
Elasticsearch 之python
Elasticsearch介绍
1.什么是搜索
比如:百度,
垂直搜索(站内搜索)
互联网搜索: 电商网站,招聘网站,新闻网站等;
IT系统搜索: OA软件,会议管理,日程管理,项目管理
搜索就是再任何场景下,找寻你想要的信息,这个时候,会输入一段你要搜索的关键字,然后就期望找到这个关键字的有些信息。
2. 如果使用数据库会怎么样?
(1)比方说:每条记录指定字段的文本,可能会很长,比如说“商品描述”字段的长度,有长大数千个,甚至上万个字符,这个时候,每次都要对每一条记录的所有文本进行扫描,判断包含不包含指定的关键字
(2)还不能将搜索词进行拆分来。尽可能搜索更多符合要求期望的结果,比如输入“生化机”,就不能搜索出“生化危机”
因此,使用数据库是不太靠谱的,性能会很差。
3,什么是全文检索和Lucene?
(1)全文检索,倒排索引
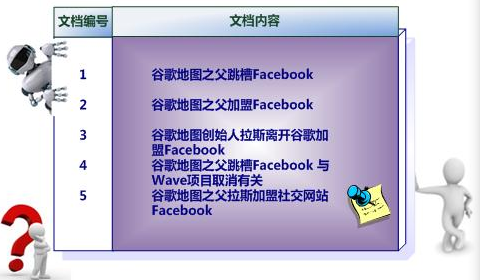

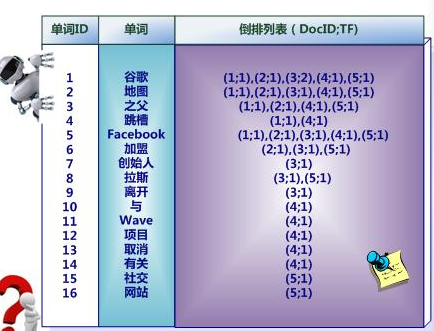
(2)Lucene,就是一个jar包,里面包含了封装好的各种建立倒排索引,以及进行搜索的代码,包括各种算法。我们就用java开发的时候,引入Lucene,然后基于Lucene的api进行开发就可以了。用Lucene,我们就可以将已有的数据建立索引,
Lucene会在本地磁盘上面,给我们组织索引的数据结构。另外的话,我们也可以用Lunece提供一些功能和api来针对磁盘上的索引数据,进行搜索。
4.Elasticsearch功能
(1)分布式的搜索引擎和数据分析引擎
搜索: 百度,网站的站内搜索,IT系统的检索
数据分析:电商网站,比如:1个月内商品销售排名有哪些;
(2)全文检索,结构化检索,数据分析
全文检索:搜索商品名称包含与牙膏的商品, select * from produce where produce_name like "%牙膏%"
结构化检索:搜索商品为日用商品都有那些, select * from produce where category_id="日用商品"
数据分析:分析每一个商品分类下有多少个商品,select category_id,count(*) from produce group by category_id,
(3)对海量数据进行近实时的处理
分布式:ES自动可以将海量数据分散到多台服务器上去存储和检索
跟分布式相反的:Lucene,单机应用,只能在单台服务器上使用,最多只能处理单台服务器的数据量
Elasticsearch安装
1.安装JDK,至少1.8版本以上, https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
配置环境变量, 终端: java -version
2.下载和解压Elasticsearch安装包, https://www.elastic.co/downloads/past-releases 选择版本 5.X
运行bin目录下的 elasticsearch.bat
检查是否启动成功:http://localhost:9200/?pretty
3.下载和解压Kibana
运行bin目录下的 kibana.bat
检查是否运行成功:http://localhost:5601/
进入Dev Tools界面
python API接口进行连接
导入Elasticsearch包
pip install elasticsearch
无用户名密码状态
from elasticsearch import Elasticsearch es = Elasticsearch([{'host':'10.10.13.12','port':9200}])
# 默认的超时时间是10秒,如果数据量很大,时间设置更长一些。如果端口是9200,直接写IP即可
es = Elasticsearch(['10.10.13.12'], timeout=3600)
用户名密码登陆
es = Elasticsearch(['10.10.13.12'], http_auth=('xiao', '123456'), timeout=3600)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号