
AI利器,Ollama本地启动并运行大型语言模型
什么是 Ollama ?正如 Ollama 官方仓库所说:本地启动并运行大型语言模型。 Ollama仓库创建于 2023年6月26日。
Get up and running with OpenAI gpt-oss, DeepSeek-R1, Gemma 3 and other models.
官方网站:
https://github.com/ollama/ollama
https://ollamacn.com/
https://ollama.com/
与基于云端的语言模型服务不同,Ollama 用户可以在自己的本地设备上运行语言模型,Ollama 是一个开源的大型语言模型服务工具,旨在帮助用户快速在本地运行和测试大模型。通过简单的指令,用户就可以通过一条条命令轻松启动和运行开源的大型语言模型。 它提供了一个简洁易用的命令行界面,专为本地构建大型语言模型应用而设计。用户可以在https://ollama.com/models 看到支持的各种开源大数据模型。
Ollama 用Docker 容器安装的方式,极大地简化了部署和管理大型语言模型的过程,官方的docker镜像在这里下载 https://hub.docker.com/r/ollama/ollama
Ollama 及其支持的模型完全开源且免费,用户可以随时访问和使用这些资源,而无需支付任何费用。
源码地址: https://github.com/ollama/ollama
ollama 用的go语言进行的开发,你可以自己编译ollama
Ollama 无需复杂的配置和安装过程,只需几条简单的命令即可启动和运行,为用户节省了大量时间和精力。 Ollama 支持包括 Llama3.1、Gemma2、Qwen2 在内的众多热门开源 LLM,用户可以轻松一键下载和切换模型,享受丰富的选择 。。Ollama 将模型权重、配置和数据捆绑成一个包,定义为 Modelfile,使得模型管理更加简便和高效。 Ollama 支持使用 Llama 3.1 等模型进行工具调用。这使模型能够使用它所知道的工具来响应给定的提示,从而使模型能够执行更复杂的任务。 Ollama 优化了设置和配置细节,包括 GPU 使用情况,从而提高了模型运行的效率,确保在资源有限的环境下也能顺畅运行。 Ollama 所有数据处理都在本地机器上完成,可以保护用户的隐私。 Ollama 拥有一个庞大且活跃的社区,用户可以轻松获取帮助、分享经验,并积极参与到模型的开发和改进中,共同推动项目的发展。
Ollama 提供了多种安装方式,支持 Mac、Linux 和 Windows 平台,并提供 Docker 镜像,满足不同用户的需求。
Windows系统官方建议从官网下载安装包,安装时会自动配置环境变量,默认安装路径为C:\Users\[用户名]\AppData\Local\Programs\Ollama。Linux/macOS用户可通过curl -fsSL https://ollama.ai/install.sh | sh完成安装,Docker用户使用 docker pull ollama/ollama获取镜像。内存配置方面,7B模型需8GB内存,13B模型需16GB,33B模型建议32GB以上内存环境。
举例: Ollama windows 本地部署全流程演示
1. 进入Ollama 官网 https://ollama.com/ ,点击“Download”按钮。
选择操作系统(以Windows为例),点击下载 https://ollama.com/download/OllamaSetup.exe , 下载完成后,得到“OllamaSetup.exe”文件,运行该文件。
点击“Install”开始安装,按照提示完成安装。
2.安装完成后,在开始菜单中搜索“cmd”,打开“命令提示符”。
在“ 命令提示符”中输入“ollama”,按回车键,如果看到下面的输出,说明Ollama已正确安装。

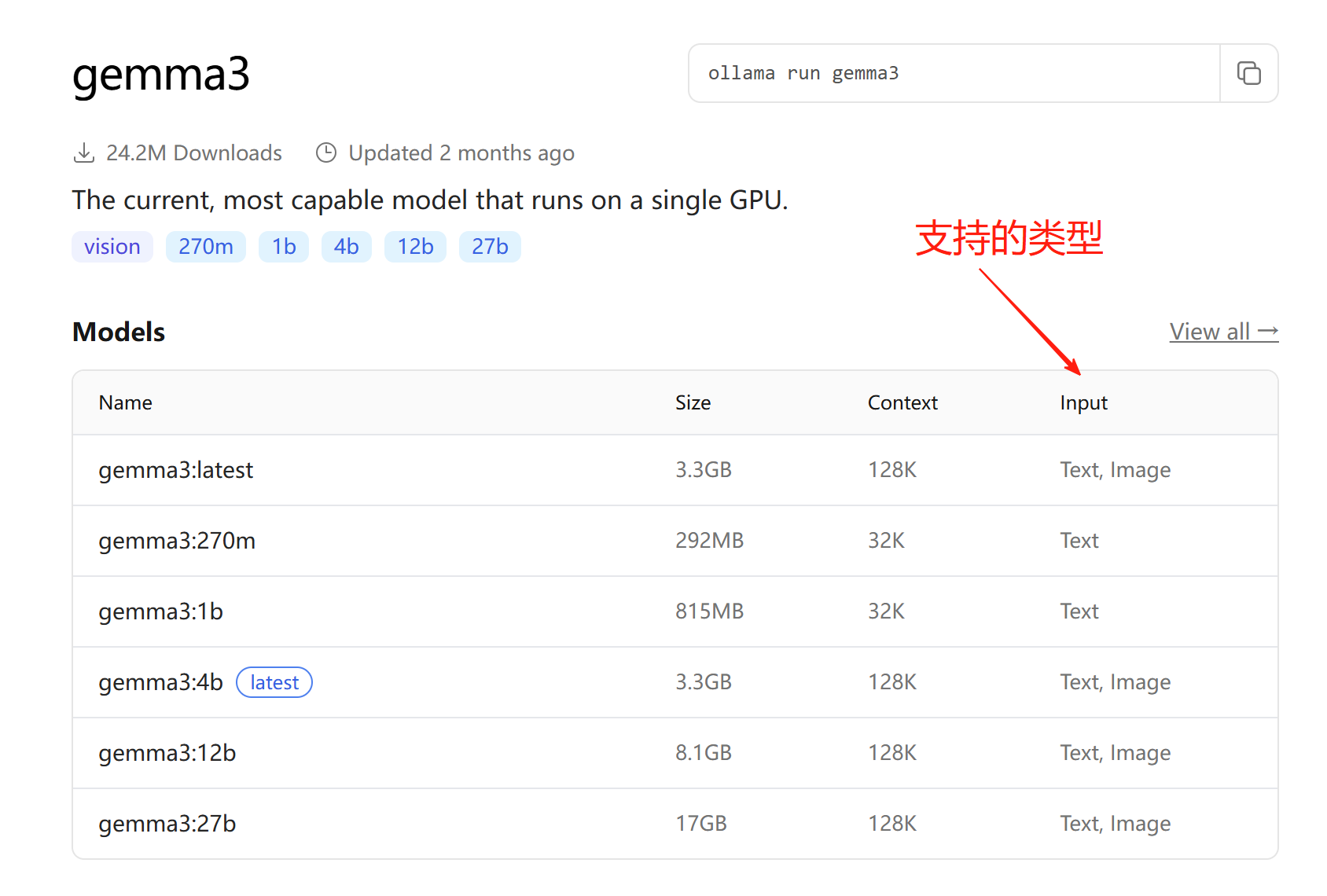
3. ollama安装默认模型 gemma3
https://ollama.com/library/gemma3
4.安装其他模型
你也可回到Ollama官网首页,点击最上方的“Search models”,选择一个模型,例如 “qwen3-vl:2b”。
https://ollama.com/library/qwen3-vl
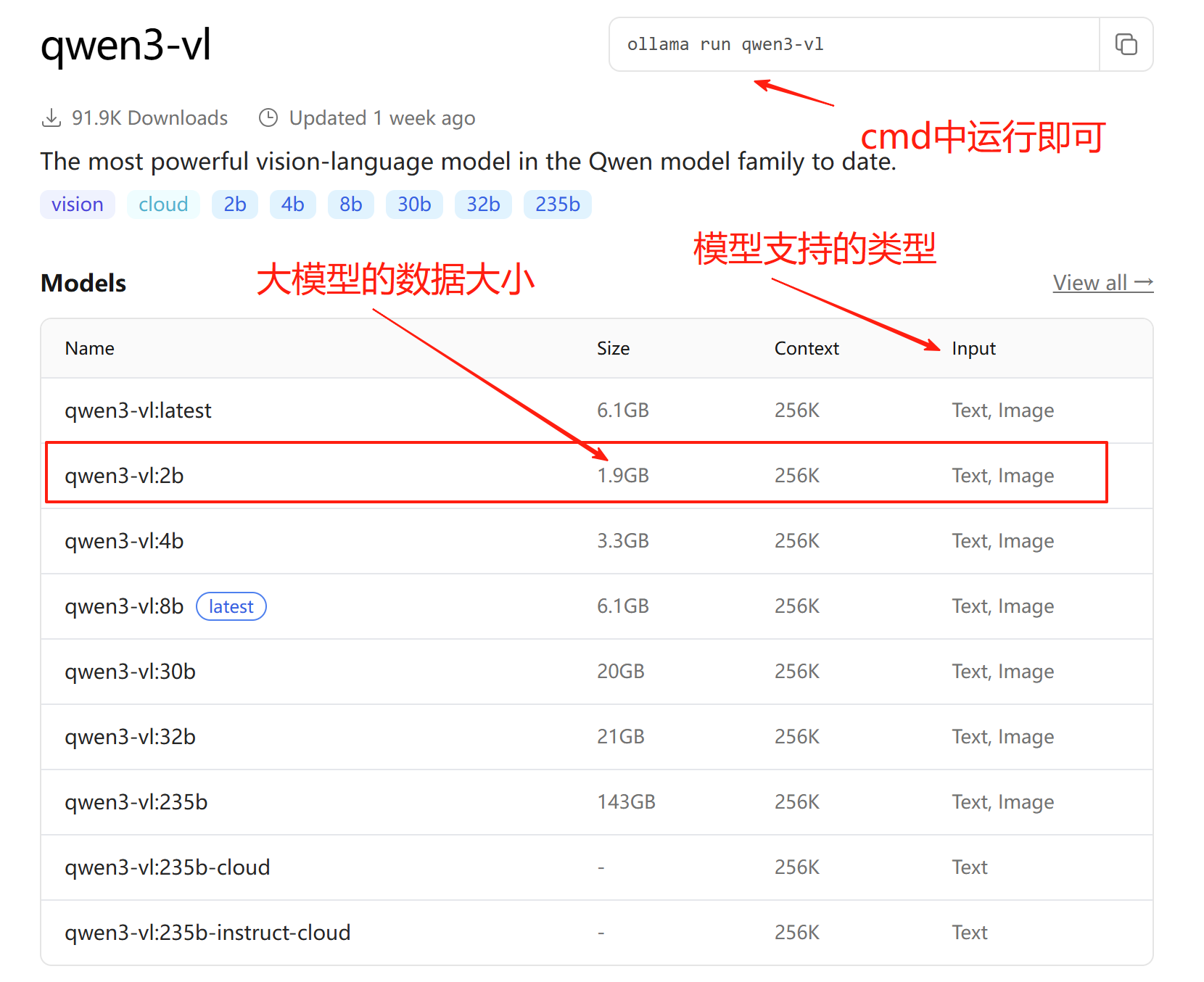
大模型的“2b”、“32b”等指标代表模型的参数量级,比如“2b”表示模型参数有20亿个,“32b”表示参数有320亿个,这个数字越大,模型越复杂,性能也越好,但代价是电脑配置要求更高。比如,1.5b要求至少1G显存,7b、8b是6G显存、14b是11G显存、32b是22G显存、70b是80G显存等。 我选择了更低的2b,保证运行
下载该模型

运行命令 ollama run qwen3-vl:2b,等待下载完成(可能需要一些时间)。
5. 在“命令提示符”中输入“ollama list”,按回车键 ,显示目前已下载的模型列表

在“命令提示符”中输入“ollama run gemma3” ,按回车键。
![]()
如果想退出,只要ctrl+d即可

7.简单使用
首先运行模型,然后你可以输入中文或英文文字以及拖拽图片到命令行窗口 ,比如今天吃什么
|
C:\Users\king>ollama run qwen3-vl:2b 首先得分析用户可能的情况。可能用户现在很饿,或者正在计划一天的饮食,也有可能是开玩笑或者测试我的反应。不过更可能的是 然后要考虑用户的潜在需求。比如,用户可能想吃点健康的,或者想省钱,或者想吃点特别的东西。不过用户没有说,所以得保持通 接下来,得确定回答的方向。比如,用户可能只是想要一个简单的答案,但作为AI,得给出全面一点的建议。不过用户可能希望我给 另外,可能用户有潜在的需求,比如最近有没有什么健康的食物,或者有没有什么特别的食物。不过这些都是推测,得基于常见情况 然后要考虑语言风格。用户问“今天吃什么”,可能是在手机上随便问的,所以语气要轻松,友好一点,不用太学术。比如,用“今 还要注意用户可能存在的文化背景。比如,在中国,可能更倾向于推荐一些常见的食物,比如米饭、面条、蔬菜之类的。所以可以提 另外,用户可能有其他需求,比如想吃点有营养的,或者想吃点特别的。所以得考虑提供多样化,比如有些食物可能有不同营养搭配 然后思考如何组织回答。首先给出一个推荐,比如推荐一顿饭,然后提供几个选项,这样用户可以有选择。同时,提醒用户注意食材 最后,检查是否有遗漏的情况。比如,用户可能在问是否有什么特别的东西,比如点外卖之类的。不过这些是推测,得确保回答有普 现在总结一下:用户问“今天吃什么”,可能需要推荐一种适合当天的健康食品,给出具体的例子,比如推荐炒饭、面食等。注意回 今天可以试试**番茄炒蛋+清炒时蔬**,这样既营养又快手! 🥗 **小贴士**: 需要我帮你规划一份早餐/晚餐方案吗?可以告诉我你想要的口味(比如清淡/香辣)或者偏好(比如素食/荤食),我来给你详细推 |
8.ollama 的命令使用
1)显示模型的信息
|
C:\Users\king>ollama show qwen3-vl:2b Capabilities Parameters License |
2) 显示其他参数
|
C:\Users\king>ollama Available Commands: 有效命令如下 Flags: Use "ollama [command] --help" for more information about a command. |
根据命令我们来做下示例:
| 命令 | 命令说明 | 示例 |
|---|---|---|
ollama run |
运行模型。如果不存在则自动拉取、下载。 | ollama run qwen3-vl:2b |
ollama pull |
拉取模型。从远程库中下载模型但不运行。 | ollama pull qwen3-vl:2b |
ollama list |
列出模型。显示本地所有已下载的模型。 |
D:\ollama>ollama list |
ollama rm |
删除模型。移除本地模型释放空间。 | ollama rm qwen3-vl:2b |
ollama cp |
复制模型。将现有模型复制为新名称(用于测试)。 | ollama cp qwen3-vl:2b testmodel |
ollama create |
创建模型。根据 Modelfile 创建自定义模型(高级)。 | ollama create mymodel -f ./qwen3-vl:2b |
ollama show |
显示信息。查看模型的元数据、参数或 Modelfile。 |
D:\ollama>ollama show --modelfile qwen3-vl:2b |
ollama ps |
查看进程。显示当前正在运行的模型及显存占用。 |
例如: D:\ollama>ollama ps #只有你提出问题之后,你才会看到上面的信息 |
ollama push |
推送模型。将你自定义的模型上传到 ollama.com。 | ollama push my-username/my-model |
ollama serve |
启动服务。启动 Ollama 的 API 服务(通常后台自动运行)。 | ollama serve (一般用于你编写的python调用模型脚本时,先启动ollama服务) |
ollama help |
帮助。查看任何命令的帮助信息。 |
.... |
9.切换思考模式
C:\Users\king>ollama run qwen3-vl:2b >>> /set think Set 'think' mode. #已切换到深度思考模式
>>> /set nothink
Set 'nothink' mode. #已切换到非深度思考模式(不思考或会忽略一些问题)
>>> /? Available Commands: /set Set session variables /show Show model information /load <model> Load a session or model /save <model> Save your current session /clear Clear session context /bye Exit /?, /help Help for a command /? shortcuts Help for keyboard shortcuts Use """ to begin a multi-line message. Use \path\to\file to include .jpg, .png, or .webp images. >>> Send a message (/? for help)
通过这两个指令就能实现思考模式的切换
注:在新版的ollama指令已经抛弃掉了/set no_think指令,若使用/set nothink失败的话则为旧版ollama,可以手动升级ollama版本
10.测试api
需要启动rest api server (ollama serve...)
更多 api命令:https://github.com/ollama/ollama/blob/main/docs/api.md (ollama api命令)
1.命令行下启动键入 ollama serve (默认端口为11343) 注意: ollama run 模型(ollama list 列出来的选一个),他们可以同时启动 2.启动cygwin: 发出指令 $ curl http://localhost:11434/api/generate -d '{ "model": "qwen3-vl:2b", #我安装的模型 "prompt":"冬天喝什么茶好?", #提出的问题 "stream":false }' #需要等待一段时间响应... {"model":"qwen3-vl:2b","created_at":"2025-12-01T01:30:30.9051726Z","response":"在寒冷的冬季,选择合适的茶饮不仅能温暖身心,还能提升健康状态。
以下是针对冬季的茶饮推荐及科学依据,结合中医理论、现代营养学和日常养生实践,为你提供**安全、实用、可操作**的建议:\n\n---\n\n### 🌡️
**一、冬季喝茶的科学原理**\n**核心原则:温热、养胃、不伤阳气** \n冬季气候寒冷,人体易出现“阳虚”状态(表现为怕冷、手脚冰凉),
中医认 为“阴盛阳虚”的人需要温热饮品,而现代营养学认为,温热饮品能促进血液循环、缓解关节僵硬,同时避免冷饮刺激肠胃。\n\n**注意事项:**
\n- ❌ **避免喝太烫的茶**:过热茶会损伤消化道黏膜,影响消化功能。
\n- ✅ **推荐温热程度**:茶汤温度适中(约60-70℃),既可暖胃又避免烫伤。\n\n---\n\n### 🌺 **二、冬季最适合的茶类推荐**\n#### **1. 红茶(推荐指数:
.... 其他省略...
11.llama3
ollama llama3 模型:https://ollama.com/library/llama3
一个详细介绍llama3 blog: https://ai.meta.com/blog/meta-llama-3/
llama4地址 : https://ollama.com/library/llama4
llama3 2024年4月上线 简短介绍 Meta Llama 3:迄今为止最强大的公开大型语言模型,Meta Llama 3 是由 Meta Inc. 开发的一系列模型,是全新的最先进产品,提供 8B 和 70B 参数大小(预训练或指令调优)。 Llama 3 的指令调优模型针对对话/聊天场景进行了精细调优,并在常见基准测试中优于许多现有的开源聊天模型。 1.打开cmd终端 ollama run llama3 2.应用程序接口 curl -X POST http://localhost:11434/api/generate -d '{ "model": "llama3", #前提你使用ollama run llama3或 ollama pull llama3 把模型下载下来 "prompt":"Why is the sky blue?" }' #你就可以编写程序,对接 ollama 暴露的 http://localhost:11434/ 端口进行交互 3.ollama api指南 https://github.com/ollama/ollama/blob/main/docs/api.md 4.llama3官网 https://www.llama.com/docs/model-cards-and-prompt-formats/llama4/ 目前已到llama4
参考:
https://github.com/ollama/ollama/blob/main/docs/api.md (ollama api命令)
https://github.com/orgs/huggingface/repositories?type=all
huggingface

 浙公网安备 33010602011771号
浙公网安备 33010602011771号