2020年广东广州深圳招聘职业python大数据分析
2020年广东广州深圳招聘职业python大数据分析
一、数据读取
来源:该数据是从和鲸社区数据集合(数据集 - Heywhale.com)中下载,其中包含广东广州深圳在2020年11月-2020年12月30日的招聘信息
数据集:数据集格式不统一,同一列可能出现多种格式的表达方式,并存在空值,因此我们在对每一个子目标进行分析前,都应该对相应的列(数据项)进行数据清洗。
1 # encoding:utf-8 2 #2020年广州深圳广东招聘信息分析 3 import pandas as pd 4 import numpy as np 5 from pandas import DataFrame 6 data = pd.read_csv( 7 r"C:\Users\22392\PycharmProjects\数据分析\数据\zp_info.csv",encoding='utf-8', 8 engine='python') 9 #输出数据信息 10 print(data.info())
结果
<class 'pandas.core.frame.DataFrame'> RangeIndex: 28571 entries, 0 to 28570 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 position 28571 non-null object 1 region 28571 non-null object 2 experience 27983 non-null object 3 education 28559 non-null object 4 number 25781 non-null object 5 age 28570 non-null object 6 new_time 28570 non-null object 7 wage 28571 non-null object 8 company 28571 non-null object 9 trade 28570 non-null object 10 nature 28534 non-null object 11 scale 28568 non-null object dtypes: object(12) memory usage: 2.6+ MB
打印列名以及相应的缺失值个数
1 for columname in data.columns: 2 if data[columname].count() != len(data): 3 loc = data[columname][data[columname].isnull().values==True].index.tolist() 4 print('列名:"{}", 有{}个缺失值'.format(columname,len(loc)))
结果
列名:"experience", 有588个缺失值 列名:"education", 有12个缺失值 列名:"number", 有2790个缺失值 列名:"age", 有1个缺失值 列名:"new_time", 有1个缺失值 列名:"trade", 有1个缺失值 列名:"nature", 有37个缺失值 列名:"scale", 有3个缺失值
填充缺失值为“unknow”
data1=data.fillna("unknow") #输出填充后的空值信息 print(data1.isnull().any()) #打印数据 print(data1)
结果:
position False region False experience False education False number False age False new_time False wage False company False trade False nature False scale False dtype: bool position region experience ... trade nature scale 0 库房打包工人 深圳市/龙岗区 1年以下 ... 互联网/电子商务 民营 20人以下 1 生产工 广州市/白云区 无经验 ... 家具/家电/工艺品/玩具 民营 20人以下 2 收件数据专岗 深圳市/罗湖区 无经验 ... 金融(银行/保险) 股份制企业 100-499人 3 办公室客服文员 广州市/荔湾区 不限 ... 房地产开发 民营 100-499人 4 客服实习生 广州市/荔湾区 不限 ... 建筑与工程 民营 100-499人 ... ... ... ... ... ... ... ... 28566 算法工程师 广东-东莞 1年以上经验 ... 机械/设备/技工 民营企业 500-1000人 28567 行政主管 广东-东莞 不限经验 ... 建筑/房地产 民营企业 50-200人 28568 人事行政主管 广东-东莞 5年以上经验 ... 机械/设备/技工 民营企业 50-200人 28569 仓储主管 广东-东莞 1年以上经验 ... 机械/设备/技工 民营企业 1000人以上 28570 审计专员 广东-东莞 1年以上经验 ... 机械/设备/技工 民营企业 500-1000人 [28571 rows x 12 columns] Process finished with exit code 0
二、数据分析
2.1 招聘职业的公司需求
分析:进行粗略分析,仅分析各个公司对职业的需求,即1V1,而不分析对职位人数的需求。job0=(data1.loc[:,["trade"]]).value_counts() print(job0.head(20))
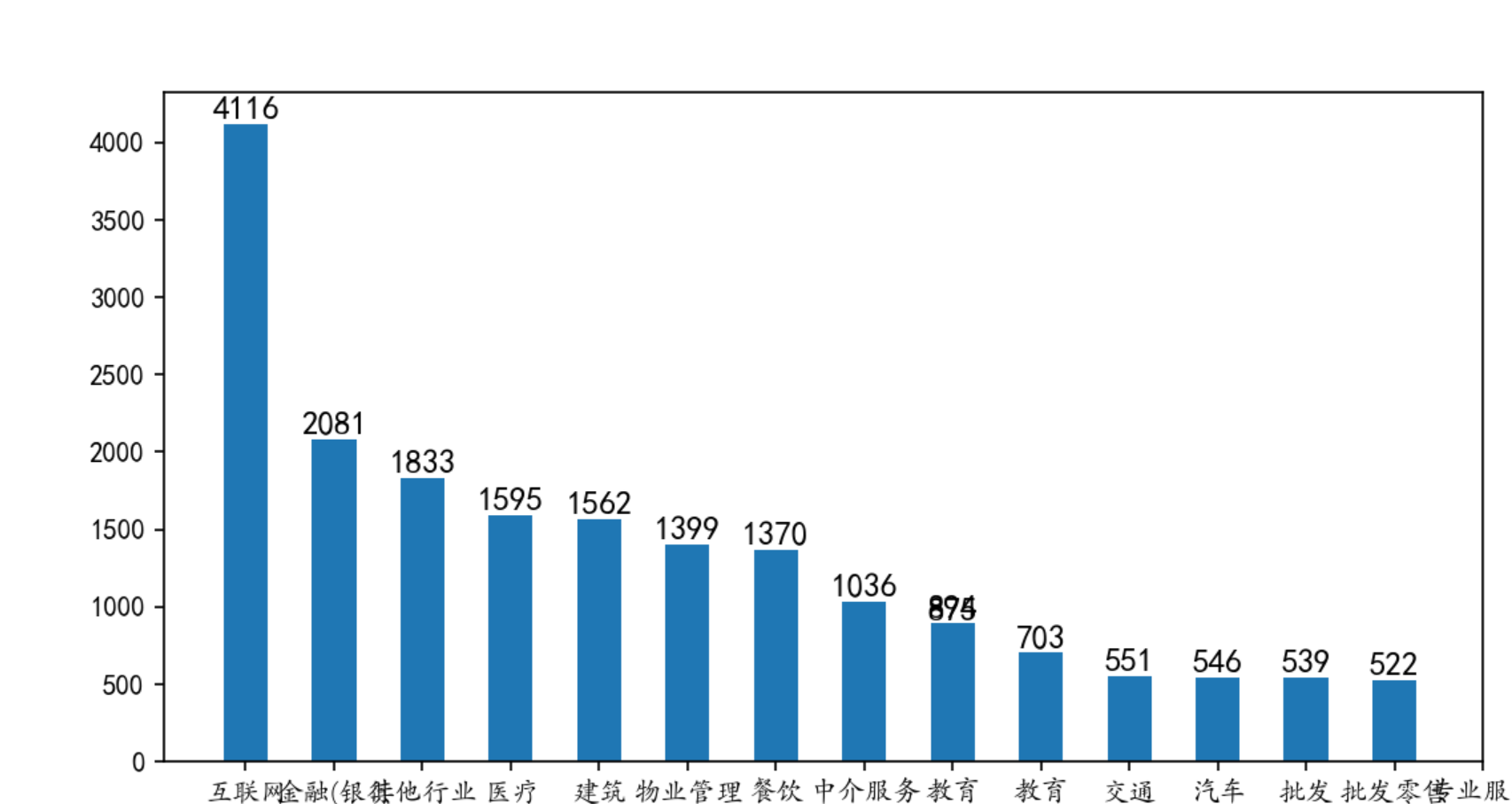
运行结果:前20名
C:\Users\22392\PycharmProjects\数据分析\venv\Scripts\python.exe C:/Users/22392/PycharmProjects/数据分析/职位2.py trade 互联网/电子商务 4116 金融(银行/保险) 2081 其他行业 1833 医疗/美容/保健/卫生 1595 建筑/房地产/物业/装潢 1562 物业管理/商业中心 1399 餐饮/娱乐/休闲 1370 中介服务/家政服务 1036 教育/培训 894 教育/培训/学术/科研 875 交通/运输/物流 703 汽车/摩托车/零配件 551 批发/零售 546 批发零售 539 专业服务/财会/法律 522 电子/半导体/集成电路 516 机械/设备/技工 503 金融(投资/证券 449 服装/纺织/皮革 447 消费品(食/饮/烟酒) 438 dtype: int64
柱状图 前15名
import matplotlib.pyplot as plt from matplotlib import font_manager #解决中文报错 from pylab import * mpl.rcParams['font.sans-serif'] = ['SimHei'] mpl.rcParams['axes.unicode_minus'] = False #横坐标 lstx=[] #纵坐标 lsty=[] for x,y in zip(job0[0:15].index,job0[0:15]): lstx.append(((str(x)[2:-3]).split("/"))[0]) lsty.append(y) plt.figure(figsize=(20,10),dpi = 150) my_font = font_manager.FontProperties(fname=r'C:\Windows\Fonts\STKAITI.TTF',size =10) plt.bar(lstx,lsty,width=0.5) plt.xticks(range(len(lstx)),lstx,fontproperties=my_font) for a,b in zip(lstx,lsty): #柱子上的数字显示 plt.text(a,b,'%.0f'%b,ha='center',va='bottom',fontsize=12) plt.show()
图形化结果
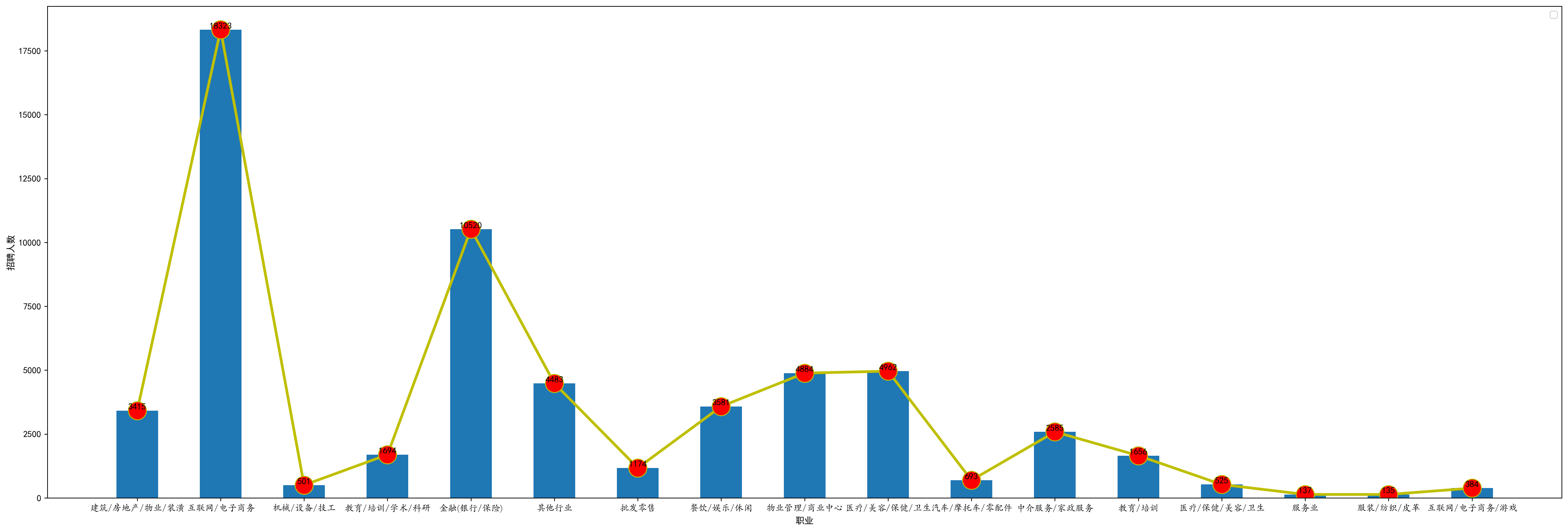
2.2 招聘职业人数需求
分析:1、由柱状图可得到:(1)互联网/电子商务 18323
(2)金融(银行/保险) 10520
(3)医疗/美容/保健 4962
(4)物业管理/商业中心 4884
(5)教育 3350 (1694+1656)
和2.1中数据进行对比,可知
互联网的人数需求为需求公司的4倍左右,即公司的招聘人数均值大约为4;
金融(银行/保险)的需求人数:公司=>5倍,即招聘公司虽相对互联网行业较少,但是每个公司的需求人均人数却大于互联网行业
教育 需求人数:公司<=2 可见 招聘公司多,但是招聘岗位需求太少。导致原本居于第三的公司职位的教育 在人数加权后反而沦为第五,被 医疗/美容/保健 、物业管理/商业中心 这两个行业反超。
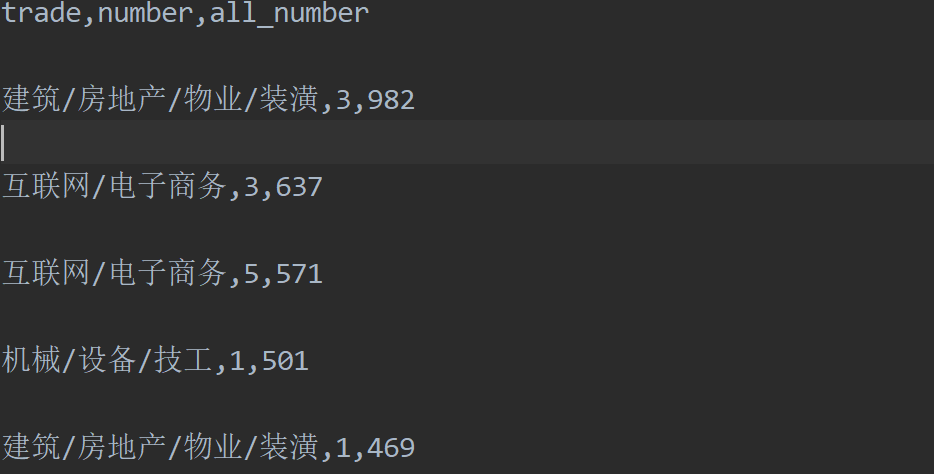
数据清洗,整理公司招聘职位类别 以及人数 写入job.csv文件中
job=(data1.loc[:,["trade","number"]]).value_counts() import csv f = open('job.csv','w',encoding='utf-8') csv_writer = csv.writer(f) csv_writer.writerow(["trade","number","all_number"]) for (x,y) in zip((job.index)[:50],job[:50]): lst=[] lst.append(x[0]) #对需求人数x[1]做规范化处理,unkonw=1,若干人=2 ,以及平均人数,以此来加权 lst2=[] lst2=re.split("人|招聘|数|-|:",str(x[1])) #去除空值 while '' in lst2: lst2.remove('') z = lst2[0] if lst2[0] == 'unknow': z = "1" elif lst2[0]=='若干': z = "2" elif len(lst2)==2: print(lst2) z = (int(lst2[0])+int(lst2[1]))//2 lst.append(z) lst.append(str(y)) csv_writer.writerow(lst) f.close()
job.csv中数据样例
jobdata = pd.read_csv(
r"job.csv",encoding='utf-8',
engine='python')
print(jobdata.info())
job.csv中的数据信息
<class 'pandas.core.frame.DataFrame'> RangeIndex: 50 entries, 0 to 49 Data columns (total 3 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 trade 50 non-null object 1 number 50 non-null int64 2 all_number 50 non-null int64 dtypes: int64(2), object(1) memory usage: 1.3+ KB
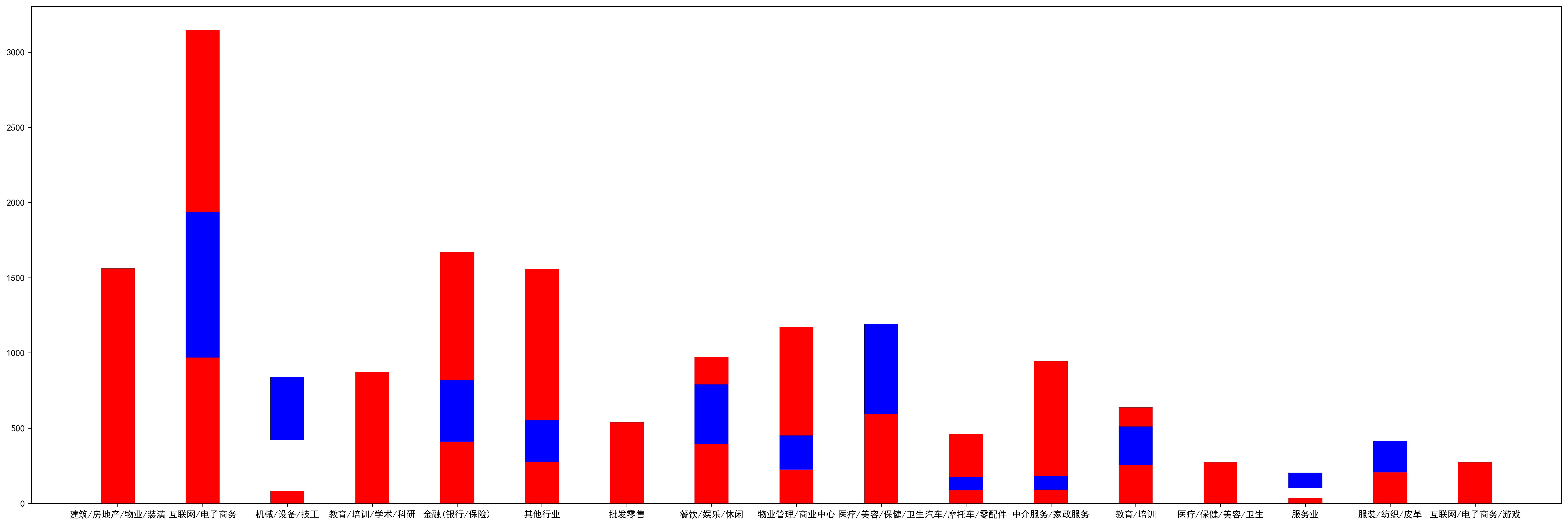
2.3 经验和就业的关系
分析:大多职业公司面试,有丰富的经验,也是面试的加分项之一。
其中unknow为为空的数据,将`unkonw`以及 `无经验`都归于不限经验之中。
#经验和就业的关系 #各行业是否要求有经验(有经验/不限) #experience=> 职业 经验 工资 experi_data=(data1.loc[:,["trade","experience","wage"]]) #获取职业分类信息lstx(前文已求出) trade_data=lstx #横坐标 lstxx=[] #有经验 lsty1=[] #无经验 lsty2=[] for x in trade_data: lstxx.append(x) y=experi_data.loc[experi_data["trade"]==x]["experience"] z=y.value_counts() #m为经验 z为数量 num0=0 #无经验总数 num1=0#有经验总数 for m,n in zip(z.index,z): m1=(str(m).split("经验"))[0] if m1=="无": num0=num0+n elif m1=="unknow": num0=num0+n elif m1=="不限": num0=num0+n else: num1= num1+n lsty1.append(num0) lsty2.append(num1) print(lstxx,lsty1,lsty2)
图形化为叠柱图
import matplotlib.pyplot as plt from matplotlib import font_manager #解决中文报错 from pylab import * mpl.rcParams['font.sans-serif'] = ['SimHei'] mpl.rcParams['axes.unicode_minus'] = False #对lstx进行处理 plt.figure(figsize=(30,10),dpi = 250) plt.bar(lstxx,lsty1,width=0.4,label="不限",fc='r') plt.bar(lstxx,lsty2,bottom=lsty2,width=0.4,label="有经验",fc="b") plt.show()
红色:有经验 蓝色:不限经验
2.4 学历和工资的相关性
学历和工资的相关性微弱
将数据中的教育,最低工资,最高工资进行清洗,并存储在edu.csv文件中
import pandas as pd import re import numpy as np from pandas import DataFrame data = pd.read_csv( r"C:\Users\22392\PycharmProjects\数据分析\数据\zp_info.csv",encoding='utf-8',sep="," ,engine='python') #填充缺失值 data1=data.fillna("unknow") edu_df=data1.loc[:,["education","wage"]] #遍历修改值 学历 以及最低工资和最高工资,然后最好能够放到一个表里面 import csv f = open('edu.csv','w',encoding='utf-8') csv_writer = csv.writer(f) csv_writer.writerow(["education","min_wage","max_wage"]) x1="" x2="" x3="" edu_wage_lst=[] for x in edu_df.iterrows(): edu_lst=[] x1=(str(x[1]["education"]).split("学历"))[0] if len(x1)!=2: continue wage_min_max=re.split("-|元|/月|¥|以上",str(x[1]["wage"])) while '' in wage_min_max: wage_min_max.remove('') if len(wage_min_max)<2: if str(wage_min_max[0])[-1]=="K": x2=str(float(wage_min_max[0][0:-1])*1000)[0:-2] x3=x2 else: x2=str(wage_min_max[0]) x3=str(wage_min_max[0]) if x2=="面议": continue else: if str(wage_min_max[0])[-1]=="K": x2=str(float(wage_min_max[0][0:-1])*1000)[0:-2] else: x2=str(wage_min_max[0]) if str(wage_min_max[1])[-1]=="K": x3=str(float(wage_min_max[1][0:-1])*1000)[0:-2] else: x3=str(wage_min_max[1]) edu_lst.append(x1) edu_lst.append(x2) edu_lst.append(x3) edu_wage_lst.append(edu_lst) csv_writer.writerow(edu_lst) f.close()
使用datle进行相关性分析,由此可知,学历和工资之间的相关性不大
import dtale dtale.show(edu_data,ignore_duplicate=True)
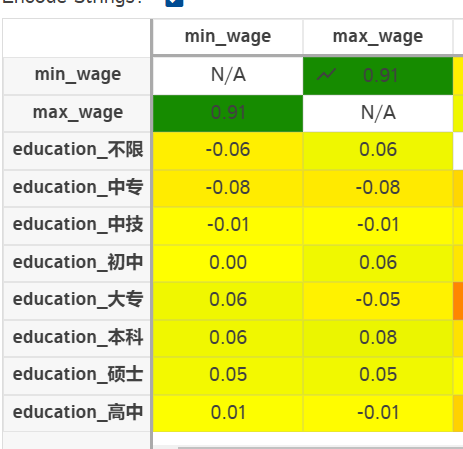
2.5 不同学历的最低工资和最高工资的分布关系
分析:说是的工资普斌较高 ,本科及大专几乎相同。
通过使用seaborn进行分析,找到学历相对的工资的分布情况
import seaborn as sns #最低工资和学历的关系 edu_data.boxplot(column="min_wage", by="education",figsize=(8,8)) #最高工资和学历的关系 edu_data.boxplot(column="max_wage", by="education",figsize=(8,8))
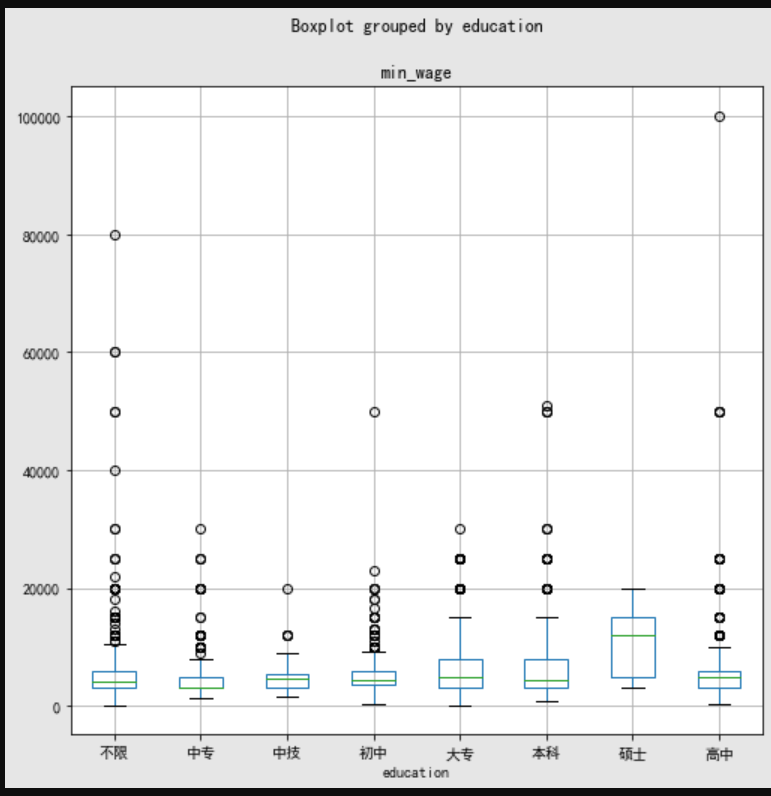
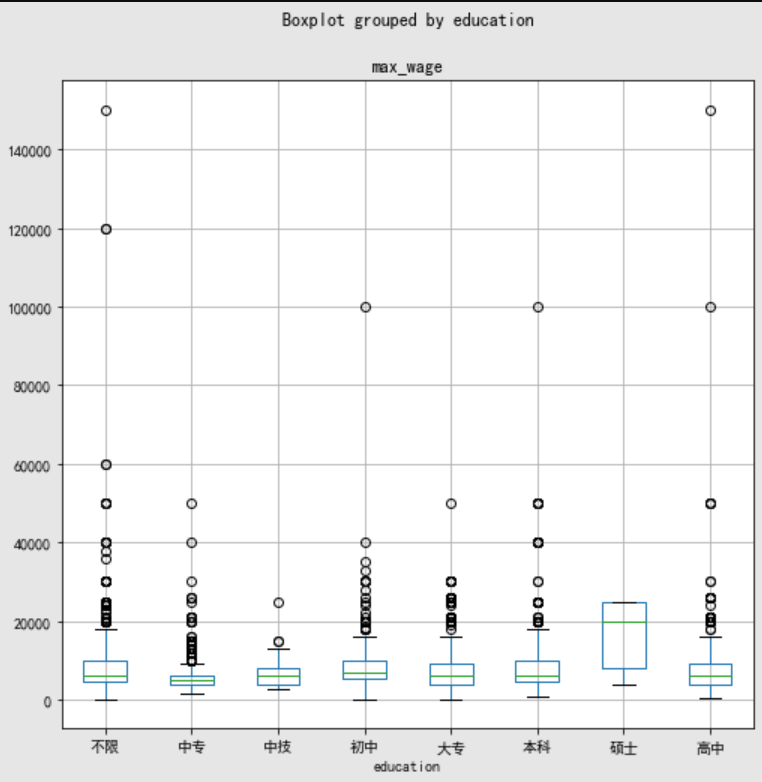

 浙公网安备 33010602011771号
浙公网安备 33010602011771号