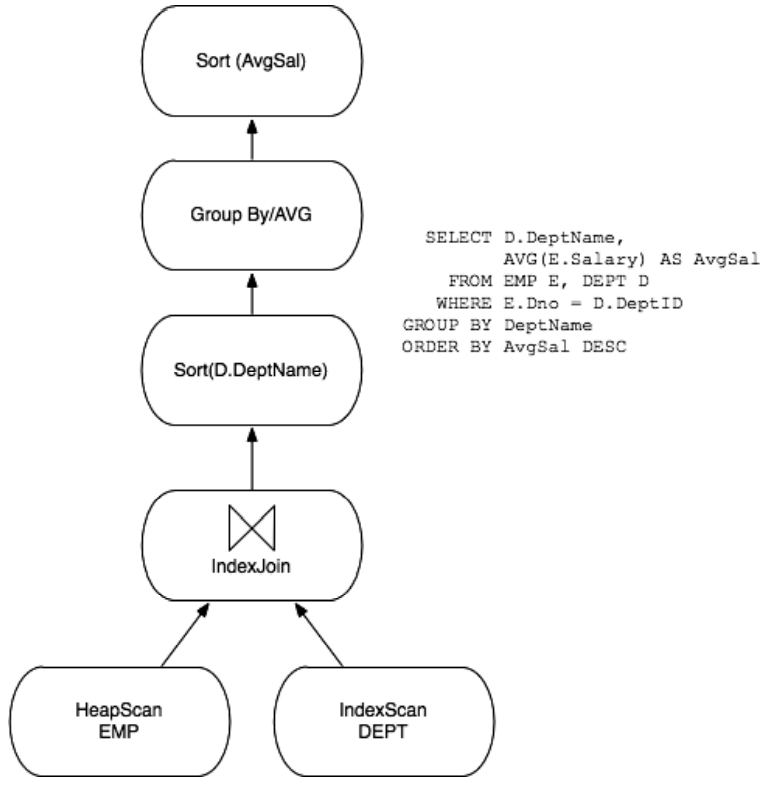
查询计划是以流程图的形式生成的,高层结点不断地从底层结点取得数据,取得数据计算完后将结果交给更上层的结点。过去的优化形式有两种,一种是优化System R生成的字节码,另一种是优化是优化生成的中间计划。历史证明后者比较符合历史发展潮流。现在的优化方向主要有以下几个:
- Plan space:早期的System R采用左递归的优化方式,同时将需要做笛卡尔积的运算向后推迟。
- Selectivity estimation:过去的selectivity estimation比较简陋,现在会用到包括数据分布等统计数据来估计,也有很多其它新技术,但是很少会被用在实际的生产中。
- Search Algorithm:一些商用数据库已经抛弃了动态规划优化,但是他们采用的优化我不是很了解,就不多说了。
- Parallelism:大多数数据库支持并行处理。很多数据库也支持内查询:通过多个处理器加速一个查询的方法。为了降低复杂度,常见的并行优化是:先生成单进程优化,再将优化结果分配给多个处理器执行。
- Auto Tuning:自动调节是工业界一直在尝试改进的ability。
Query Executor
Executor负责执行生成的计划,作用像是一个解释器,觉得大多数的executor都是以迭代器模式执行的,一个简化的迭代器如下所示:

Iterator
迭代器的一个重要的特点就是数据流和控制流的合并。高层结点向低层结点发送数据请求,底层结点收到请求后计算结果,然后将结果返回给高层结点,同时低层结点的结束控制。由于worker通常是单线程的,所以executor的设计十分的简洁高效,对于多线程或者多进程的解决方案也存在,比如利用生产者消费者模型,这里就不多说了。
修改数据
一般来说修改数据是比较简单的,只需要直接修改表就可以。但是存在一些情况就需要注意,比如著名的万圣节问题。万圣节问题最早是由System R小组在万圣节当天发现的,问题来自于类似“让工资低于2000的员工工资涨10%”这类修改。当executor通过B+树访问工资时,被涨过的员工工资如果还低于2000就会再次被修改,直到所有的员工工资都超过2000。
解决这种问题的方法有很多。一种简单有效的方法是让optimizer发现有索引的修改直接查找整个表,而不使用索引,但这种方法很多情况下会很低效。另一种方案是批量读写,即预先存下需要搜寻的数据,然后查找预存的数据,在实际数据上进行修改。还有一种方法是针对pipline传输数据的,就是采用多版本控制来保证不会重复修改。
Access Methods
Access methods负责文件访问,包括堆数据和索引访问。现在的数据存在多种不同的索引类型,包括最基本的B+树,对于很多其他格式的数据如文本文件、多重维度数据,也有专门的索引来维持。
最基本的access method提供的接口就是iterator接口,如上图所示。其中init()方法可以接受“search argument”(System R称之为SARG)。如果SARG为NULL,那么就扫描全表。传递SARG的原因有两个。一是一些索引需要SARG传递需要的参数,二是为了性能考虑。比如SARG不传递给下层函数,那么每次下层函数返回结果时,要么将结果放在buff page里(pin值加一),要么放在堆里。如果返回的结果不是期望得到的,那么buff page的pin值会被减一,或者把堆中结果销毁,然后再次调用下层函数。显然,这些步骤十分的耗时。
Database Extensibility
过去数据库存储的数据格式受到严重限制缺乏扩展性,这种情况现在改善了很多,这里点名表扬PostgreSQL。
Abstract Data Types
抽象数据类型的支持需要在runtime扩展,为了能够实现扩展性,DBMS在parser阶段就需要借助system catalog来实现数据类型的扩展,这种方法中DBMS没有不需要interpret类型,只要调用对应的需要的函数就可以。
Storage Management
DBMS的存储管理有两种,一种是直接控制硬盘,所有的写入读出等操作都是由数据库完成,另一种是利用OS提供的硬盘抽象来管理存储。
Spatial Control
硬盘需要管理的原因有很多。硬盘顺序读取速度是随机读取的7到100倍。硬盘的速度增长速度相对CPU、内存来说要慢得多:存储量每18个月翻一倍,访问速度每年增长7%。DBMS通常也比底层的OS更加了解自己的工作模式。因此DBMS对硬盘的控制是很必要的。
但是,直接控制硬盘虽然可以达到极限性能,但也存在一些缺点。首先,需要DBA将一块raw磁盘直接划给DBMS,这样就导致了磁盘的这块不能被OS使用,里面的数据也不能被其它软件复用。同时,磁盘访问接口也要随着OS的不同而变化,导致DB迁移性很差。最后一些新性的存储结构,如RAID、SAN等变得更加流行。这样看来,随着以后发展,对硬盘进行直接控制越来越没有必要。
一种可行的控制裸磁盘的替代方案是向OS申请一个超大的文件,DBMS在内件内划分空间用来存储,这种方法的缺点下一节讨论。
在TPC-C的测试中,大文件方案仅仅比裸磁盘方案慢6%,因此大文件方案更加的受欢迎。
Temporal Control
DBMS除了控制磁盘数据存储空间外,还控制数据写入磁盘时间。数据写入时机交给OS处理也是不合理的,OS并不知道合适的写入时机,所以会造成问题。比如ACID保证的失效后的需要保证原子恢复。另一个问题是OS只关注性能,而不在乎数据的正确性。最后就是就是双缓存问题。就直观上来说,何时写入内存本身就是一件值得商榷的事。
Buffer Management
为实现高效的读取数据,一个高效的共享缓冲池是很必要的。早期缓冲池的大小是由管理员静态设置的,如今大多数DBMS都可以根据需要动态调整缓冲区大小。
缓冲区通常是由一串连续的frame构成,每个frame对应一个磁盘区域(block)。每个block会原封不动地复制到frame中,以避免CPU产生格式转换的开销。
Frame通过hash表快速查找,这个hash表将page number映射向具体的某一帧、page在磁盘上的位置以及一些元数据(包括页面是否dirty、pin count等信息)。
早期的系统对页面置换算法的研究有很多,因为OS的页面置换算法如LRU、CLOCK并不知道哪些frame接下来还会被用到,可能会换出一些马上会使用的frame,对于数据库来说会造成性能下降。现代的数据库页面置换算法会根据页面类型的不同选择不同的置换策略。
Transactions: Concurrency Control and Recovery
数据库绝大多数组件接口的设计非常明确,除了transaction模块。Transaction有四个部分组成:
- 负责并行控制的锁管理器。
- 负责恢复的日志管理器。
- 降低I/O读写的缓冲池。
- 访问磁盘数据的方法。
这部分涉及到相当多的细节以及协议,我不能保证能够完整清晰的表达所有的内容,所幸作者给我们推荐了从入门到进阶的阅读材料,按难度顺序如下:
- R. Ramakrishnan and J. Gehrke, “Database management systems,” McGrawHill, Boston, MA, Third ed., 2003.
- C. Mohan, D. J. Haderle, B. G. Lindsay, H. Pirahesh, and P. M. Schwarz, “Aries: A transaction recovery method supporting fine-granularity locking and partial rollbacks using write-ahead logging,” ACM Transactions on Database Systems (TODS), vol. 17, pp. 94–162, 1992.
- M. Kornacker, C. Mohan, and J. M. Hellerstein, “Concurrency and recovery in generalized search trees,” in Proceedings of ACM SIGMOD International Conference on Management of Data, pp. 62–72, Tucson, AZ, May 1997.
- C. Mohan, “Aries/kvl: A key-value locking method for concurrency control of multiaction transactions operating on b-tree indexes,” in 16th International Conference on Very Large Data Bases (VLDB), pp. 392–405, Brisbane, Queensland, Australia, August 1990.
- J. Gray and A. Reuter, Transaction Processing: Concepts and Techniques. Morgan Kaufmann, 1993.
以上推荐材料都很经典,虽然我都没读过,以后找个时间补上,但毫无疑问,这些材料对个人的知识体系架构非常重要,此外,想要成为相关方便的专家,需要自己动手实现一遍。
A Note on ACID
ACID指Atomicity、Consistency、Isolation、Durability。这四个术语并没有准确的定义,所以也没必要完全区别这些术语的关系和区别(我师兄以前还问我为什么要ACID这四个性质,为什么缺一不可,我怀疑他在欺负我不懂(lll¬ω¬))。
为了后面讨论方便,这里给出ACID的大概定义。
- Atomicity:“all or nothing”,一个transaction要么全部完成,要么完全不做。
- Consistency:Consistency并没有统一的定义,这里我们认为只要保持数据库一致状态即可。
- Isolation:Isolation保证了两个transaction在执行的过程中看不见彼此。
- Durability:持久性要求更新过的数据能够被其它transaction看见。
现代DBMS通过lock机制实现isolation,通过loggin and recovery实现durability,isolation和atomicity也通过locking和logging保证。Consistency需要依靠executor在运行时保证。
A Brief Review of Serializability
Serializability是数据库中实现数据库并行控制的方法之一。Serializability指的是一些交错运行的transaction的结果就像是线性执行的一样。一般serializability有三种技术实现。
- Strict tow-phase locking (2PL):2PL简单来说,就是先获取所有record的锁,然后在处理完后,再同时释放所有的锁。对于不同的情况,锁有不同的种类,读数据时采用的是共享锁,写数据时,采用的是排它锁。
- Multi-Version Concurrency Control (MVCC):不需要锁,只要给数据版本号来保证当前访问数据为目标数据。
- Optimistic Concurrency Control (OCC):多个transaction可以随意读写任意record,但是,一旦一个transaction发现了自己和过去的某个transaction冲突,该transaction就roll back。
绝大多数DBMS通过lock manager实现2PL以保证serializability。MVCC和OCC通常作为2PL的补充实现以减少锁冲突。
Locking and Latching
简要的说一下,lock指的是含有共享锁和排它锁的lock,而latch可以简单的认为是排它锁。
Transaction的一致性代价比较高,所以很多时候并不值得完全线性化。那么根据一致性程度的不同,ANSI SQL提出以下几种Isolation level:
- READ UNCOMMITED:一个transaction每次读的数据可能会读到不同的版本,不需要加任何锁。
- READ COMMITED:一个transaction每次读取一个数据可能会读到不同版本的数据,只要在读数据前加锁,读完后解锁。
- REAPEATABLE READ:一旦transaction读了一个数据,那么以后再读的还是这个数据。
- SERIALIZABLE:完全线性化。
然而ANSI SQL的分类方式没有被实际的DBMS采纳(主要是分类没分好),而是以下面这种分类:
- CURSOR STABILITY
- SNAPSHOT ISOLATION
- READ CONSISTENCY
这几种类型以后再说。
Log Manager
Log manager负责已提交的transaction的持久化、aborted的transaction的滚回以及系统失效的相关任务。Log manager是一个纯细节的系统,作者强烈推荐了一篇必读的paper:C. Mohan, D. J. Haderle, B. G. Lindsay, H. Pirahesh, and P. M. Schwarz, “Aries: A transaction recovery method supporting fine-granularity locking and partial rollbacks using write-ahead logging,” ACM Transactions on Database Systems (TODS), vol. 17, pp. 94–162, 1992.
数据库标准的恢复方案是Write-Ahead Logging (WAL),这里我就不重复介绍了(偷个懒)。
Locking and Logging in Indexes
索引用来检索数据,一般来说对于开发者是不可见的,所以可以提供更高效的检索性能。索引通常要为并发查询提供服务,所以加锁和日志就很重要。
B+树加锁
B+树上的锁问题已经研究的比较透彻,所以这里我们以B+树来作为我们的例子。
B+树里的数据和普通数据相同,都是通过存在buffer pool里的page来访问的,因此在并行情况下需要有加锁机制来保证不会出现错误以及影响性能。常见的解决方案如下:
- Conservative schemes:这是一种比较保守的方法。如果一个transaction和其它的transaction访问的page不同,那么,这个transaction就可以直接执行,否则等待冲突的transaction结束。
- Latch-coupling schemes:这种方法需要两个锁,一个锁锁住当前结点,另一个锁尝试锁住该结点的子结点,依次类推,直到到达叶page。
- Right-link schemes:这个方法我不是很理解,大意是给B+树的每个结点加一个指向右边结点的link,transaction只对当前在使用的node加锁,每次读完node后到下一个结点,具体什么意思不是很懂,有知道的朋友可以评论一下。
作者推荐了一篇较为详细讲解latch机制的paper有兴趣的读者可以了解一下,M. Kornacker, C. Mohan, and J. M. Hellerstein, “Concurrency and recovery in generalized search trees,” in Proceedings of ACM SIGMOD International Conference on Management of Data, pp. 62–72, Tucson, AZ, May 1997.
Logging for Physical Structures
为了让日志恢复更快,日志逻辑需要特殊的日志结构(不知道该怎么说)。大意是,当一个索引被transaction修改且transaction失败时,不需要再将被修改的值再改回来,因为这对其它的transaction不会产生影响。
Shared Components
Catalog Manager
Catalog负责记录关于数据的信息,也就是元数据,并且它们本身也存在一个表中,PostgreSQL中称为系统表。通常catalog会有专门的cache来存储,避免频繁的I/O开销。
Memory Allocator
查询里经常会有消耗大量内存的情况,DBMS会提供一套内存管理机制,一般就是context memory,详细的可以参考一下PostgreSQL的代码。
Disk Management Subsystems
DBMS对disk管理主要因为:disk类型多样、OS文件大小限制、OS打开文件数量限制等。
Replication Services
备份在很多情况下都很有必要,比如数据通过网络传播、分布式数据库等。
完
终于看完了这篇经典paper,对DB的各个方面都有了一次系统的回顾,受益良多,后面大概会抽空写一个DB放在我github上,欢迎大家到时候关注。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号