ASR概念和术语学习指南(1):任务定义与输入输出
如果你用过语音助手、字幕生成工具,或者会议转录软件,那你其实已经和 自动语音识别(ASR, Automatic Speech Recognition)打过不少交道了。简单来说,ASR 的目标就是:把人类说的话,变成计算机能理解的文字。
听起来好像不难?但想想看——不同人说话的口音、语速、情绪千差万别,背景里可能还有键盘声、狗叫、地铁轰鸣……而语音本身又是连续流动的,根本没有“单词”之间的空格。要在这种混乱中准确还原出说话内容,其实是一项相当复杂的工程挑战。
不过别担心!即使你完全没有音频处理的经验,我们这一系列文章会带你一步步拆解 ASR 的核心原理(本系列文章主要介绍ASR中的相关概念和术语,并不涉及代码实操)。今天是第1篇,我们先从最基础的问题开始:ASR 到底要解决什么问题?它的输入和输出又是什么?
1.1 ASR 的任务定义:把“声音流”变成“文字流”
我们可以用一句话概括 ASR 的核心任务:
给定一段语音(即连续的声音波形),系统要输出对应的文字序列。
具体来看:
- 输入:一段随时间变化的音频信号(比如 .wav 文件)
- 输出:一串文字,可能是中文句子、英文单词,甚至是标点符号
所以,ASR 不只是“听声音”,它本质上是在建模人类语言的声学表现与文字之间的映射关系。接下来,我们就来看看这个“声音”到底长什么样,以及计算机是如何“看懂”它的。
1.2 声音的表示:计算机如何“理解”音频?
声音本质上是空气中的压力波动。当我们说话时,声带振动引起空气分子震荡,这些震荡被麦克风捕捉后,就变成了一串数字——这就是音频的原始形式。但直接拿这串数字去训练模型?效率太低,信息也太“原始”。
于是,我们需要对声音进行特征提取(Feature Extraction)——也就是把原始波形转化成更适合机器学习模型处理的表示形式。这个过程就像给声音“拍照+分析”,一步步提炼出有用的信息。
1.2.1 波形(Waveform):声音的“原始照片”
- 波形是最直接的数字表示:横轴是时间,纵轴是振幅(声音大小)。当我们打开音频波形处理工具软件(比如Audition、Audacity等)看一段录音时,看到的就是波形图。
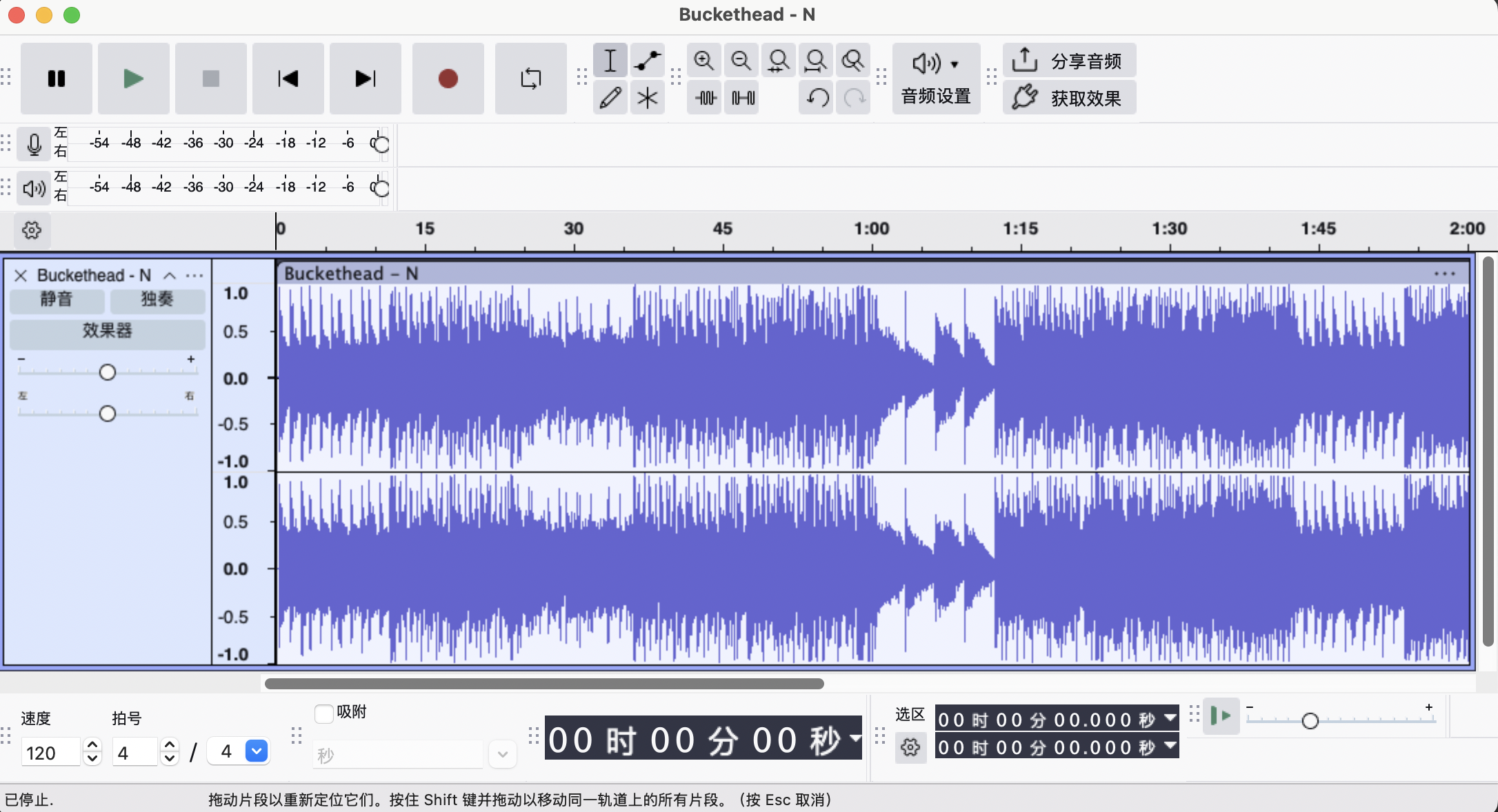
- 它保留了全部信息,但对模型来说太“粗糙”——就像直接喂给模型一整部高清电影,让它自己找剧情。
类比一下:如果你让一个从未见过足球的人只看比赛录像来学会踢球,他可能会被太多无关细节淹没。更好的方式是先教他“传球”“射门”这些基本动作——特征提取就是干这个的。
1.2.2 分帧(Framing):把长视频切成重叠的“快照”
因为语音是连续的,我们通常把它切成小段来分析,每一段叫一个 帧(Frame):
- 每帧长度一般为 20–40 毫秒(大约是一个音素的持续时间)
还有一个概念叫做 帧移(Hop Size),即当前帧的开始时间与下一个帧的开始时间相差的时间,这个值通常比帧长要短,因此不同帧之间会出现重叠的部分,
为什么重叠?
重叠分帧能使得特征连续较为连续,确保短促的发音(比如“p”、“t”这样的爆破音)不会被切掉。
1.2.3 短时傅里叶变换(STFT):从“音量”看到“音色”
人说话不只是“大声”或“小声”,更重要的是不同频率成分的组合——比如男声低沉(低频多),女声清亮(高频丰富)。
STFT(Short-Time Fourier Transform)就能帮我们把每一帧的波形,转换成频率-能量图谱,也就是频谱(Spectrogram),其中包含了不同频率声音的强度信息。
举个例子:
如果波形是一锅混合汤,STFT 就相当于把汤里的盐、糖、香料分开,并告诉你每种成分有多少。
在Audacity和Audition等音频处理工具软件中,也可以将默认的波形图视图调整成频谱图视图,如图:
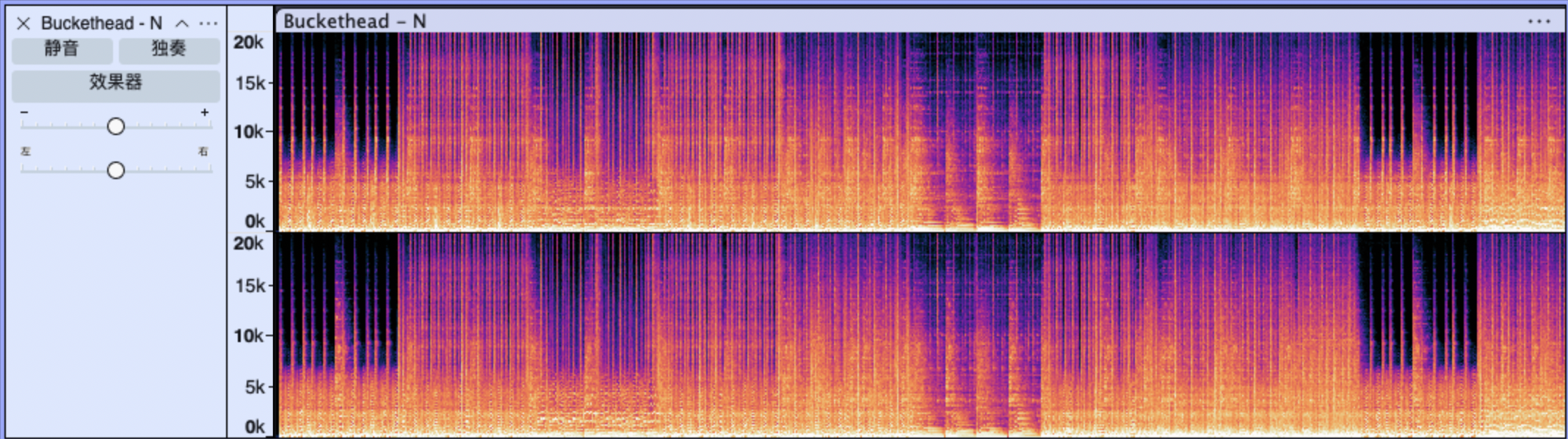
其中横轴是时间,纵轴代表频率。黄色表示功率高的频率部分,蓝色表示功率低的频率部分
1.2.4 Mel 滤波器:模拟人耳的“听觉偏好”
有趣的是,人耳对频率的感知并不是线性的——我们对低频变化更敏感(比如 100Hz 和 200Hz 差别明显),但对高频就不那么敏感(比如 8000Hz 和 8100Hz 几乎听不出区别)。
Mel 滤波器正是基于这种心理声学特性设计的:它把线性频谱重新映射到 Mel 尺度 上,再用一组三角形滤波器对能量进行加权平均,最终得到 Mel 频谱(Mel-Spectrogram)。
你可以这么想:
Mel 滤波器就像一副“人耳专用眼镜”,戴上之后,看到的声音世界更接近我们实际听到的样子。
在Audacity中,也可以将频谱图的纵轴分布由线性改为梅尔刻度,可以看到0-10000Hz占据了绝大多数的纵轴,而10000-19000Hz则只占据了很小的一部分
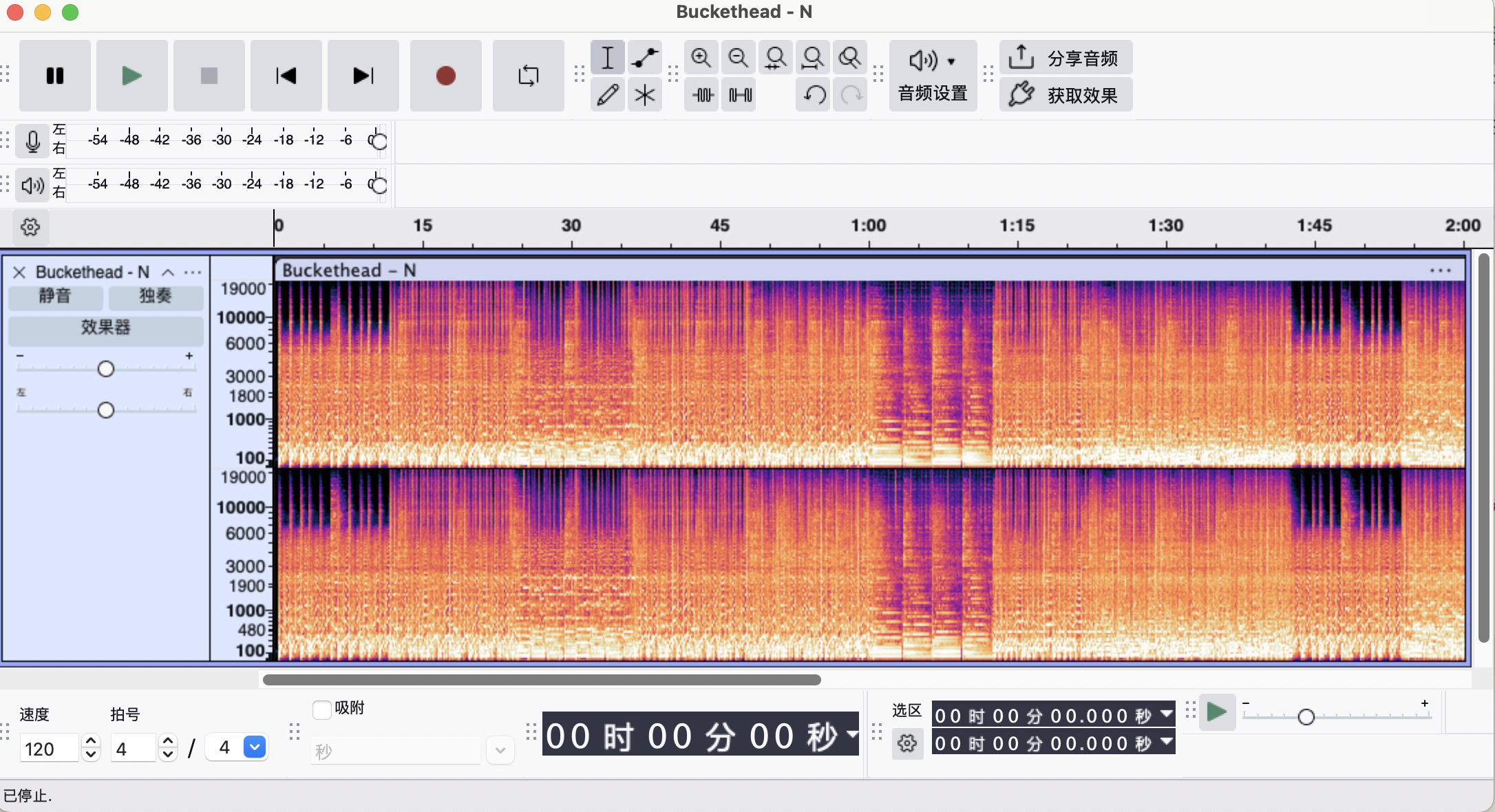
1.2.4.1 滤波器组系数(Filter Bank coefficients, FBank)
在 ASR 论文中,你经常会看到模型输入被描述为 “80 维 FBank 特征”。FBank 就是梅尔频谱取对数后的结果:
FBank = log(Mel spectrogram)
对数能压缩动态范围,使特征更稳定、更适合神经网络训练。
注意:在实际工程中,“Mel-spectrogram” 和 “FBank” 常被混用,但严格来说,ASR 输入几乎 总是 log-Mel,也就是 FBank。
1.2.5 MFCC:压缩后的“语音指纹”
虽然 Mel 频谱已经很友好了,但它维度还是太高(通常有 40–80 个频带),而且相邻频带之间高度相关。
于是,传统 ASR 系统常使用 MFCC(Mel-Frequency Cepstral Coefficients)——它对 Mel 频谱做一次离散余弦变换(DCT),保留前 12–13 个系数,有效去除冗余,突出语音的音色特征(比如区分“a”和“i”的发音)。
MFCC 的作用:有点像从一张高清人脸照片中提取关键特征点(眼睛间距、鼻梁高度等),用于人脸识别——它不是完整的图像,但足够代表“你是谁”。
1.2.6 特征向量化:让声音变成模型能吃的“数字”
无论你用的是 FBank 还是 MFCC,最终都要把它们整理成固定维度的数值向量序列,才能喂给模型。
具体来说:
- 每一帧(比如 25ms)经过 STFT → Mel 滤波 → 对数压缩后,会得到一个 D 维向量(例如 D=80 的 FBank)
- 一段 T 帧长的语音,就变成了一个 T × D 的矩阵
- 这个矩阵就是 ASR 模型的标准输入,也常被称为“声学特征序列”
为什么这一步很重要?
因为神经网络(无论是 CNN、RNN 还是 Transformer)都要求输入是形状规整的张量(tensor)。“向量化”是连接物理世界(声音)与数字世界(模型)的最后一道转换门。
有时,工程师还会在这个基础上叠加一阶差分(Delta)和二阶差分(Delta-Delta),分别表示特征的变化速度和加速度,形成 3×D 维的拼接向量(如 240 维 MFCC+Δ+ΔΔ),以捕捉动态信息。不过在现代端到端系统中,这种手工设计的动态特征已逐渐被模型自动学习所取代。
1.2.7 输入特征总结
| 特征类型 | 描述 | 适用场景 |
|---|---|---|
| Waveform(波形) | 原始音频采样点 | 某些特别的端到端深度学习模型(如 Wav2Vec 2.0) |
| FBank / Mel-Spectrogram | 模拟人耳感知的频域能量 | 现代 DNN、Transformer 架构(如 Conformer),绝大多数现代ASR模型 |
| MFCC | 压缩后的倒谱特征 | 传统 HMM-GMM 或 HMM-DNN 系统 |
小贴士:近年来,随着深度学习的发展,越来越多模型使用 Mel 频谱(FBank) 作为输入,因为它比MFCC保留了更多的声学信息,又比原始波形更容易学习。
1.3 ASR 的“大脑”:模型
到目前为止,我们已经知道了 ASR 的输入(声学特征向量序列)和输出(文字单元序列)。那么,中间的“翻译工作”由谁完成?
答案是:ASR 模型——它是整个系统的“大脑”。
不过,不同年代的 ASR 使用了截然不同的“脑结构”:
- 早期系统(2000s–2010s)依赖多个模块拼装:声学模型(如 HMM-GMM)、发音词典(lexicon)、语言模型(n-gram)各自独立,靠人工规则协同;
- 现代系统(2015 年后)则倾向于端到端模型(如 CTC、Transformer、RNN-T),直接学习从声音到文字的映射,内部自动协调声学与语言知识。
先剧透一下:
后续文章会依次拆解这些架构——从传统 HMM 到 CTC ,再到大模型时代的“语音大一统”。你会发现,ASR 的演进史,本质上是一场从“人工拼装”走向“整体学习” 的范式革命。
1.4 ASR 的输出:文本到底怎么“拼”出来?
ASR 的最终目标是输出一段完整的文本,一段文本是由一个个文字单元组成的,常见的输出单元包括:
-
字符(Character)
- 比如中文每个字、英文每个字母
- 优点:词表小,无需分词;缺点:序列很长,训练慢
-
子词(Subword,如 BPE 或 WordPiece)
- 把常见词保留完整,罕见词拆成片段(如 “unhappiness” → “un”, “happy”, “ness”)
- 平衡了词表大小和序列长度,是当前主流选择
-
单词(Word)
- 直接输出完整词汇
- 直观,但词表爆炸,且无法处理 OOV(Out-of-Vocabulary)词
-
字节或编码(如 UTF-8)
- 更底层的表示,适合多语言统一建模
打个比方:输出单元就像是盖楼房——你可以用小砖块(字符)一块块砌,也可以用预制板(子词)快速组装。选哪种,取决于你追求速度、灵活性,还是简洁性。
1.5 小结
今天我们走完了 ASR 的第一站:理解任务本身。
- 任务本质:将语音音频波形 → 转换为文字序列
- 输入形式:原始波形、Mel 频谱、MFCC等
- 输出形式:字符、子词或单词,取决于系统设计
现在你知道了 ASR 要处理什么、输出什么。但你可能好奇:ASR模型是怎么做到这一点的?
在下一篇文章中,我们将看看早期的传统 ASR 系统是如何用“模块化工程”解决语音识别问题的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号