
RDS性能优化之根据过滤性创建索引
RDS性能优化之根据过滤性创建索引
1、为什么要创建索引?
操作数据库的时候,有个常识是一定要给表创建索引,创建索引可以大大提高系统的性能。通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性,可以大大加快数据的检索速度(这也是创建索引的最主要的原因)。通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
2、创建索引的一般原则
索引是建立在数据库表中的某些列的上面。在创建索引的时候,应该考虑在哪些列上可以创建索引,在哪些列上不能创建索引。
一般来说,应该在这些列上创建索引:
①在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
②在经常需要搜索的列上;
③在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;
④在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
⑤在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
⑥在WHERE子句中的列上面创建索引,加快条件的判断速度。
一般来说,不应该创建索引的的这些列具有下列特点:
①对于那些在查询中很少使用或者参考的列不应该创建索引。
②对于那些只有很少数据值的列也不应该增加索引。
③对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
④当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。
3、根据过滤性创建索引
聚集索引和非聚集索引:
区别是:InnoDB聚集索引中的数据物理存放地址和索引的顺序是一致的,聚集索引一般建立在主键上(会自动按照主键进行聚集),如果没有主键,会用唯一的非空项来代替,如果还没有,InnoDB就会定义bai隐藏的主键然后在上面进行聚集;聚集索引的好处是查询速度特别快。
其他普通索引是非聚集索引。
情况一:全列匹配。
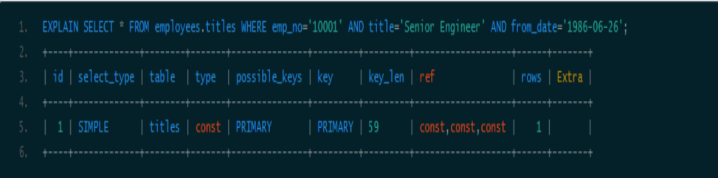
当按照索引中所有列进行精确匹配(这里精确匹配指“=”或“IN”匹配)时,索引可以被用到。理论上索引对顺序是敏感的,但是由于MySQL的查询优化器会自动调整where子句的条件顺序以使用适合的索引,例如我们将where中的条件顺序颠倒,效果是一样的。
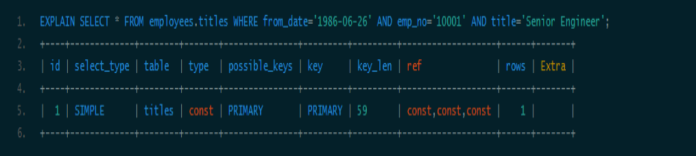
情况二:最左前缀匹配。

当查询条件精确匹配索引的左边连续一个或几个列时,如<emp_no>或<emp_no, title>,所以可以被用到,但是只能用到一部分,即条件所组成的最左前缀。上面的查询从分析结果看用到了PRIMARY索引,但是key_len为4,说明只用到了索引的第一列前缀。
情况三:查询条件用到了索引中列的精确匹配,但是中间某个条件未提供。

因为title未提供,所以查询只用到了索引的第一列,而后面的from_date虽然也在索引中,但是由于title不存在而无法和左前缀连接,因此需要对结果进行扫描过滤from_date(这里由于emp_no唯一,所以不存在扫描)。解决办法是①可以增加一个辅助索引<emp_no, from_date>(优先使用这个办法)。②还可以使用一种称之为“隔离列”的优化方法,将emp_no与from_date之间的“坑”填上(不推荐,性能提升有限)。
title一共有7种不同的值:

在这种成为key的列值比较少的情况下,可以考虑用“IN”从而形成最左前缀:
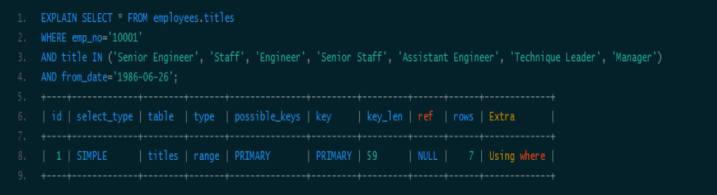
这次key_len为59,说明索引被用全了,但是从type和rows看出IN实际上执行了一个range查询,这里检查了7个key。看下两种查询的性能比较:
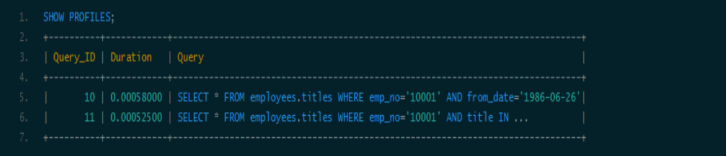
性能提升了一点。如果经过emp_no筛选后余下很多数据,则后者性能优势会更加明显。当然,如果title的值很多,用填坑就不合适了,必须建立辅助索引。
情况四:查询条件没有指定索引第一列。
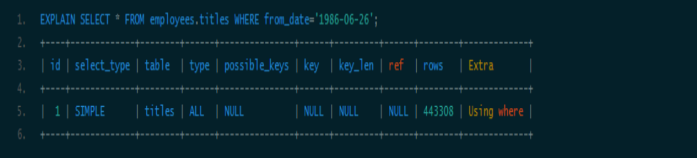
由于不是最左前缀,显然用不到索引。原因:根据最左前缀匹配原则,mysql在按照从左到右的顺序创建索引树,在执行查询计划时,先找a这个搜索因子,然后查找其他搜索因子;如果没有a的话,b+树不知道该查哪个节点,所以不会用到索引。
情况五:匹配某列的前缀字符串。
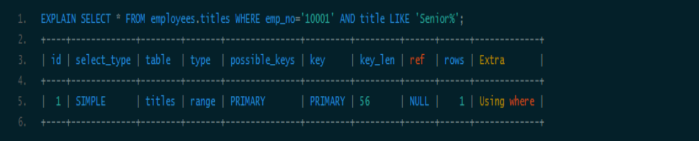
此时可以用到索引,注意:通配符%需要放在末尾。
情况六:范围查询。
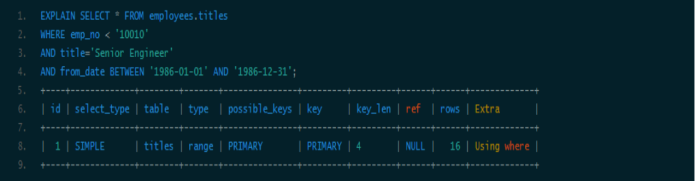
范围列可以用到索引(必须是最左前缀),但是范围列后面的列无法用到索引。同时,索引最多用于一个范围列,因此如果查询条件中有两个范围列则无法全用到索引。

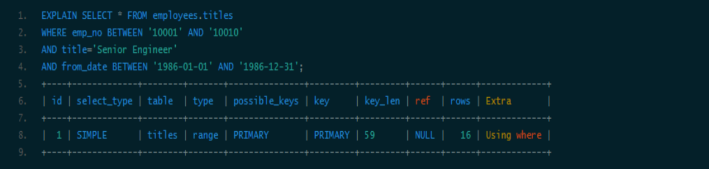
可以看到索引对第二个范围索引无能为力。用explain可能无法区分范围索引和多值匹配,因为在type中这两者都显示为range。同时,用了“between”并不意味着就是范围查询,例如下面的查询:
看起来是用了两个范围查询,但作用于emp_no上的“BETWEEN”实际上相当于“IN”,也就是说emp_no实际是多值精确匹配。可以看到这个查询用到了索引全部三个列。因此在MySQL中要谨慎地区分多值匹配和范围匹配,否则会对MySQL的行为产生困惑。
情况七:查询条件中含有函数或表达式。
如果查询条件中含有函数或表达式,则MySQL不会为这列使用索引;例如:
由于使用了函数left,则无法为title列应用索引,而情况五中用LIKE则可以。再如:

显然这个查询等价于查询emp_no为10001的函数,但是由于查询条件是一个表达式,MySQL无法为其使用索引。看来MySQL还没有智能到自动优化常量表达式的程度,解决办法是:写查询语句时尽量避免表达式出现在查询中,而是先手工私下代数运算,转换为无表达式的查询语句。
4、总结:
了解不同存储引擎的索引实现方式对于正确使用和优化索引都非常有帮助,例如知道了InnoDB的索引实现后,就很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。再例如,用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一棵B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号