

MYSQL基本操作(上)
很久之前,就想做个Mysql的小结,毕竟数据库知识是软件研发的基本技能,这里话不多说,开始总结一波。
数据库基本概念
数据库为高效的存储和处理数据的介质(主要分为磁盘和内存两种),一般关系型数据库存储在硬盘中,比如Mysql, Access,Oracle等,非关系型数据库则存储在内存中,比如NoSQL等,其中各自的优缺点很明显了。关系型数据库是一种建立在关系模型(数学模型)上的数据库,以二维表(行和列--结构角度 or 记录和字段--数据角度)的形式进行数据存储,常见的关键字的含义为:
- DB:Database,数据库;
- DBMS:Database Management System,数据库管理系统;
- DBS:Database System = DBMS + DB,数据库系统;
- DBA:Database Administrator,数据库管理员。
- SQL:Structured Query Language,结构化查询语言。
- DDL:数据定义语言,用来维护存储数据的结构(数据库、表),代表指令为
create、drop和alter等。 - DML:数据操作语言,用来对数据进行操作(表中的内容)代表指令为
insert、delete和update等。 - DQL:数据查询语言,代表指令为
select。 - DCL:数据控制语言,主要是负责(用户)权限管理,代表指令为
grant和revoke等。
这里为了方便弄清整个数据库的各个命令及意义,将按照DDL----DML-----DQL的顺序详细讲解Mysql由建库到跑路的详细历程。
Mysql 之 基础上
库操作
- 连接: Mysql -h 127.0.0.1 -P 3306 -uroot -p111111 注意其中的大小写,其中各个含义相比很清晰了
- 建库: create database + 数据库名称 + [库选项] 库选项主要包括两个:字符集和校对集,例如: create database funsql charset utf8 collate utf8_general_ci
- 删库: drop database + 数据库名 建议先备份再删除,除非你要跑路了
- 改库: alter database + 数据库名 + [库选择]
- 查库: show database [like "_fun%"] 这里可以使用模糊查询来实现查询数据库(可选),只能说很灵活。
- 其它: show create database + 数据库名 可查看数据库的创建语句
表操作
- 建表: create table [if not exists] + 表名( 字段名称 数据类型, ···,字段名称 数据类型)[表选项] 其中表选项主要包括三个:字符集、校对集以及存储引擎,例如:create table if not exists manager( name char(8), age int, grade varchar(10) )charset utf8 collate utf8_general_ci engine InnoDB
- 删表: drop table + 表名1,表名2 可实现多重删除
- 改表列: alter table + 表名 + 操作符 + [column] + 字段名 + 数据类型 + [列属性][位置] 这里操作符主要包括:add, drop, modify, change, 列属性主要包括:
null、not null、default、primary key、unique key、auto_increment和comment等,位置主要包括:first, after - 改表外: rename table 旧表名 to 新表名; alter table + 表名 + 表选项[=] + 值 分别为更改表的名字以及表选项
- 查表: show tables [like "_fun%"] 同查库一样,如需要查看表中的字段信息:
desc/describe/show columns from + 表名;
数据操作
- 增数: insert into + 表名(字段列表) + values(值列表)[,(值列表)] 插数据亦可用select实现叠加赋值,例如insert into fun select * from fun1(字段数及类型一致), 假如有主键冲突,可在语句后面添加 on duplicate key update 主键名 = '需要的数值';
- 删数: delete from + 表名 + [where 条件];
- 改数: update + 表名 + set + 字段 = 值 + [where 条件];
- 查数: select * from + 表名 + [where 条件];
- 清空: truncate + 表名;
数据进阶操作之查询:
select + [distint/all] + 字段列表[字段别名]/* + from + 数据源 + [where 条件] + [group by 子句 [asc/desc] ] + [having 条件] + [order by 子句 [asc/desc] ] + [limit 子句];
- 这里的distinct 是实现去重,它只能跟随字段哦;
- 字段列表不仅仅可以是检索列,亦可以是有效表达式,比如聚合函数count(distinct *)、max(列名)、min(列名)、avg(列名)、sum(列名)等
- 字段别名可用AS关键字来实现,常见的用法为:字段名 + [as] + 别名,当然数据源也可以使用别名哦,理论上讲,只要是集合便能用别名另称;
- 数据来源可以是单表、多表、视图、子查询等;
- where 条件实现行过滤,其中常用的比较运算符为
>、<、<>、=、like、between and、in和not in以及逻辑运算符&&、||、和!,where是从磁盘读取数据,而磁盘中数据的名字只能是字段名,不能是别名哦; - having 条件实现组过滤,其一定是在行过滤之后哦,功能及用法类似大于where,数据进入内存之后,会需要分组操作,分组结果就需要having来处理,可用别名哦,因为别名是数据(字段)进入到内存后才产生的;
- group by 子句实现组排序,这里切记分组的目的是为了(按分组字段)统计数据,并不是为了单纯的进行分组而分组哦,子句不能是聚合函数哦;
- order by子句实现行排序,这个就很简单了;
- limit 主要目的限制结果的数量,例如:limit 2,2则只显示结果的3,4两行,可以用它实现分页效果哦。
联结查询,所需数据时常会在多个表中存在,进行多表查询时,联结便可大派用场了
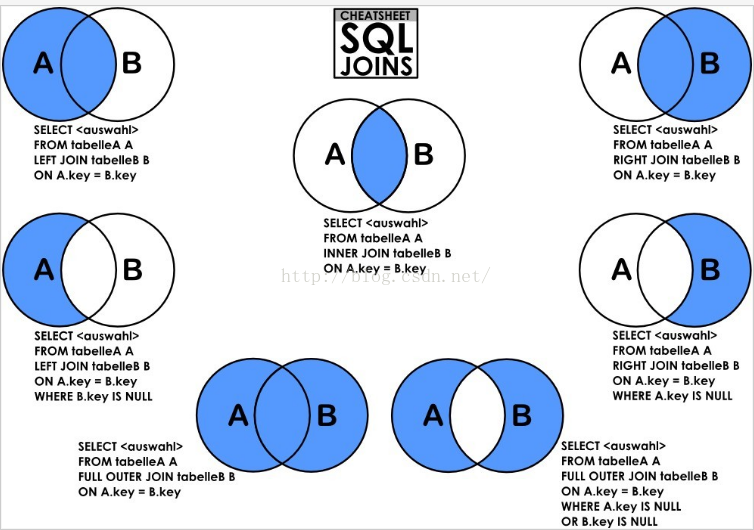
- 内联结:左表 + [inner] + join + 右表 + on + 左表.字段 = 右表.字段; 这里on实现的效果与where类似,但on效率更高。从左表中取出每一条记录,和右表中的所有记录进行匹配,并且仅当某个条件在左表和右表中的值相同时,结果才会保留,否则不保留。
- 外联结:左表 + left\right + join + 右表 + on + 左表.字段 = 右表.字段; 这里以某张表为主表,取出里面的所有记录,然后让主表中的每条记录都与另外一张表进行连接,不管能否匹配成功,其最终结果都会保留,匹配成功,则正确保留;匹配失败,则将另外一张表的字段都置为
NULL. - 自然连接:左表 + nature + [left/right] + join + 右表; 这里实现的效果对应着相应的内外联结,只是去除了重复行。
- 为方便理解,copy一张图帮助理解:
数据进阶操作之外键:
外键:foreign key,外面的键,即不在自己表中的键。如果一张表中有一个非主键的字段指向另外一张表的主键,那么将该字段称之为外键。每张表中,可以有多个外键。外键默认的作用有两个,分别对子表和父表进行约束,当然也可以进行自定义设置模式,常见的模式包括:district(严格模式,默认),cascade(级联模式),set null(置空)。
增: foreign key(外键字段) + references + 外部表名(主键字段) [on delete + 模式 + on update + 模式];
删: alter table my_foreign1 drop foreign key my_foreign1_ibfk_1;
改增: alter table + 表名 + add[constraint + 外键名字] + foreign key(外键字段) + references + 外部表名(主键字段) [on delete + 模式 + on update + 模式];
数据进阶操作之联合查询及子查询:
联合查询关键字:select 语句1 + union + [union选项] + select 语句2 + ...; 其中union选项包括:distinct,all, 检索项数量必须一致,意义主要在于排序,需要时加上括号。
子查询:等价于小型视图:select * from tableName1 where (age, height) =[any|some|all] (select max(age), max(height) from tableName2);
视图操作
视图:是一种有结构(有行有列),但没有结果(结构中不真实存放数据)的虚拟表,虚拟表的结构来源不是自己定义的,而是从对应的基表(视图的数据来源)中产生的。
表操作:
- 新建:create view + 视图名 + as + select语句;
- 查询:把视图假想成一个表,其查询操作同表一模一样(desc 视图名/show tables 视图名/ show create tables 视图名)
- 修改:alter view + 视图名 + as + 新的select语句; 视图本身并不支持修改,修改视图,就是修改视图的来源(select)语句。
- 删除:drop view + 视图名;
- 视图算法: create + [algorithm = temptable/merge/undefined] + view + 视图名 + as + select语句;,其中三种算法,主要表现在视图语句和外部查询语句的执行顺序,undefined让系统自己判断,temptable让系统先执行视图的
select语句,后执行外部查询语句,merge让系统先将视图对应的select语句与外部查询视图的select语句进行合并,然后再执行。通常如果视图的select语句中包含一个查询子句(五子句,包括where、group by、order by、having和limit),而且很有可能查询子句的顺序比外部的查询语句的顺序要靠后(五子句的顺序),那么一定要使用temptable算法,其他情况可以不用指定,默认即可。
数据操作: 虽说视图跟表有着千丝万缕的相似,但是在进行数据操作时还是多了许多限制
- 多表视图不能进行新增数据,显然,不然无法维护真是各表中的数据的完整性
- 可以向单表视图新增数据,但视图中包含的字段必须有基表中所有不能为空的字段,这个显然也是为了保证数据的完整性
- 多表视图不能删除数据
- 理论上,无论多表视图还是单表视图,都可以进行数据的更新
视图最重要的功能就是查询,其他如增、删、改的操作一般不会使用,也不建议通过视图来操作基表的数据。
数据库备份与还原
终于到本节的最后一部分了,如果真想删库跑路的话,可以忽略,数据备份与还原的方式有很多种,具体可以分为:数据表备份、单表数据备份、SQL备份和增量备份。
- 数据表备份: 不需要通过 SQL 来备份,我们可以直接进入到数据库文件夹复制对应的表结构以及数据;在需要还原数据的时候,直接将备份(复制)的内容放回去即可。不同的数据引擎会有不同的区别,比如数据存储方法:
- Myisam:表、数据和索引全部单独分开存储,直接复制 Myisam 存储引擎产生的
.frm、.MYD和.MYI三个存储文件到新的数据库即可; - InnoDB:只有表结构,数据全部存储到
ibd文件中,可以将通过 InnoDB 存储引擎产生的.frm和.idb文件复制到另一个数据库;
- Myisam:表、数据和索引全部单独分开存储,直接复制 Myisam 存储引擎产生的
- 单表数据备份:select */字段列表 + into outfile + '文件存储路径' + fields + 字段处理 + lines + 行处理 + from 数据源; 每次只能备份一张表,而且只能备份数据,不能备份表结构。使用备份:load data infile + '文件存储路径' + into table + 表名 + [字段列表] + fields + 字段处理 + lines + 行处理;
- SQL 备份:备份的是 SQL 语句。在进行 SQL 备份的时候,系统会对表结构以及数据进行处理,变成相应的 SQL 语句,然后执行备份。在还原的时候,只要执行备份的 SQL 语句即可,此种备份方式主要是针对表结构。这里需要客户端支持,暂时忽略。
- 增量备份: 不是针对数据或者 SQL 进行备份,而是针对 MySQL 服务器的日志进行备份,其日志内容包括了我们对数据库的各种操作的历史记录,如增删改查等。
好了,暂时小结到这里,有时间再进行基本操作(下)~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号