序列推荐(transformer)
Attention演进(RNN&LSTM&GRU&Seq2Seq + Attention机制)
LSTM
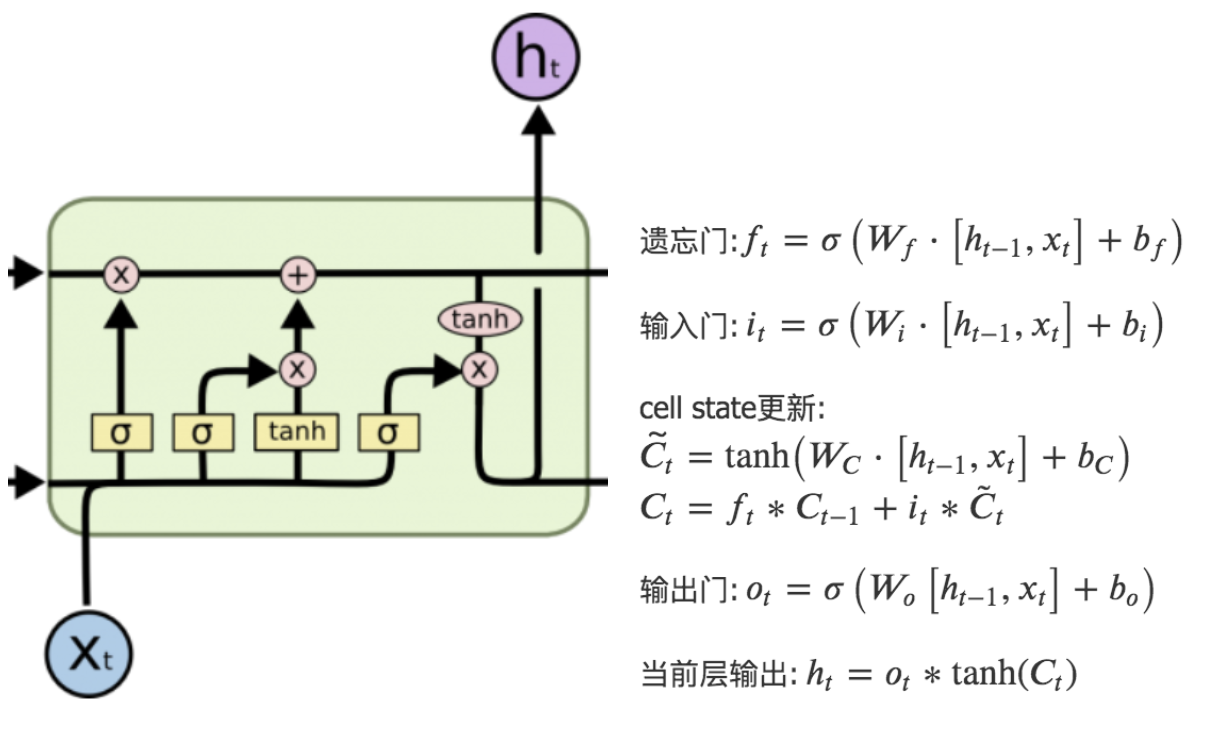
LSTM是RNN的一种变体,RNN由于梯度消失只有短期记忆,而LSTM网络通过精妙的门控制,一定程度上缓解了梯度消失的问题。
LSTM得神经网络模块具有不同的结构,LSTM包含遗忘门、输入门和输出门,增加了非线性的相互作用。整体结构如图所示:
点击查看公式
遗忘门:\( f_{t}=\sigma\left(W_{f} \cdot\left[h_{t-1}, x_{t}\right]+b_{f}\right) \)
输入门:\( \begin{array}{l} i_{t}=\sigma\left(W_{i} \cdot\left[h_{t-1}, x_{t}\right]+b_{i}\right) \end{array} \)
cell state更新:
\(\tilde{C_t}=\tanh \left(W_{C} \cdot\left[h_{t-1}, x_{t}\right]+b_{C}\right)\)
\(C_{t}=f_{t} * C_{t-1}+i_{t} * \tilde{C}_{t}\)
输出门:\( \begin{array}{l} o_{t}=\sigma\left(W_{o}\left[h_{t-1}, x_{t}\right]+b_{o}\right) \end{array} \)
当前层输出:\( \begin{array}{l} h_{t}=o_{t} * \tanh \left(C_{t}\right) \end{array} \)
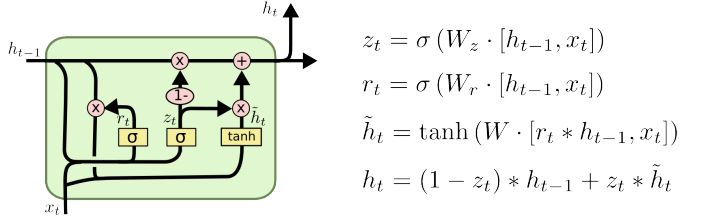
GRU
GRU是LSTM的一种变体,也是为了解决梯度消失(即长期记忆问题)而提出来的。相较于LSTM,GRU的网络结构更加简单,且效果很好。
Seq2Seq + Attention机制
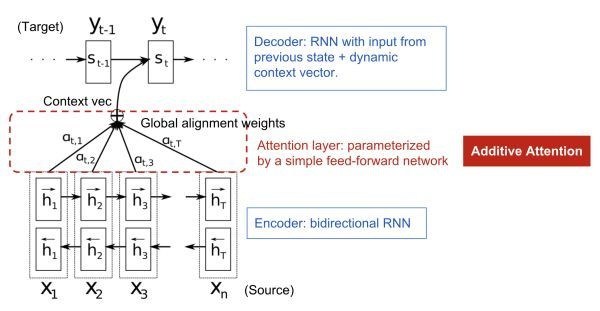
提出问题:在做机器翻译时,专家学者们发现,在Seq2Seq结构中,Encoder把所有的输入序列都编码成一个统一的语义向量context,然后再由Decoder解码。其中,context自然也就成了限制模型性能的瓶颈,当要翻译的句子较长时,一个 context 可能存不下那么多信息。同时,只使用编码器的最后一个隐藏层状态,似乎不是很合理。
解决方案:因此,引入了Attention机制(将有限的认知资源集中到最重要的地方)。在生成 Target 序列的每个词时,用到的中间语义向量 context 是 Source 序列通过Encoder的隐藏层的加权和,而不是只用Encoder最后一个时刻的输出作为context,这样就能保证在解码不同词的时候,Source 序列对现在解码词的贡献是不一样的。例如,Decoder 在解码”machine”时,”机”和”器”提供的权重要更大一些,同样,在解码”learning”时,”学”和”习”提供的权重相应的会更大一些。
实现步骤:(1)衡量编码中第 j 阶段的隐含层状态和解码时第 i 阶段的相关性(有很多种打分方式,这里不细讲);(2)通过相关性的打分为编码中的不同阶段分配不同的权重;(3)解码中第 i 阶段输入的语义向量context就来自于编码中不同阶段的隐含层状态的加权和。
简单总结下:attention比rnn之类参数更少,速度更快(类似cnn可以并行化),效果更好【1】;因为其过滤掉大部分无用信息,所以可以处理更长的序列;下面看下attention是如何建模完成信息过滤的。
Attention机制(self-attention)
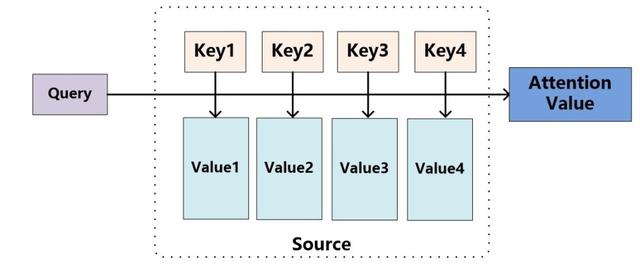
Attention其实就是计算一种相关程度;Attention通常可以进行如下描述,表示为将query(Q)和key-value pairs映射到输出上,其中query、每个key、每个value都是向量,输出是V中所有values的加权,其中权重是由Query和每个key计算出来的,计算方法分为三步:
1)计算比较Q和K的相似度,用f来表示:
2)将得到的相似度进行softmax归一化:
3)针对计算出来的权重,对所有的values进行加权求和,得到Attention向量:
变种之Memory-based Attention
Q&A 任务中,k 是 question,v 是 answer,q 是新来的 question,看看历史 memory 中 q 和哪个 k 更相似,然后依葫芦画瓢,根据相似 k 对应的 v,合成当前 question 的 answer。
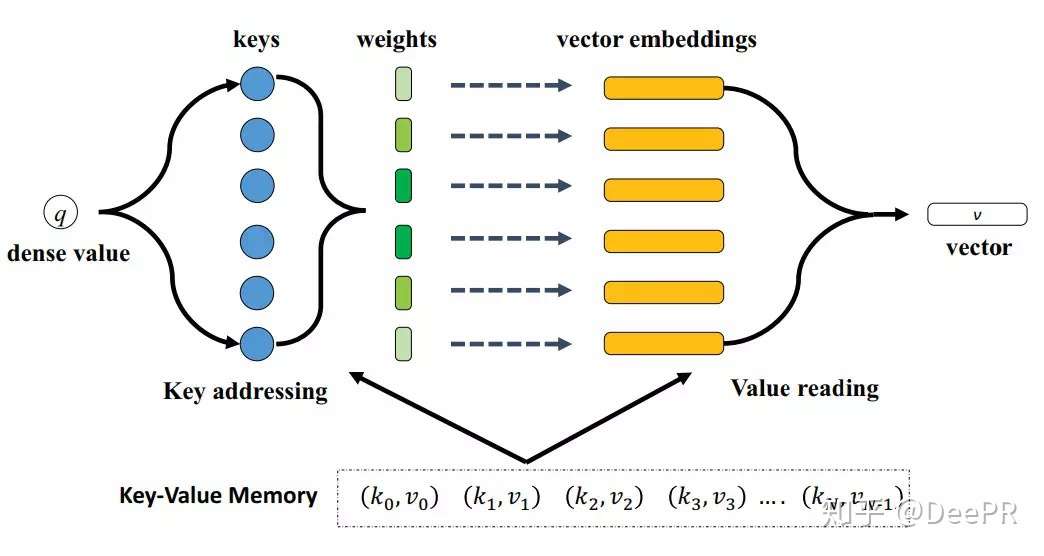
模型的输入是一个稠密特征q,输出是一个特征向量v,向量v的计算是通过对每个embedding vector进行加权求和得到的;【2】
变种之Soft/Hard Attention
hard attention 是一个随机采样,采样集合是输入向量的集合,采样的概率分布即attention weight。因此,hard attention 的输出是某一个特定的输入向量。
soft attention 是一个带权求和的过程,求和集合是输入向量的集合,对应权重是 相似度function 产出的 attention weight。
soft attention 是更常用的,下面讨论相似度function 【3】

变种之self-attention
定义:Self Attention,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的Attention。
Scaled Dot-Product Attention
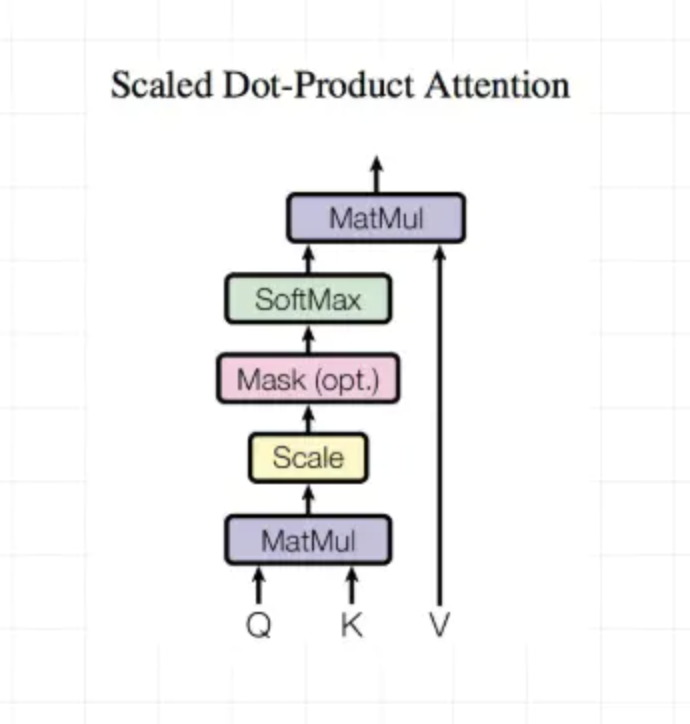
Dot-Product计算相似度
outputs = tf.matmul(Q,tf.transpose(K,[0,2,1]))
outputs = outputs / (K.get_shape().as_list()[-1] ** 0.5)
Encoder mask(主要是padding value平滑下)
key_masks = tf.sign(tf.abs(tf.reduce_sum(keys,axis=-1)))
key_masks = tf.tile(tf.expand_dims(key_masks,1),[1,tf.shape(queries)[1],1])
paddings = tf.ones_like(outputs) * (-2 ** 32 + 1)
outputs = tf.where(tf.equal(key_masks,0),paddings,outputs)
Decoder mask(padding value平滑+只能利用之前的输入约束)
diag_vals = tf.ones_like(outputs[0,:,:])
tril = tf.contrib.linalg.LinearOperatorTriL(diag_vals).to_dense()
masks = tf.tile(tf.expand_dims(tril,0),[tf.shape(outputs)[0],1,1])
paddings = tf.ones_like(masks) * (-2 ** 32 + 1)
outputs = tf.where(tf.equal(masks,0),paddings,outputs)
计算结果outputs
# scaled
outputs = tf.nn.softmax(outputs)
# Query Mask
query_masks = tf.sign(tf.abs(tf.reduce_sum(queries,axis=-1)))
query_masks = tf.tile(tf.expand_dims(query_masks,-1),[1,1,tf.shape(keys)[1]])
outputs *= query_masks
# Dropout
outputs = tf.layers.dropout(outputs,rate = dropout_rate,training = tf.convert_to_tensor(is_training))
# Weighted sum
outputs = tf.matmul(outputs,V)
# Residual connection
outputs += queries
# Normalize
outputs = normalize(outputs)
Multi-Head Attention
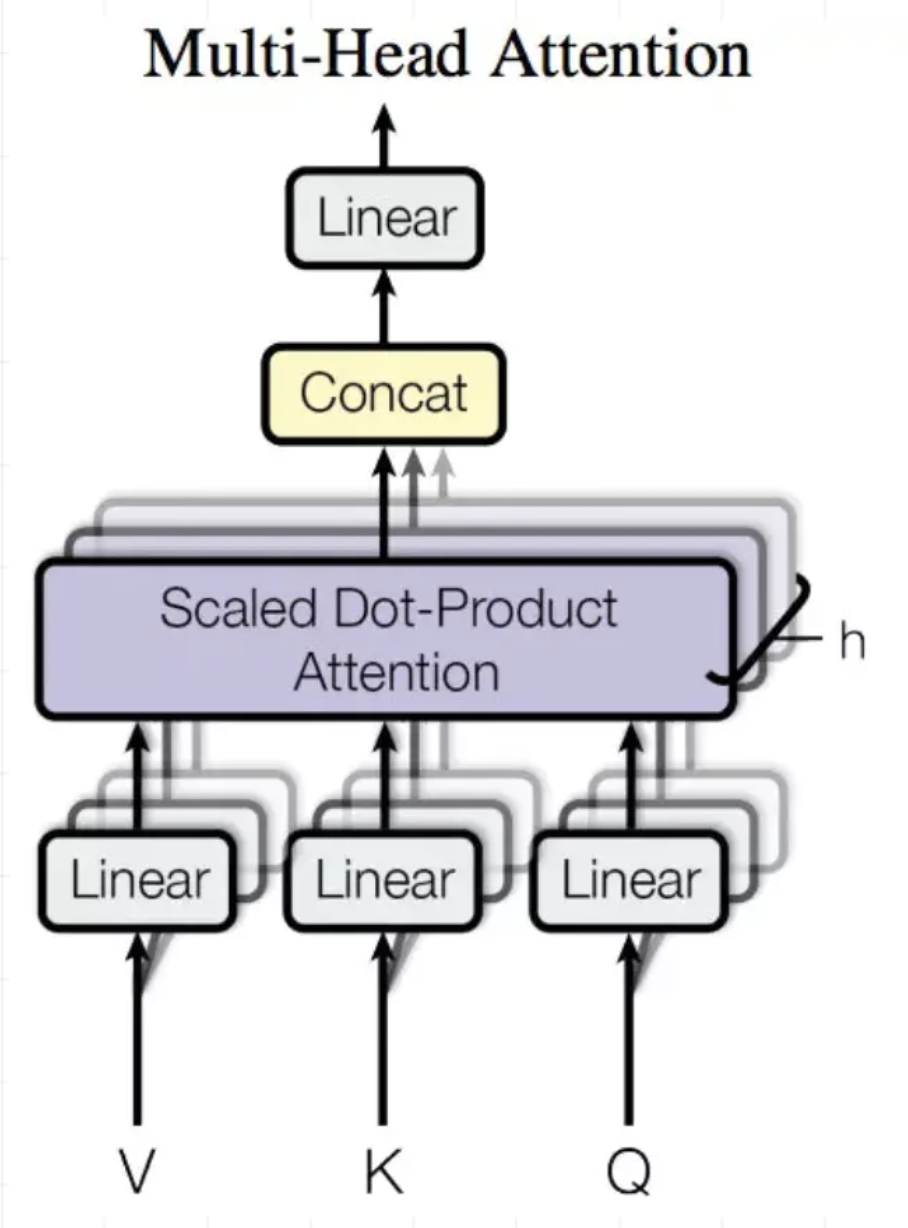
Multi-Head Attention就是把Scaled Dot-Product Attention的过程做H次,然后把输出concat合起来。
序列建模有哪些经典论文?
Next Item Recommendation with Self-Attention
Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
Session-based recommendations with recurrent neural networks
Neural Attentive Session-based Recommendation
Translation-based Recommendation
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
SHAN:Sequential Recommender System based on Hierarchical Attention Networks
BINN:Learning from history and present: next-item recommendation via discrimina-tively exploiting user behaviors
SDM论文笔记
回顾与引入(ABSTRACT+1,2两小节)
SDM:SDM: Sequential Deep Matching Model for Online Large-scale Recommender System
在淘宝的场景中,用户的行为主要分为两种,第一个是当前的浏览session,用户在一个session中,需求往往是十分明确的,比如你想买球鞋,往往只会关注球鞋类的商品。另一个是之前的记录,一个用户虽然可能不是每次都来买球鞋,但是也可能提供一定的有用信息,比如用户只买阿迪的鞋子或者只买帆布鞋等等。因此分别建模这两种行为序列来刻画用户的兴趣,是十分有用的。
提出问题:1)CF类方法并未建模用户的兴趣的动态性和兴趣随时间的演化过程(DSIN);2)一个session内也可能存在多种兴趣倾向(feed的多个维度);3)长期偏好和短期偏好没很好融合
我对动态性/静态性的理解:1)icf是取topk相似的item,然后i2i推荐,相当于仅利用了分布的头部部分;2)传统的embedding建模假设用户的兴趣是长久稳定的和集中的,不随时间和context变化;所以相对的就是动态多兴趣的假设
我对多兴趣倾向的理解:文章中主要是提出电商场景下用户会综合商品的多个角度,也就是多兴趣观点;个人在双列feed的关注点基本1)萌宠/美女类型2)订阅科技/影视作者;还有可能关注封面;同时全局类策略一般不看
解决方案:提出multi-head attention和Gate自适应长短期融合
multi-head attention主要有两点原因:
1)用户的行为中存在一些误点击行为,通过self-attention来降低这种影响;
2)用户可能对不同物品的关注点不同。
Gate自适应长短期融合的原因:
之前简单将item concat或者weighted sum的工作,因为用户找了很久才找到和NBA明星相关的球鞋,其他item反而是噪音;本工作对应的模块是类似lstm的长短期向量门融合模块可以避免这种噪音干扰;
建模&模型架构/结构(第3节)
长期序列:相隔一周以内的行为认为是用户的长期行为(不包含短期序列)
短期序列:
1)日志中标记了同样的session ID
2)虽然session ID不相同,但是相邻的行为间隔小于10min
3)最长的session长度为50,超过50的划分到前一个session
这里论文没给出规则2,3的原因,推测还是阿里这边数据分析的经验;
sdk埋点中session_id定义:应用进入前台生成session_id,退至后台10秒以上重新进入前台重新生成session_id
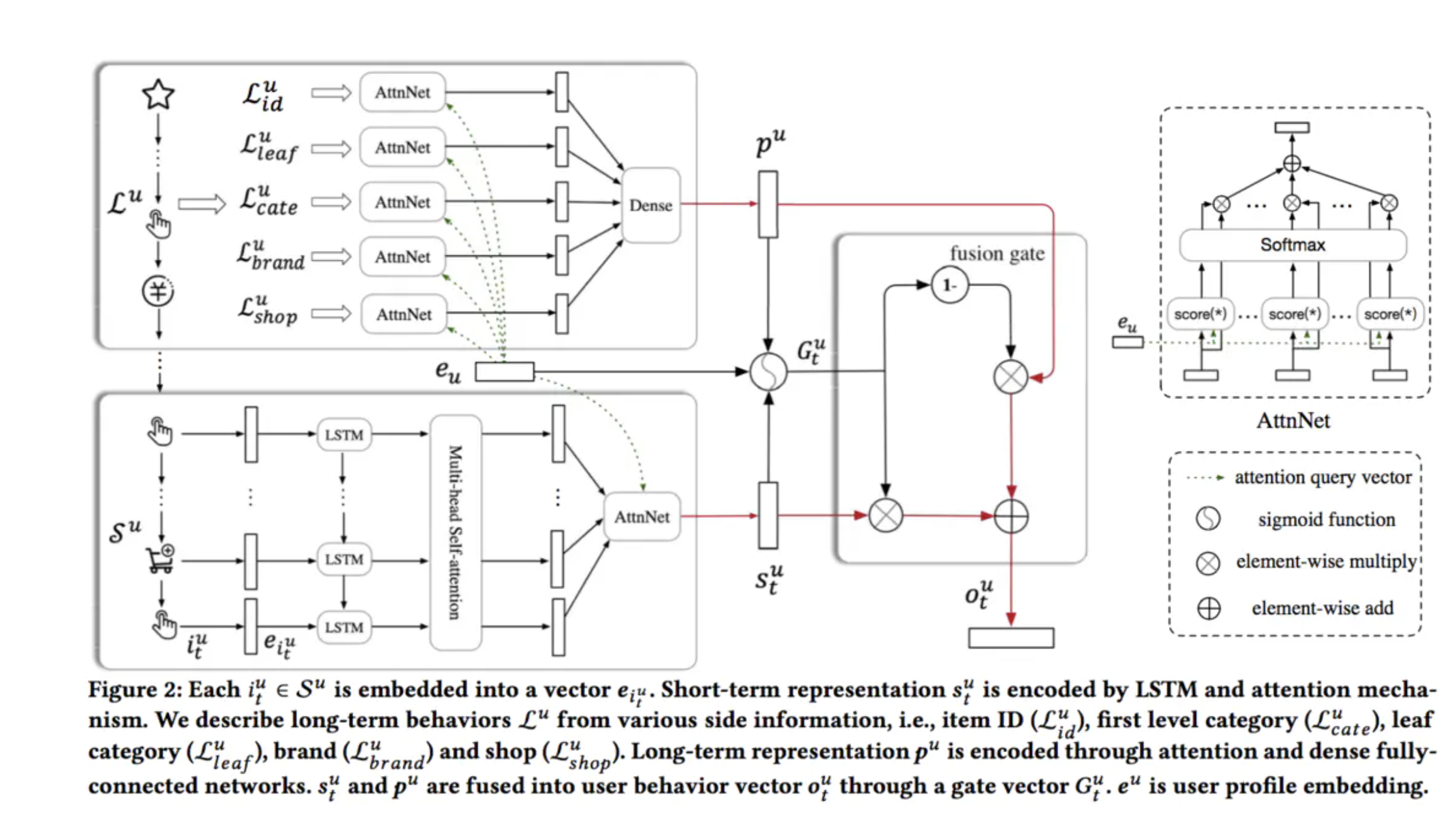
在长期行为中挖掘用户对商品属性的偏好(如类目、品牌、店铺等),在短期行为中结合Multi-Head Self-Attention过滤掉session内部的casual click,并利用Multi-Head挖掘用户在session内的多方面兴趣,最后构造Gate自适应的融合长短期兴趣得到用户兴趣的充分表达。
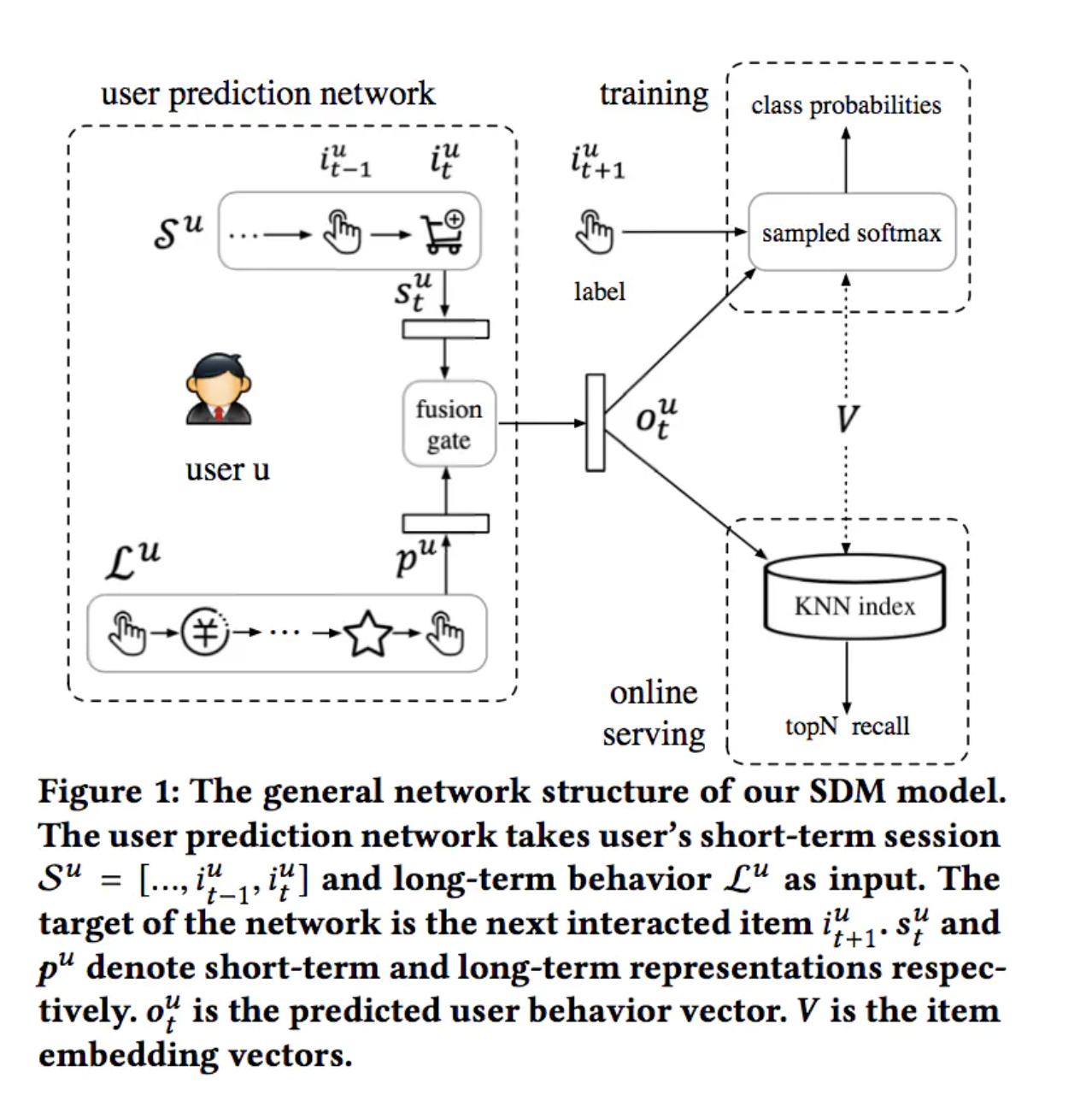
循环层:
使用LSTM捕获和刻画短期行为数据中的全局时序依赖
Multi-Head Attention:
User Attention层
对于不同的用户,即使是相似的商品集合,用户在偏好方面也可能有所不同。因此使用User Attention层去捕获更细粒度的用户偏好。使用用户的embedding(eu)作为attention的query。
短期行为和长期行为融合:
(线上线下)实验设计&实验分析(第4,5,6小节)
数据集:
1)淘宝数据集:8天内行为物品大于40的活跃用户,但过滤行为超过1000 items的异常用户+过滤出现5次以下的item+过滤长度小于2的session(训练阶段);前7天做训练第8天测试;长期行为限制为20;
2)京东数据机:3周训练1周测试;其余与淘宝数据机相同;
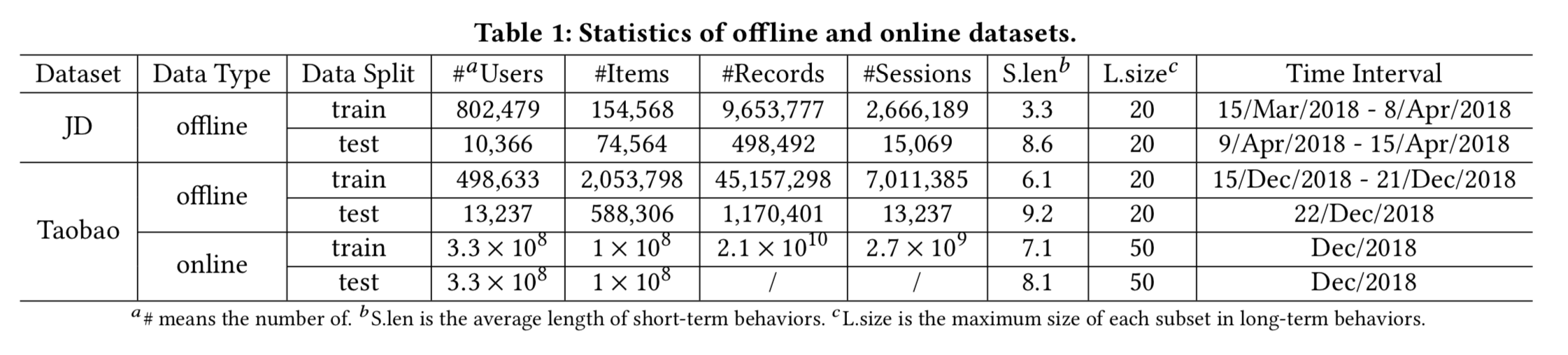
论文中虽然给了代码和数据集链接,但具体的数据处理,模型输入和离线验证都是基于阿里的ODPS和PAI,所以基本不可复现;只能看DeepMatch中关于movielens数据集复现
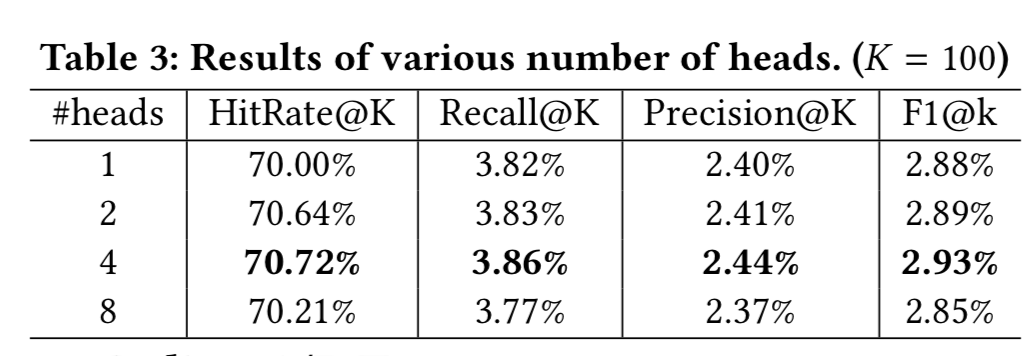
实现细节:
1)multi-head attention中头个数的实验

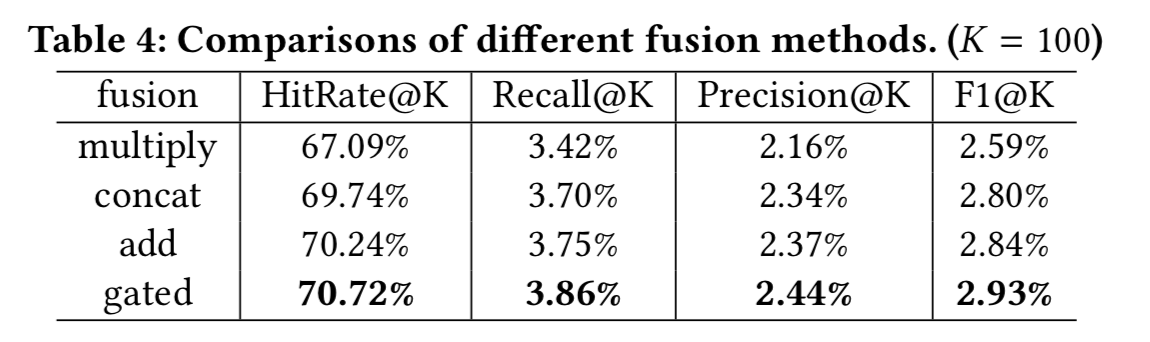
2)融合门的实验
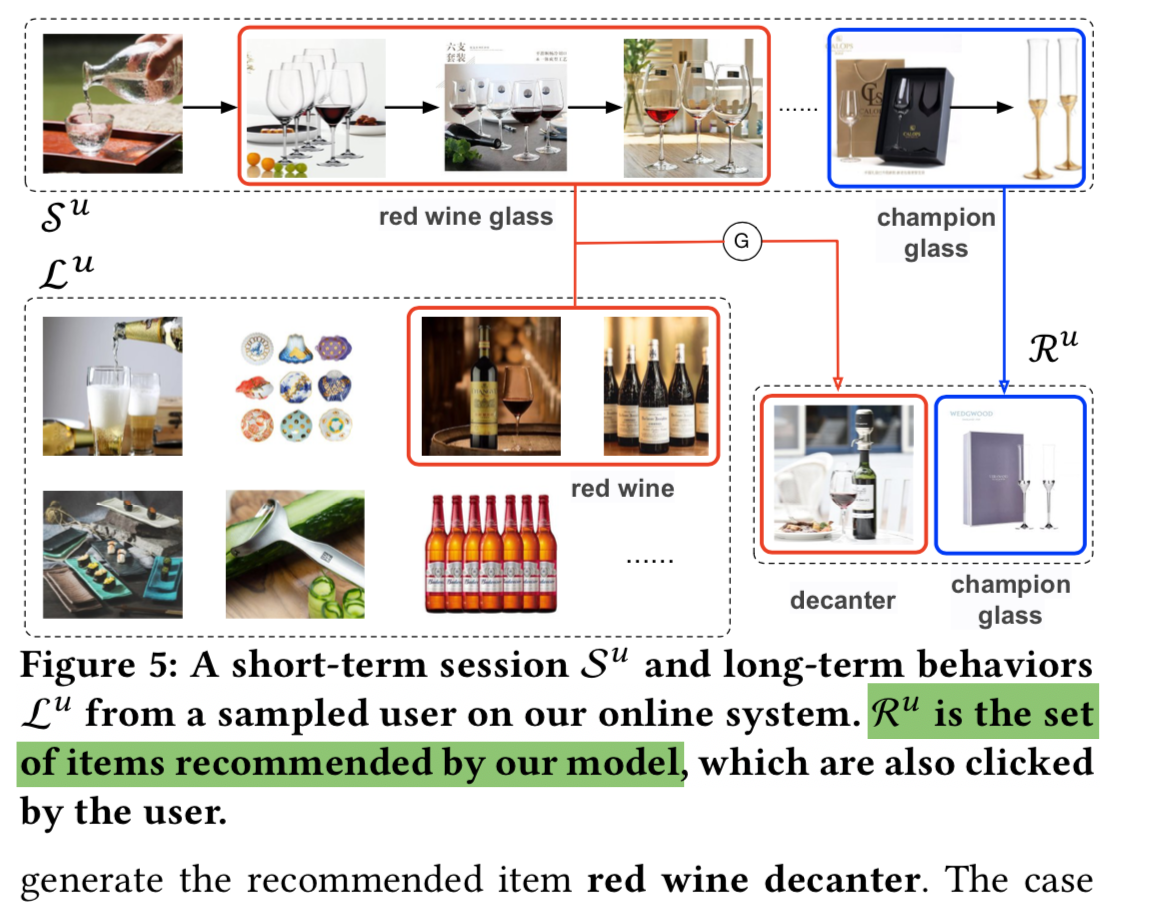
代码:
https://github.com/alicogintel/SDM
https://github.com/shenweichen/DeepMatch
附录
【1】一文看懂 Attention(本质原理+3大优点+5大类型)
【2】稠密特征加入CTR预估模型有哪些方法?
【3】一步步解析Attention is All You Need!
【4】使用Excel通俗易懂理解Transformer!
【5】推荐系统遇上深度学习(三十一)--使用自注意力机制进行物品推荐
【6】推荐系统遇上深度学习(四十)-SESSION-BASED RECOMMENDATIONS WITH RECURRENT NEURAL NETWORKS.
【7】推荐系统遇上深度学习(四十八)-BST:将Transformer用于淘宝电商推荐
【8】推荐系统遇上深度学习(五十二)-基于注意力机制的用户行为建模框架ATRank
【9】推荐系统遇上深度学习(五十八)-基于“翻译”的序列推荐方法
【10】推荐系统遇上深度学习(六十一)-[阿里]使用Bert来进行序列推荐
【11】推荐系统遇上深度学习(六十三)-[阿里]大型推荐系统中的深度序列匹配模型SDM
【12】推荐系统遇上深度学习(六十四)-通过自注意力机制来自动学习特征组合
【13】SDM(Sequential Deep Matching Model)的复现之路
【14】深度学习中的序列模型演变及学习笔记(含RNN/LSTM/GRU/Seq2Seq/Attention机制),智能推荐算法演变及学习笔记,数据挖掘比赛/项目全流程介绍!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号