
崩溃日志是怎么生成的?
前言
为什么我们程序崩溃后,会有崩溃日志呢?
初学者可能会想,如果进程都直接崩溃了,那不就什么都没了?
但是我们忽略了一点,那就是我们的进程是谁杀死的?
是cpu吗?cpu 似乎不管进程这个概念,只是一味地执行指令。
那么进程这个概念是在操作系统中的概念,那么杀死进程的是我们的操作系统。
我们的操作系统可以告诉我们这个进程为什么被杀死,比如内存不足了,比如死锁?还是其他原因,这个似乎是ok的。
那么来看一下细节吧。
正文
- 崩溃瞬间的捕获机制
a. 当进程触发非法操作(如段错误/除零异常)时,CPU会立即产生硬件中断
b. 操作系统预先注册的中断处理程序(如Linux的do_page_fault())会接管控制权
c. 此时崩溃进程被冻结,但操作系统内核仍正常运转
- 日志写入的保障体系
a. 内核态日志缓冲区:崩溃信息先存入内核的ring buffer(如Linux的kmsg),这个区域与用户进程内存隔离
b. 同步写入策略:内核直接调用文件系统驱动,绕过用户态缓存(采用O_SYNC方式写入磁盘)
c. 预留磁盘空间:现代系统通常为日志文件保留固定磁盘区块(如journald的持久化存储)
- 关键数据采集阶段
a. 寄存器快照:第一时间保存RIP/EIP等寄存器值以定位崩溃点
b. 内存映射备份:记录/proc/pid/maps内容以重建虚拟内存布局
c. 信号上下文:保存引发崩溃的signal number和siginfo_t结构体
- 跨进程协作设计
a. 日志守护进程:如syslogd/journald通过netlink socket实时接收内核通知
b. 核心转储机制:通过管道将core dump传递给abrtd等服务(即使原进程已终止)
c. 双重缓冲技术:内存缓冲+磁盘缓冲确保极端情况下数据不丢失
// 内核处理段错误的简化流程
void do_page_fault(...) {
if (user_mode(regs)) {
char buf[256];
snprintf(buf, sizeof(buf), "Process %s[%d] segfault at %lx",
current->comm, current->pid, address);
kmsg_write(buf); // 直接写入内核日志缓冲区
// 触发核心转储
if (current->signal->rlim[RLIMIT_CORE].rlim_cur > 0) {
do_coredump(...);
}
}
die_if_kernel(...);
}
- 硬件辅助支持
a. MCA架构:现代CPU的Machine Check Architecture可记录硬件级错误
b. NMI中断:不可屏蔽中断保证在最严重崩溃时仍能执行日志代码
c. TPM芯片:部分服务器通过可信平台模块存储崩溃指纹
把具体流程记一下:
-
T0: CPU 检测到非法指令(如 mov [0], eax)
-
T0+1ns: 触发 #PF 异常,硬件自动保存 RIP 到 CR2 寄存器
-
T0+10μs: 内核的 do_page_fault 开始执行
-
T0+100μs: 调用 printk 写入内核日志缓冲区
-
T0+1ms: systemd-journald 从 netlink 读取日志并存入 /var/log/journal
-
T0+50ms: 核心转储通过管道传递给 abrtd 服务
那么这个abrtd服务是干什么呢?
ABRT 全称脚本 automatic bug reportig tool, 自动bug报告工具。

# 检查服务状态
systemctl status abrtd
# 启用服务(开机自启)
sudo systemctl enable --now abrtd
# 手动触发崩溃收集测试(测试用)
kill -ABRT $$
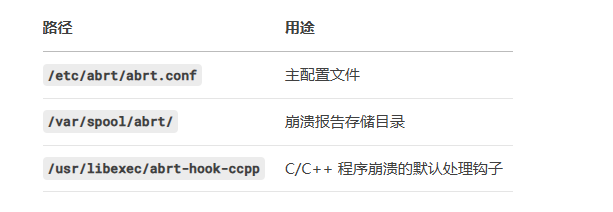
- 核心功能
a. 自动崩溃检测:监控系统信号(如 SIGSEGV、SIGABRT)和内核通知。
b. 数据收集:保存崩溃时的核心转储(core dump)、堆栈跟踪、寄存器状态、环境变量等。
c. 报告生成:结构化存储崩溃信息,支持本地分析或上报至开发者(如 Red Hat Bugzilla)。
d. 用户通知:通过桌面弹窗或日志告知用户崩溃事件(需图形环境支持)。
处理流程:
a. 崩溃触发:应用程序因非法操作(如空指针访问)崩溃,内核发送信号(如 SIGSEGV)。
b. 事件捕获
abrtd 通过以下方式捕获事件:
监听 /proc/sys/kernel/core_pattern 管道(如 |/usr/libexec/abrt-hook-ccpp %s %c %p %u %g %t e %P %I %h)。
解析内核日志(dmesg)或进程退出状态。
c. 数据收集
在 /var/spool/abrt/ 下创建目录,保存以下文件:
/var/spool/abrt/ccpp-2024-06-30-15:00:00-12345/
├── coredump # 核心转储(二进制内存镜像)
├── backtrace # 堆栈回溯(gdb生成)
├── cmdline # 进程启动命令
├── environ # 环境变量
└── package # 关联的软件包(如nginx-1.18.0-3.el8)
- 后续处理
本地分析(通过 abrt-cli 或 gnome-abrt)。
自动上报至配置的远程服务器(需用户授权)。
那么有时候为什么我们c#的时候通过journalctl能够查到具体的错误呢?
理论上不应该啊,比如触发了cpu的问题,然后cpu告诉操作系统,操作系统怎么能够捕获到c#的详细错误呢?
操作系统能告知的只有错误码,比如说被除数是0,又或者内存不足oom了。
这些似乎是操作系统能够告知的, 其他的平台信息是操作系统如何知道的,那么问题就回到了操作系统是怎么和.net 平台就行交互的。
(1).NET 运行时与操作系统的交互
未处理异常:当 C# 程序抛出未捕获的异常时,.NET 运行时(如 dotnet 或 mono)会:
- 调用 libc 的 abort() 或触发 SIGABRT/SIGSEGV 信号
- 通过 stderr 输出异常堆栈(如果未重定向)
信号传递:操作系统内核捕获信号后,将进程崩溃事件记录到系统日志(通过 printk 或 syslog)
(2)日志传递路径
flowchart LR
C#程序 -->|抛出异常| .NET运行时 -->|调用abort()| libc -->|触发SIGABRT| 内核 -->|记录到kmsg| journald --> journalctl
请看我们这里的journald是捕获内核信息的,是一些操作系统的内核错误信息的,但是我们好像在journald 能查看到stderr,也就是错误标准输出。
这是为啥呢? 有没有可能是改变了stderr的输出位置呢?
(1)C# 程序输出异常到 stderr
当发生未处理异常时,.NET 运行时会默认将异常信息写入标准错误流(stderr):
// CLR 内部行为(伪代码)
Console.Error.WriteLine($"Unhandled Exception: {exception.ToString()}");
Environment.Exit(1); // 或调用 abort() 触发 SIGABRT
(2)Docker/Systemd 捕获 stderr
若程序在终端中运行:stderr 直接输出到终端,但不会被 journald 捕获。
若程序由 systemd 或 Docker 管理:
systemd 服务单元:自动将 stdout/stderr 重定向到 journald。
Docker 默认配置:日志驱动(如 json-file)会捕获 stderr,但需配置 journald 驱动才能转发到 journald。
(3)journald 接收日志
日志来源:
应用程序:通过 sd_journal_print() 或 stderr 重定向。
系统服务:如 Docker 的 journald 驱动。
结构化存储:
# 查看日志的原始字段
journalctl -o json-pretty CONTAINER_NAME=myapp
输出示例:
{
"__MONOTONIC_TIMESTAMP": "1234567890",
"_TRANSPORT": "stderr",
"MESSAGE": "Unhandled Exception: System.NullReferenceException...",
"CONTAINER_ID": "abcd1234",
"_PID": "5678"
}
(4)journalctl 过滤显示
通过字段匹配查询特定异常:
journalctl _TRANSPORT=stderr | grep "Unhandled Exception"
- 不同场景下的日志传递
场景 1:原生 systemd 服务
# /etc/systemd/system/myapp.service
[Service]
ExecStart=/usr/bin/dotnet /app/MyApp.dll
StandardError=journal # 显式重定向 stderr 到 journald
此时所有 stderr 输出(包括未处理异常)会被 journald 捕获。
场景 2:Docker 容器
# 使用 journald 日志驱动运行容器
docker run --log-driver=journald myapp
场景 3:直接终端运行
dotnet MyApp.dll # 直接输出到终端,journald 不捕获
需手动重定向:
dotnet MyApp.dll 2>&1 | systemd-cat -t myapp
结
暂时先这样吧,简单介绍一下崩溃日志是怎么产生的,又是为什么我们能够看到的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号