
springboot中使用solr8
一、查看版本
由于是先有的springboot项目,再添加的solr,
所以要先去springboot的pom.xml中的 spring-boot-starter-parent 的 spring-boot-dependencies
中查看solr默认依赖版本,我这里是8.5.2
<solr.version>8.5.2</solr.version>
然后去solr官网下载相对应的版本或者差不多的版本
官网https://solr.apache.org/
找到最新的8.8.1版本的二进制版本,下载zip
下载地址https://www.apache.org/dyn/closer.lua/lucene/solr/8.8.1/solr-8.8.1.zip
二、使用solr新建core
解压zip,进入D:\solr-8.8.1\server\solr
新建一个文件夹,文件夹名字是将要创建的core的名字
这里新建answer_core
去D:\solr-8.8.1\example\example-DIH\solr\solr路径复制下面的conf文件夹和core.properties文件
到刚创建的answer_core文件夹下面
再打开cmd,进入D:\solr-8.8.1\bin目录,输入solr start启动solr
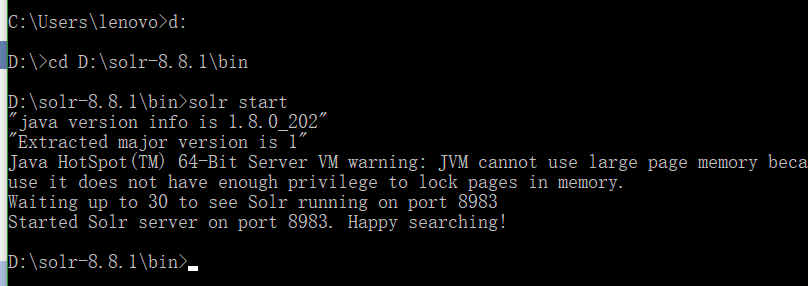
在浏览器输入http://localhost:8983/solr
这时该页面左边就会显示新建的answer_core

三、设置中文分词
首先要下载ik分词插件
去这个网站下https://search.maven.org/search?q=com.github.magese
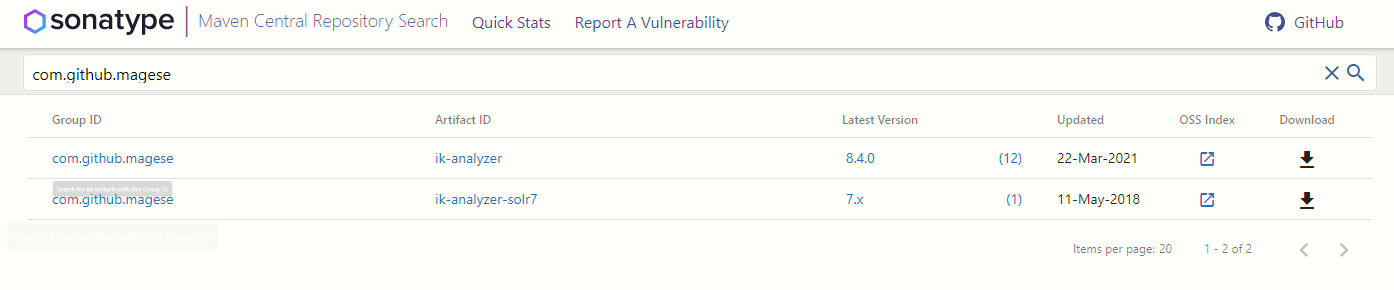
solr8就下载第一个8.4.0的就行,虽然这些版本都没对应,但问题不大
下载到的jar包放在D:\solr-8.8.1\server\solr-webapp\webapp\WEB-INF\lib下
然后进入D:\solr-8.8.1\server\solr\answer_core\conf
打开managed-schema进行配置
在文件倒数第二行插入这一段,这是配置ik分词方式
(注意这里我用的是记事本打开的,如果用写字板打开的话再进浏览器solr管理页面会显示utf格式问题)
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
保存好后去cmd输入solr restart -p 8983 重启solr
回到浏览器solr管理页面,选择answer_core,左边选择Anaslysis,下拉框里找有没有text_ik这一栏,如果有,则说明ik安装成功
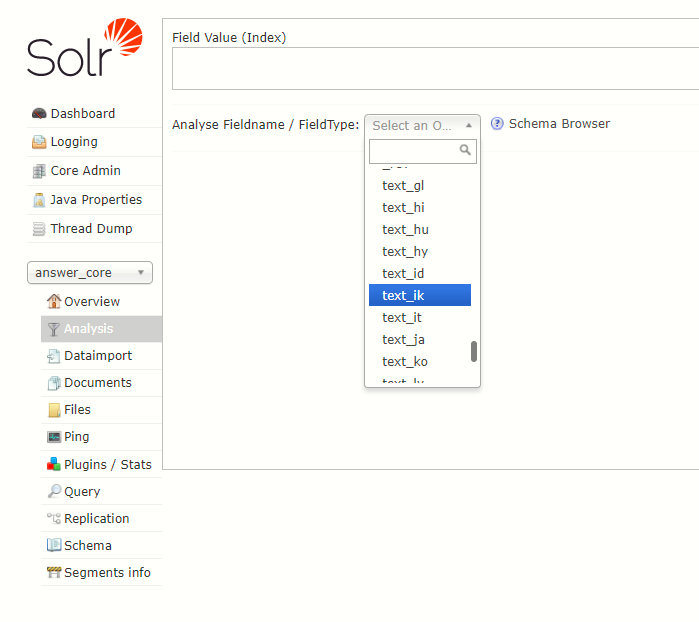
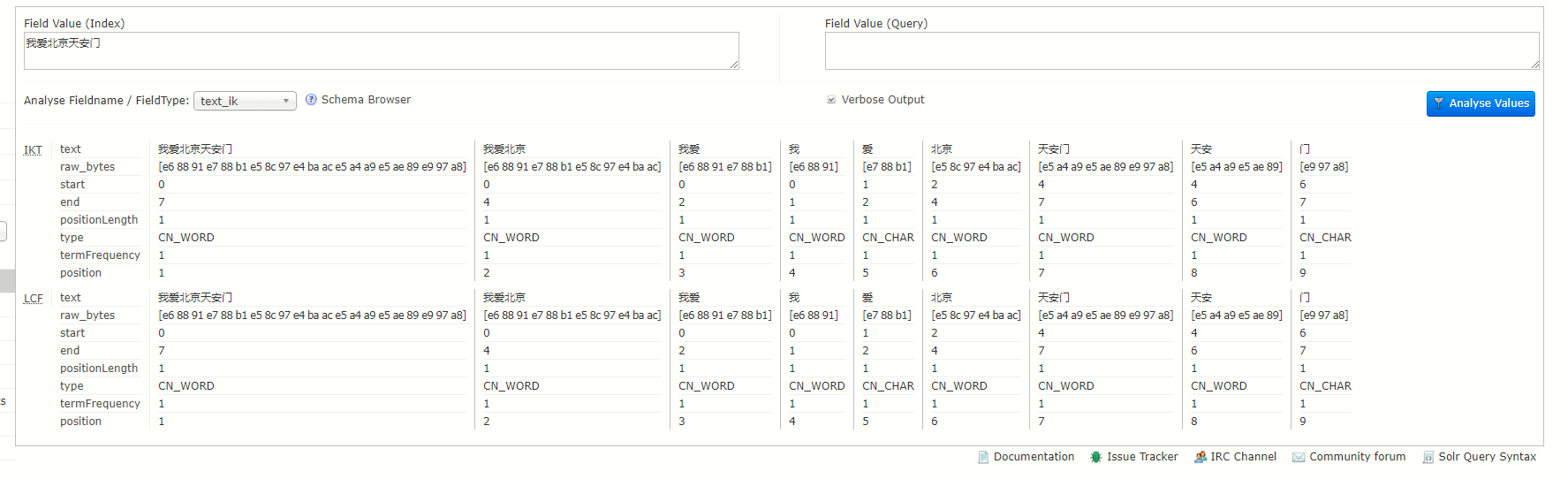
随便在左边输入框输入一个句子,点最右边的Analyse Values按钮,查看分词效果
四、设置搜索域
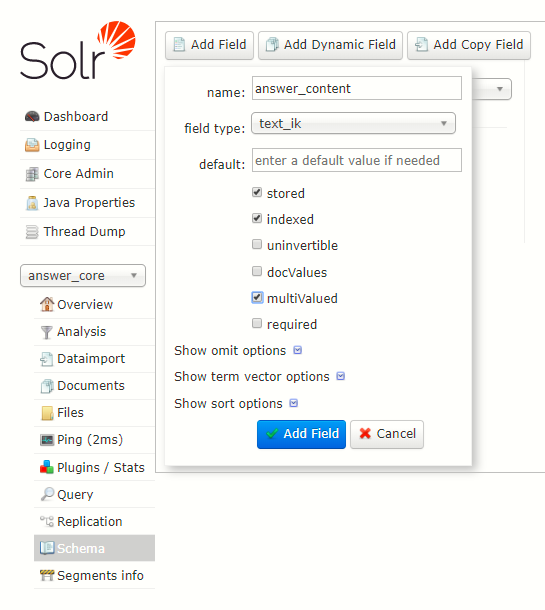
进入浏览器的solr管理页面,选好answer_core,点击Schema,点击Add Field
输入搜索域的名字,搜索域的类型,这里选text_ik,勾上这三个参数,然后点下面的按钮添加
五、使用代码测试
新建测试类和插入数据的测试函数
@Test public void addAnswerSolr(){ HttpSolrClient solrClient = new HttpSolrClient.Builder("http://localhost:8983/solr/answer_core").build(); SolrInputDocument document = new SolrInputDocument(); document.setField("id",1); document.setField("answer_content","今天吃了早饭吗,哈哈"); try { solrClient.add(document); solrClient.commit(); } catch (SolrServerException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }
执行,然后进入浏览器solr管理页面,选中answer_core,点击Query,这里的q的内容默认*:*是查询所有字段的所有内容,右边出现刚刚插入的数据则说明插入成功

编写删除的测试方法
@Test public void deleteAnswerSolr(){ HttpSolrClient solrClient = new HttpSolrClient.Builder("http://localhost:8983/solr/answer_core").build(); try { solrClient.deleteById(1+""); solrClient.commit(); } catch (SolrServerException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }
运行后查询
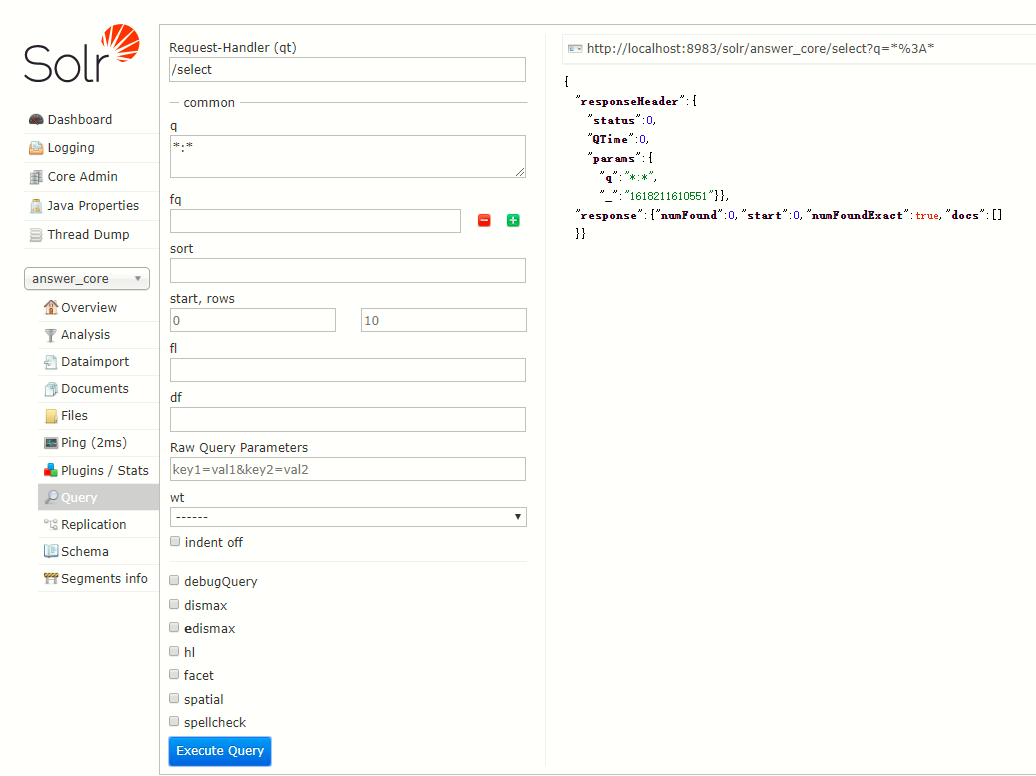
继续插入刚刚那条数据,用java测试方法查询数据
@Test public void queryAnswerAll(){ HttpSolrClient solrClient = new HttpSolrClient.Builder("http://localhost:8983/solr/answer_core").build(); List<Answer> answerList = new ArrayList<>();
//设置查询的句子 SolrQuery query = new SolrQuery("哈哈");
//设置分页 query.setRows(10); query.setStart(0);
//设置是否高亮 query.setHighlight(true);
//设置高亮前后缀 query.setHighlightSimplePre("<em>"); query.setHighlightSimplePost("</em>");
//设置高亮搜索域,可以有多个,就是多几句addHighlightField操作 query.addHighlightField("answer_content");
//设置默认搜索域,如果有多个,则需要在第四节设置搜索域里设置几个copy field,指向同一个新字段,然后设置默认搜索域为这个新字段 query.set("df", "answer_content"); try {
//执行查询,可以将response输出出来,内容和网页上查询效果一样 QueryResponse response = solrClient.query(query);
//找到highlight字段,看里面包含的字段,将其插入到自己需要的对象的相应字段中 for (Map.Entry<String, Map<String, List<String>>> entry : response.getHighlighting().entrySet()) { Answer answer = new Answer(); answer.setId(Integer.parseInt(entry.getKey())); if (entry.getValue().containsKey("answer_content")) { List<String> contentList = entry.getValue().get("answer_content"); if (contentList.size() > 0) { answer.setContent(contentList.get(0)); } } answerList.add(answer); } } catch (SolrServerException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }
完成!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号