
ModR/M字段的Reg/Opcode,代表两重含义Reg或Opcode由谁决定
在 x86/x64 架构中,ModR/M 字节的 Reg/Opcode 字段到底代表“寄存器编号”还是“操作码扩展码”,完全由主操作码(Primary Opcode)决定。
这是指令集设计时就已经硬编码在硬件逻辑中的,下面是对ModR/M 字节的 Reg/Opcode 字段分析:
简单来说,当 CPU 解码器读取到第一个字节(Opcode)时,它就已经通过内部的查询表(Lookup Table)知道了接下来该如何解释 ModR/M 字节。
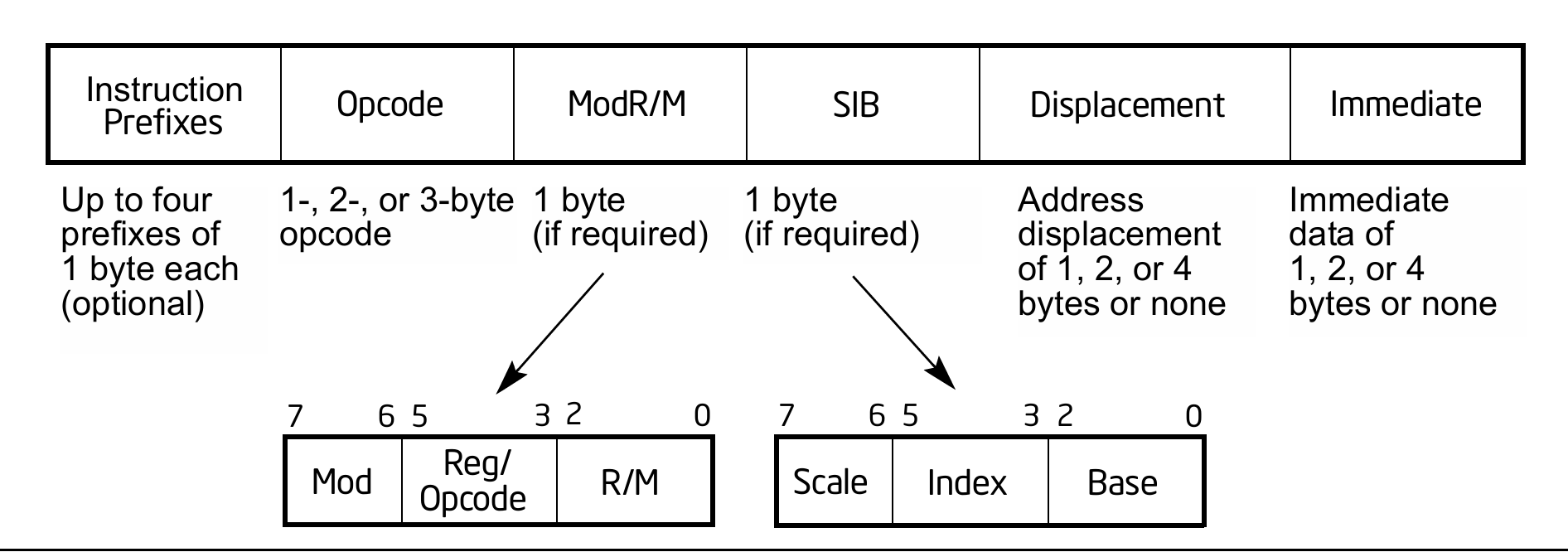
一、 判定逻辑:主操作码的指令定义
这是指令集设计时就已经硬编码在硬件逻辑中的,下面是对ModR/M 字节的 Reg/Opcode 字段分析:
- 含义 Reg:代表“寄存器(Register)”
如果主操作码定义的是一条涉及两个操作数的指令(通常是寄存器与寄存器、或寄存器与内存之间),那么 Reg 字段就代表其中一个寄存器。- 例子:
8B /r(MOV r32, r/m32)。这里的/r告诉 CPU:Reg 字段是一个寄存器编号。 - 硬编码:
8B C3中,C3的 Reg 部分000代表EAX。
- 例子:
- 含义 Opcode:代表“操作码扩展码(Opcode Extension)”
如果主操作码定义的是一条只需要一个操作数(另一个是立即数,或者指令本身就是单操作数)的指令簇,那么 Reg 字段就被借用来当作操作码的补充,以区分不同的运算。- 例子:
80 /数字(如80 /0是 ADD,80 /5是 SUB)。 - 硬编码:
80 C0 05中,C0的中间三位000不代表寄存器,而是代表执行“加法”逻辑。
- 例子:
二、 手册中的区分标识
在 Intel/AMD 官方开发手册的指令参考表中,你可以通过操作码列的符号直接区分:
- 看到
/r:表示该字段代表一个寄存器(Register)。- 例如:
MOV r/m32, r32的操作码是89 /r。
- 例如:
- 看到
/0到/7:表示该字段是扩展码(Digit)。- 例如:
INC r/m32的操作码是FF /0。 - 例如:
DEC r/m32的操作码是FF /1。
- 例如:
三、为什么这样设计?(核心本质)
这种设计遵循了信息熵的最大化利用:
- 双操作数指令:需要指定“谁给谁”,所以需要两个寄存器/内存标识(ModR/M 的 Reg 字段和 R/M 字段都被占用)。
- 单操作数指令:只需要指定一个目标(占用 R/M 字段),原本存放第二个寄存器的 Reg 字段就空闲了。为了不浪费这 3 位(可表示 8 个状态),设计师将其作为指令的“二级开关”。
四、Lookup Table 在硬件中的设计
在硬件架构中,用于解码指令的操作码查询表(Lookup Table, LUT)并非一个独立的“存储器芯片”,而是集成在 CPU 核心的译码器(Instruction Decoder) 内部。
在硬件架构中,用于解码指令的操作码查询表(Lookup Table, LUT)并非一个独立的“存储器芯片”,而是集成在 CPU 核心的译码器(Instruction Decoder) 内部。
在现代 x86-64 处理器(如 Intel Core Ultra 或 AMD Ryzen 系列)中,这一机制由以下几个层级共同实现:
1. 物理位置:指令译码器 (Instruction Decoder)
查询逻辑位于 CPU 流水线的前端(Front-end)。当指令从 L1 指令缓存被取出后,首先进入译码阶段。
- 硬连线逻辑 (Hardwired Logic):
对于最常用的简单指令(如MOV,ADD),查询表实际上是一组极其快速的组合逻辑门电路。操作码的位模式(Bit Pattern)直接触发相应的电路路径。 - μOps ROM (微码只读存储器):
对于复杂的指令(CISC 特性的复杂指令),译码器会查询一个内置的只读存储器(ROM),将其分解为一系列简单的微指令(Micro-ops / μOps)。
2. 核心组件:操作码映射表 (Opcode Map)
译码器内部逻辑按以下结构组织映射:
- 一级索引(Primary Opcode Map):处理单字节操作码(00-FF)。
- 扩展索引(Two-byte/Three-byte Maps):当识别到转义字节(如
0Fx)时,逻辑会跳转到针对 2 字节或 3 字节操作码的查询电路。 - ModR/M 分支逻辑:
在读取主操作码后,译码器会立即并行检查 ModR/M 字节。如果是/0还是/r,是由主操作码映射表输出的控制信号来决定后续电路是去读寄存器堆(Register File)还是去选通算术逻辑单元(ALU)的特定功能(如加法或减法)。
3. 现代处理器的优化:译码缓存 (uOp Cache)
由于 x86 指令长度不一、译码过程(查询 LUT、解析 SIB、处理 REX 等)非常耗电且有延迟,现代 CPU 引入了 μOp Cache:
- 如果一条指令之前被执行过,其查询和解析后的结果(即微指令)会被存储在 μOp Cache 中。
- 下次执行同一条指令时,CPU 会直接跳过译码阶段和 Lookup Table 查询,直接从缓存中获取微指令,从而大幅提升性能。
四、主操作码映射表
在 x86 架构中,主操作码映射表(Primary Opcode Map) 是 CPU 译码器(Instruction Decoder)解析指令的第一步,它决定了指令的基本属性和后续字节的解析规则。
五、主操作码映射表存放在哪里?
在硬件架构中,主操作码映射表(Primary Opcode Map) 并不是以我们想象中的“Excel表格”形式存在于某个存储芯片里,而是硬连线(Hardwired)在 CPU 的 译码单元(Instruction Decoder) 的逻辑电路中。
在 x86 架构中,主操作码映射表(Primary Opcode Map) 是 CPU 译码器(Instruction Decoder)解析指令的第一步,它决定了指令的基本属性和后续字节的解析规则。
在现代 x64 处理器中,虽然支持成千上万条指令,但其核心逻辑依然遵循经典的 256 个条目(00h - FFh) 的映射结构。
主操作码映射表(Primary Opcode Map) 并不是以我们想象中的“Excel表格”形式存在于某个存储芯片里,而是硬连线(Hardwired)在 CPU 的 译码单元(Instruction Decoder) 的逻辑电路中
主操作码映射表(Primary Opcode Map) 并不是以我们想象中的“Excel表格”形式存在于某个存储芯片里,而是硬连线(Hardwired)在 CPU 的 译码单元(Instruction Decoder) 的逻辑电路中
以下是主操作码映射表的核心设计逻辑:
1. 1字节操作码映射 (One-byte Opcode Map)
当译码器读取第一个非前缀字节时,它会将该字节作为索引查表。这个“表”在硬件逻辑中将操作码分为几个大类:
- 00h - 3Fh (算术逻辑运算):
- 通常成组出现(ADD, OR, ADC, SBB, AND, SUB, XOR, CMP)。
- 遵循
TTTTTTdw位模式。例如00是ADD r/m8, r8,01是ADD r/m32, r32。
- 40h - 4Fh (特殊区域):
- 在 32 位模式下:代表
INC和DEC寄存器的短指令。 - 在 64 位模式下:这些编码被重新定义为 REX 前缀。这是主映射表在不同模式下行为不同的典型例子。
- 在 32 位模式下:代表
- 50h - 5Fh (栈操作):
PUSH和POP寄存器的短操作码(如50是PUSH EAX/RAX)。
- 70h - 7Fh (短跳转):
- 条件跳转指令(如
74是JZ/JE)。
- 条件跳转指令(如
- 80h - 83h (立即数运算簇):
- 这是你之前研究最多的区域。它们是必须配合 ModR/M 扩展位(Reg/Opcode)才能确定具体指令的区域。
- B0h - BFh (立即数移动):
MOV立即数到寄存器的短指令(如B8)。
2. 转义操作码(Escape Opcodes)
主映射表中有几个特殊条目,它们不是指令,而是指向次级映射表的“传送门”:
0Fh:多字节指令的前缀。当主表读到0F,它会切换到 Two-byte Opcode Map(用于加载 SSE, AVX, 系统指令等)。0F 38/0F 3A:进一步跳转到 Three-byte Opcode Map。
3. 表项输出的内容
当译码器在主表中“查到”一个操作码时,它会输出一系列控制信号给后续电路:
- 指令长度:这条指令后面还有几个字节?
- ModR/M 存在标志:是否需要读取下一个字节来确定寻址?
- Reg 字段定义:ModR/M 的中间 3 位是当作寄存器编号还是当作扩展码?
- 操作数宽度:默认是 8 位、32 位还是由 REX/0x66 前缀决定?
4. 2026 年硬件中的实现:PLD 与微码
- 简单操作码:通过 PLA (可编程逻辑阵列) 实现。输入 8 位操作码,直接输出对应的控制线电平,速度极快(单时钟周期)。
- 复杂操作码:如果主表判定该指令非常复杂(如
CPUID或IRET),它会输出一个地址,引导译码器去 Microcode ROM 中读取一段微程序来分步执行。
五、主操作码映射表存放在哪里?
在硬件架构中,主操作码映射表(Primary Opcode Map) 并不是以我们想象中的“Excel表格”形式存在于某个存储芯片里,而是硬连线(Hardwired)在 CPU 的 译码单元(Instruction Decoder) 的逻辑电路中。
在现代处理器(如 Intel 第 16 代或 AMD Zen 6 架构)中,它的存在形式主要分为以下三个层面:
1. 物理位置:指令译码器前端 (Decoder Front-end)
它位于 CPU 核心内部,紧邻 L1 指令缓存(L1i Cache)。当指令流从缓存进入流水线时,第一站就是译码器。
- 简单指令(快速路径):对于像
MOV,ADD,PUSH这种主操作码映射表中的常用指令,它们被实现在 PLA(可编程逻辑阵列) 或 组合逻辑门电路 中。此时,“映射表”就是一组电路路径,操作码字节的 8 位电平信号直接触发对应的逻辑开关。 - 复杂指令(微码路径):对于像
VMENTER,IRET这种复杂的指令,主映射表会指向 Microcode ROM(微码只读存储器)。这个 ROM 位于译码单元深处,存放着将复杂指令分解为微操作(uOps)的指令集。
2. 逻辑形式:译码流水线
在高性能 CPU 中,译码器通常是多发射的(例如每周期可译码 6-8 条指令)。主操作码映射表被复制到多个并行译码槽中:
- Simple Decoders:处理主映射表中最基础的指令,这些电路非常精简。
- Complex Decoders:处理需要查询微码、处理多个前缀或多字节操作码的指令。
3. 性能优化层:μOp Cache(微操作缓存)
由于通过逻辑门阵列解析主操作码映射表并计算 ModR/M 依然存在延迟,2026 年的 CPU 广泛依赖 μOp Cache:
- 位置:介于译码器和执行单元之间。
- 本质:它是“已经查过表的指令结果”。如果主操作码映射表之前已经解析过某段代码,结果会直接存入这个缓存。
- 意义:CPU 实际上在大部分时间里是绕过了物理映射表的查询,直接从 μOp Cache 获取解析好的信号。
总结
主操作码映射表存放在指令译码器的逻辑门阵列(Hardwired Logic)和微码 ROM(Microcode ROM)中。
- 它不是软件,是纯硬件电路。
- 它不可更改(除非通过厂商发布的微码更新/补丁临时重定向逻辑)。
- 它的查找速度是 皮秒(picoseconds) 级的。
如果你想查阅该表的具体内容,可以访问 Intel 官方 SDM 手册第 2 卷附录 A,该手册以表格形式展示了 CPU 硬件中固化的这一套映射逻辑。
主操作码映射表是 x86 架构的“根索引”。你之前提到的所有规则(比如
80 /5 是减法,而 8B /r 是赋值),其根源都是主映射表在解码 80 和 8B 时,向译码电路发出了完全不同的ModR/M 解释指令。你可以查阅 Intel SDM Volume 2, Appendix A 获取完整的 Table A-2 (One-byte Opcode Map),那是所有 x86 软件运行的终极蓝图。
Lookup Table 的本质是译码器中的逻辑阵列和微码 ROM。 它位于 CPU 内部靠近指令缓存和执行单元之间的位置。
如果你想更深入研究,可以参考 Intel 64 架构优化指南 中关于 Pipeline Front-end (译码器前端) 的章节,那里详细描述了指令是如何从操作码字节转化为控制信号的。
决定权在主操作码(Opcode)手中。 CPU 在 2026 年的现代流水线中,通过译码阶段(Decode)的第一步就确定了 ModR/M 字节的解析规则:是把它当成“数据源”的一个寄存器,还是把它当成“指令含义”的一部分。 Intel SDM Volume 2, Chapter 2.1 详细描述了这一译码机制。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号