
AI调参:关于Tokens和参数关系
关于Tokens和参数关系
PS D:\ollama源码-go> ollama ls NAME ID SIZE MODIFIED smollm2:135m-2k-ctx-test 57be70d27195 270 MB 5 hours ago smollm2:135m 9077fe9d2ae1 270 MB 6 hours ago nomic-embed-text:latest 0a109f422b47 274 MB 6 hours ago mymodel:latest b00fc97c00a3 1.9 GB 21 hours ago qwen3-vl:2b 0635d9d857d4 1.9 GB 21 hours ago gemma3:latest a2af6cc3eb7f 3.3 GB 21 hours ago llama3:latest 365c0bd3c000 4.7 GB 29 hours ago deepseek-r1:8b 6995872bfe4c 5.2 GB 42 hours ago gemma3:4b a2af6cc3eb7f 3.3 GB 3 weeks ago
这里 sollm2模型最小,也最好用。
一、Tokens
理解这些术语将帮助你选择符合应用需求和硬件限制的模型。
一个 token 在NLP模型处理中是最小的数据单位例如一个句子、一个单词、一个单词的一部分或一个字符(例如标点符号等),这是一种将文本拆解成利于分析的办法,当然不止是NLP、大数据、AI等。
同样会遵循着这样的处理方式。
一个 chunk 由一组 tokens 组成,如果我们有个文本: "Hello there! My name is aozhejin!",我们想处理这段文字, 你也许会这样不同的思路处理:
tokens -> sentences, chunks-> paragraphs tokens-> words, chunks ->sentences tokens ->words, chunks -> 一组chunks tokens -> characters, chunks ->words tokens ->characters, chunks ->chunk size
首先在大数据和人工智能领域,特别是在使用诸如qwen3-vl:2b 等进行对话生成时,了解每次对话的token最大数量是非常重要的。这是因为模型的输入和输出都受到token数量的限制。 token数量限制分以下几种
1>模型中支持的最大上下文窗口(即context length)限制
2>模型运行期间,最大的上下窗口大小限制
3>模型没有设置上下文窗口大小,则ollama会设置4096/2048等默认值
context length在大型语言模型(LLM)的性能和效能中起着关键作用。通过定义模型一次能处理的输入数据量,上下文长度影响模型理解和生成文本的能力
所以context length较短的模型,可能更适合处理简短文本分类或基础问答等简单任务。
1>查看模型支持的context length 大小(即token的数量):
PS D:\ollama源码-go> ollama show llama3:latest
Model
architecture llama
parameters 8.0B
context length 8192 (此模型最大可以设置到8k的token数量, 8192/1024=8k)
embedding length 4096 (这个数字不能更改,代表1个token的向量维度)
quantization Q4_0
PS D:\ollama源码-go> ollama show smollm2:135m Model architecture llama parameters 134.52M context length 8192 embedding length 576 quantization F16
解释:
#context length 这个参数设置就是该模型的token数量限制,模型最大只能处理8k的token数量 ,同样输出也是8k
输入我们一般称为pormpt,输出一般称为respose
同时参考: Ollama 微调模型以及创建模型文件(Modelfile) - jinzi - 博客园
tokens的成本:
例如单词“common” 是一个 1 token 在大多数的LLMs中. 意思是, 如果你写了 common 在prompt 提示里面, 他会被计算为 1个token
对于 ChatGPT、 Claude或 Llama 3. 然而, “uncommon” 在Claude模型中被当作1个token,而在ChatGPT 3.5中被分割成“un” 和 “common”当作了 2个 tokens .
tokens决定了输入和输出限制,也会影响到处理速度、成本等。 你会发现增加tokens数量,你需要的内存会更多、资源会更大等。当然也会影响到模型对你的输入的内容理解
英文来说一个英语单词差不多是1.3到0.75个token(100个单词对应差不多130个token),1个token是3-4个英文字符(不同模型计算方法不一样),
如果4k的token数,对应大约3000个英语单词。
理解token数量,往往大数据中token的数量设定被认为是LLM之间的区别。

2>模型运行期间,最大的上下窗口大小限制
临时变更 /set parameter num_ctx <数字> 测试 (num_ctx表示运行时context length)
num_ctx: 上下文长度官方上解释为指的是模型在生成响应时一次能考虑的最大数量的tokens。它包括输入token(prompt)和输出token(response)
当我设置,num_ctx大于4和小于4进行测试模型smollm2:135m 最小toke数是2
1.当你设置到16时,ps看token数,设置到了16 >>> /set parameter num_ctx 16 PS D:\ollama源码-go> ollama ps NAME ID SIZE PROCESSOR CONTEXT UNTIL smollm2:135m 9077fe9d2ae1 269 MB 100% CPU 16 4 minutes from now 2.当你设置2时,ps看token数,设置到了4 >>> /set parameter num_ctx 2 PS D:\ollama源码-go> ollama ps NAME ID SIZE PROCESSOR CONTEXT UNTIL smollm2:135m 9077fe9d2ae1 269 MB 100% CPU 4 4 minutes from now
2.当你设置5时,ps看token数,设置到了5>>> /set parameter num_ctx 5 PS D:\ollama源码-go> ollama ps NAME ID SIZE PROCESSOR CONTEXT UNTIL smollm2:135m 9077fe9d2ae1 269 MB 100% CPU 5 4 minutes from now PS D:\ollama源码-go> 一旦你从当前对话 /bye 之前,再次进入 PS D:\ollama源码-go> ollama run smollm2:135m 你会发现 num_ctx 又恢复到了默认
3>ollama默认context window length 是4096/2048 ,是什么意思?
1.启动会话 PS D:\ollama源码-go> ollama run smollm2:135m >>> 请规划下哈尔滨一日游 2. 查看当前的context length (Context) PS D:\ollama源码-go> ollama ps NAME ID SIZE PROCESSOR CONTEXT UNTIL smollm2:135m 9077fe9d2ae1 363 MB 100% CPU 4096 4 minutes from now 你会看到是4096,大家常说的ollama默认是4096(4k) 窗口上下文大小,指的就是这个 由于这个时候,你并没有干预模型,所以ollama会默认设置每次上下文缓存为4k包括输入与输出 ,之前版本大小是2048 =2k
由于这个值直接影响到你的内存消耗,所以慎重的进行考虑进行设置。当然每个模型都有最大的context length 限制.
二、在大型语言模型中实现上下文长度
上下文长度通常在模型设计和训练阶段设定的。用户有时可以在一定范围内配置该参数,具体取决于所使用的接口或API。然而,必须注意,将上下文长度增加到一定程度后可能需要更多的计算和资源,因为在大型语言模型中,你要为“输入”和“输出”的tokens数量付费。如果你想保留一个较大的上下文窗口,比如使用对话的场景中,那么每次响应的成本都会增加。除了成本增加外,这还可能影响模型的性能。
为了创建一个上下文长度较长的大型语言模型,研究人员使用长序列来训练模型。在大型语言模型(LLM)中,长序列通常指的输入文本远比标准训练示例长,通常在数千到数万个token之间。在这些长序列上进行训练对于增加模型的上下文长度至关重要。
专门用于长序列训练的方法包括:
- 梯度累积:该技术允许通过将长序列拆分成更小的chunks(块)来处理,积累梯度后再更新权重。对于处理超出GPU内存容量的序列来说,它是必不可少的。
- 高效的注意力机制:稀疏注意力或滑动窗口注意力等算法对于处理长序列至关重要,因为它们降低了标准注意力的二次复杂度。
- 记忆高效训练:利用可逆层、激活检查点或内存高效优化器等技术,来管理长序列带来的更高内存需求。
- 位置编码适应:扩展或修改位置编码以适应较长的序列,例如使用相对位置嵌入或旋转位置嵌入。
- 课程学习阶段的序列长度:在整个训练过程中逐步延长训练序列的长度,使模型能够逐步适应更长的上下文。
- 专业数据预处理:准备训练数据时,使用更长的连续通道,确保模型在训练过程中看到真正长的序列。
计算资源的影响:
增加上下文长度需要更多的内存和处理能力。计算成本与上下文窗口长度成平方增长,这意味着上下文长度为4096个令牌的模型所需的计算资源是上下文长度为1024个令牌的16倍。计算需求的增加成为部署极长上下文长度模型的重大障碍,尤其是在资源受限的环境中。
三、实际应用与应用场景
较大的上下文长度增强了多种应用,例如:
- 文档摘要:准确总结长文档。例如,法律专业人士可以使用带有扩展上下文窗口的大型语言模型来摘要冗长的合同或法律简报,节省时间并减少遗漏关键信息的风险。
- 长文内容生成:撰写论文、报告和文章。作者和内容创作者可以利用LLM生成连贯且结构良好的长篇内容,提升生产力和创造力。
- 复杂对话系统:在聊天机器人中保持长时间对话的上下文。客户服务机器人通过记住之前的互动并理解对话的整体背景,能够提供更准确、更有帮助的回答。
上下文长度是大型语言模型的一个基本方面,显著影响其处理、理解和生成文本的能力。虽然较长的上下文长度增强了模型的能力,但也需要更多的计算资源和复杂的训练技术来保持性能和准确性。随着研究的不断进步,我们可以期待出现更强大、更高效的大型语言模型,能够处理越来越复杂的任务。
理解并利用上下文长度对于释放LLM的全部潜力、推动各领域创新至关重要。通过解决延长上下文长度的挑战和开发高效训练和位置编码的新技术,研究人员可以继续突破大型语言模型的边界。无论是提升客户服务、协助法律专业人士,还是加强学术研究,上下文长度对大型语言模型的影响都深远且深远。
四、embedding length
为向量模型选择合适的大小
在选择嵌入模型的维数时,请考虑 以下因素:
性能与成本:更高维度可以提升性能,但也会增加计算成本。 更短的尺寸可能降低成本,但可能会牺牲一些性能。
数据类型: 你嵌入 的数据类型(如文本、图片)可能影响 相应的维度计数。
模型限制:一些模型有特定的尺寸限制,例如 某些OpenAI模型的1998 年版本。
用例: 嵌入 模型的具体用例 (例如自然语言处理、推荐系统)可能决定最优的维数。
当你输入文本、图片等信息,会被对一个映射为向量坐标或值
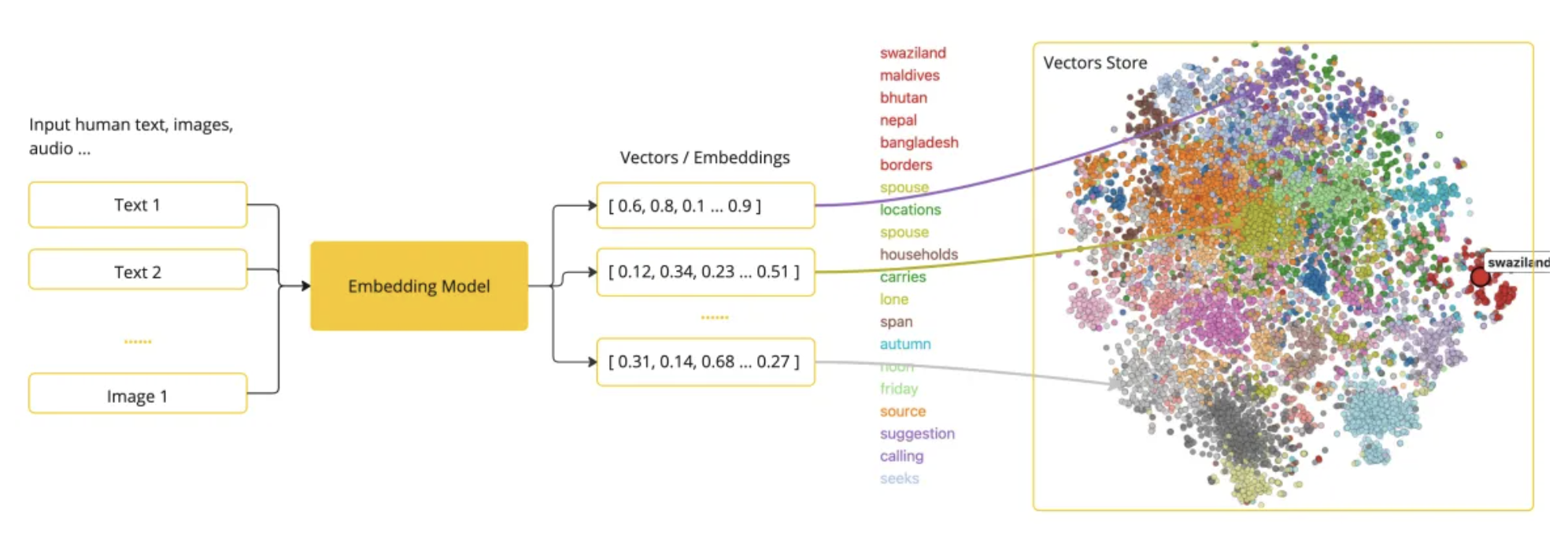
参考:
https://criticalmynd.medium.com/understanding-llm-token-counts-what-1-000-128-000-and-1-million-tokens-actually-mean-9751131ac197
https://medium.com/@johnmunn/the-context-window-illusion-why-your-128k-tokens-arent-working-d224d8219bae
https://blog.driftingruby.com/ollama-context-window/ (实战)
https://notes.kodekloud.com/docs/Running-Local-LLMs-With-Ollama/Getting-Started-With-Ollama/Models-and-Model-Parameters
https://www.bolddata.org/blog/how-many-words-128k-tokens
https://datanorth.ai/blog/context-length
https://agi-sphere.com/context-length/
https://arxiv.org/abs/2306.15595
https://agi-sphere.com/context-length/
https://huggingface.co/spaces/hesamation/primer-llm-embedding
https://www.ibm.com/think/topics/embedding
https://blog.csdn.net/m0_56255097/article/details/144396461

 浙公网安备 33010602011771号
浙公网安备 33010602011771号