
Python爬取 豆瓣急先锋 电影评论 ,龙叔的电影居然分这么低
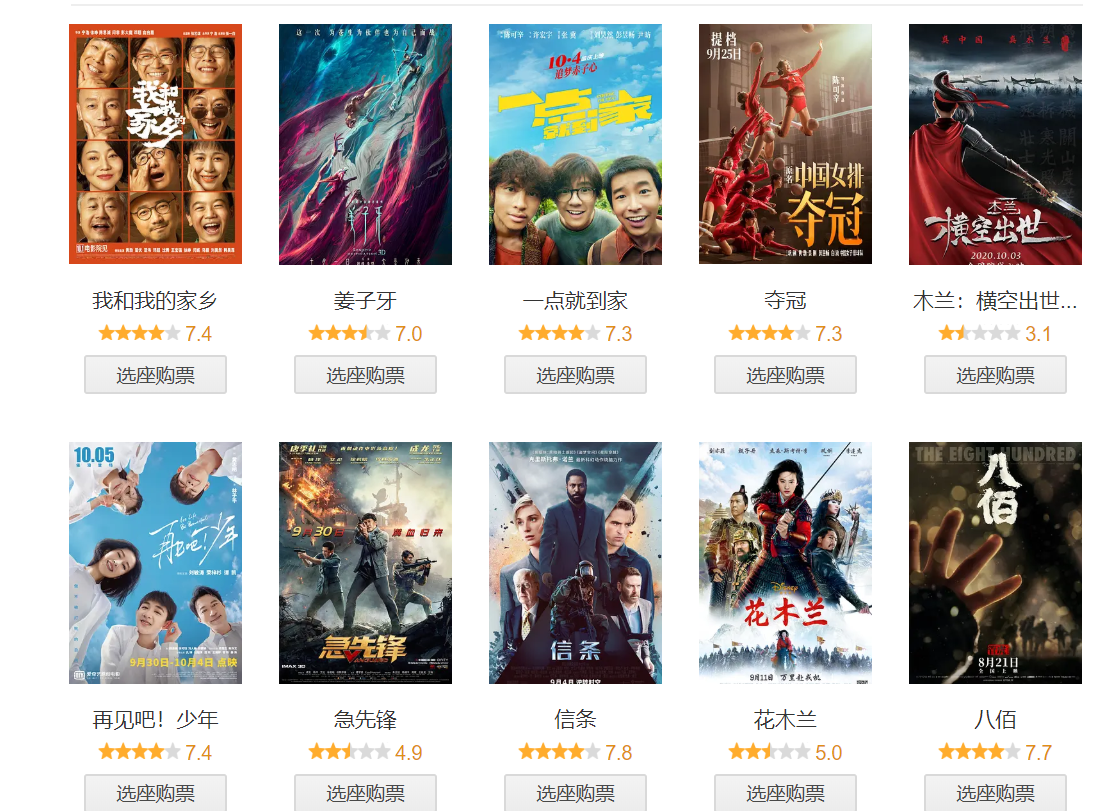
豆瓣电影首页,亮丽的风景,居然这么低的分,和同是国庆党电影差距这么大,唯一低分的还是国产木兰,差不多低分的居然是女神 刘亦菲,从小看龙叔电影、刘亦菲剑仙的人,不服了,看看评论是则么说的。
首先用python 爬取已经评论的500多条评论,剩余200多条是没看就评论的,不抓取了。
jianping = response.css('.main-bd a:nth-of-type(1)::text').extract() jianping1 = [] for jianping2 in jianping: r = re.findall(r'[^ \n]', jianping2) # 去除 特殊符号 r = ''.join(r) # 转元组 jianping1.append(r) while '' in jianping1: jianping1.remove('') while '展开' in jianping1: jianping1.remove('展开')
然后用词云转换下,看下评论都说了啥
listOfFileName.append('急先锋') listOfFileName.append('急先锋观后感') listOfFileName.append('急先锋影评') listOfFileName.append('影评') listOfFileName.append('观后感') sw = listOfFileName
去掉浑水的评论

看完大家评论的,还是大部分觉得挺好看的,就是龙叔老了,没啥打斗场面了,来了很多小鲜肉。
然后我们看看为啥评分这么低,

看到15570条,但是豆瓣牛毕,我们只能抓100条,根本无法了解什么,我就抓取他的全部影评,
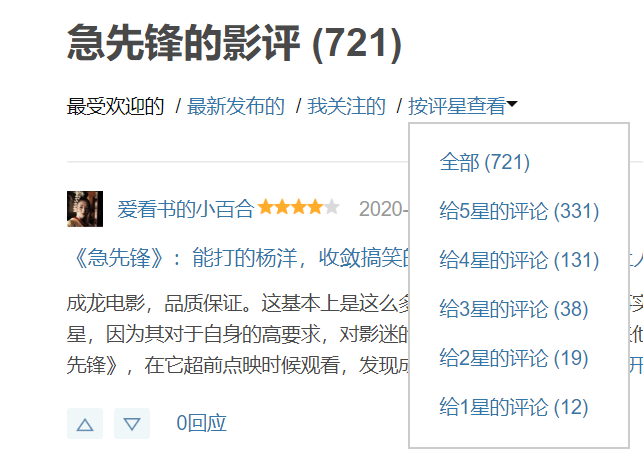
大部分都是5星好评,但是豆瓣会屏蔽掉,,

豆瓣给的解释
不管,我们抓取下来分析下,
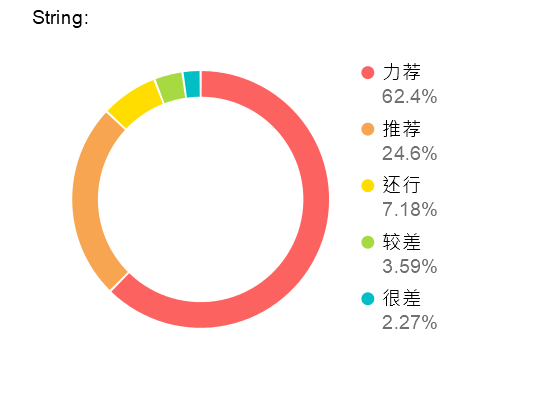
几乎给的都是满星,但是依旧阻挡不了4.9分的命运,明天抓国庆热档其他电影,究竟有多好看,评分这么高。
最后源码:
import scrapy import re import csv class Xianfeng(scrapy.Spider): name= 'xianfeng' def start_requests(self): headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' 'cook' } urls = ['https://movie.douban.com/subject/27195078/reviews?start=%d' % page for page in range(0, 720, 20)] for url in urls: yield scrapy.Request(url,headers=headers, callback=self.parse) def parse(self,response): mingzi = response.css('.review-list a:nth-of-type(2)::text').extract() mingzi1 = [] for mingzi2 in mingzi: d = re.findall(r'[^ \n]', mingzi2) # 去除 特殊符号 d = ''.join(d) # 转元组 mingzi1.append(d) while '' in mingzi1: mingzi1.remove('') pingfen = response.css('.review-list span:nth-of-type(1)::attr(title)').extract() pingfen1= [] for pingfen2 in pingfen: pingfen1.append(pingfen2) shijian = response.css('.review-list span:nth-of-type(2)::text').extract() shijian1= [] for shijian2 in shijian: shijian1.append(shijian2) jianping = response.css('.main-bd a:nth-of-type(1)::text').extract() jianping1 = [] for jianping2 in jianping: r = re.findall(r'[^ \n]', jianping2) # 去除 特殊符号 r = ''.join(r) # 转元组 jianping1.append(r) while '' in jianping1: jianping1.remove('') while '展开' in jianping1: jianping1.remove('展开') ''' duanping = response.xpath('//*[@id ="link-report"]/div/p//text()').extract() duanping1=[] for duanping2 in duanping: duanping1.append(duanping2) ''' print('---------write------------------') for i in range(len(pingfen1)): fileName = '评分.txt' f = open(fileName, "a+",encoding='utf-8') content = pingfen1[i] + '\n' f.write(content) f.close() for t in range(len(jianping1)): fileName1 = '简评.txt' f1 = open(fileName1, "a+",encoding='utf-8') content1 = jianping1[t] + '\n' f1.write(content1) f1.close() # 3. 构建列表头 for g in range(len(mingzi1)): with open('xianfeng.csv', 'a', encoding='utf-8_sig') as f: const= mingzi1[g]+ ',' + pingfen1[g] + ',' + shijian1[g] + ',' + jianping1[g] + '\n' f.write(const) f.close()
如果人生还有重来,那就不叫人生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号