
数据科学之路
先放一张技术路线图,然后每天更新一点东西,用于复习和巩固
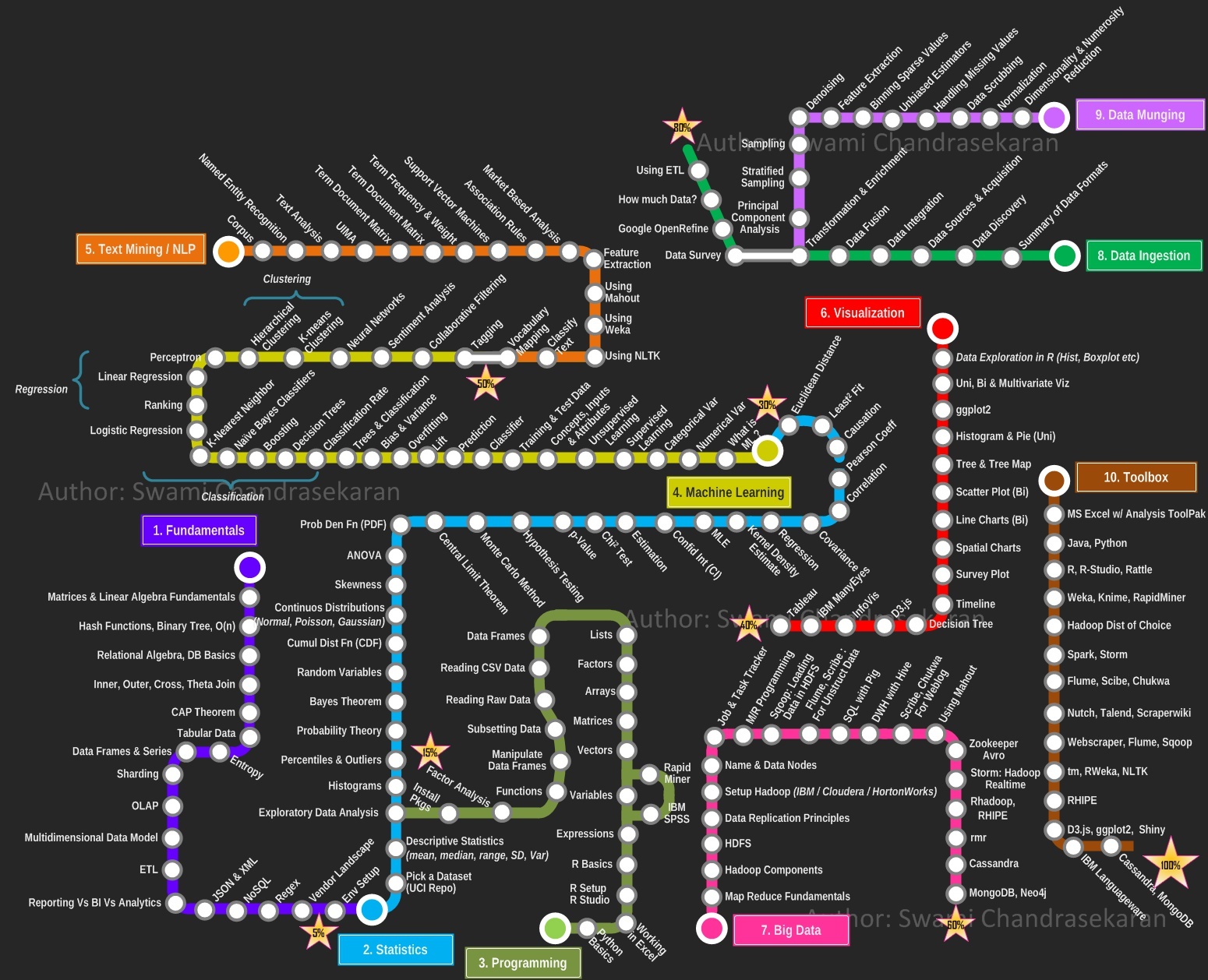
1.基础部分
A.矩阵和线性代数基础
矩阵是什么? 数学上,一个m×n的矩阵是一个由m行n列元素排列成的矩形阵列。
矩阵的加法,要求两个矩阵或者是多个矩阵,要求所有的矩阵的列和行都是一样的,例如都是3X2的矩阵,或者是5x8矩阵。矩阵的加法就是将对应位置的数值相加即可。
矩阵的乘法,就是使用数字和矩阵相乘,矩阵的乘法对矩阵没有要求。运算法则就是将乘数与矩阵中每一个数字相乘即可。
一个m行n列的矩阵与一个n行q列的矩阵相乘,最后得到的就是一个m行q列的矩阵。
矩阵的逆,对于一个m行n列的矩阵A,如果存在A-1,满足A*A-1=I(I是单位矩阵),则表示A-1是A的逆。
B.哈希函数和二叉树
hash函数是散列化元素的一种函数,种类很多,简单如i*31就是一个hash函数。
二叉树是一种数据结构,有哈夫曼树,红黑树等变种。
C.数据库基础:SQL语法,ACID,数据库的范式
D.数据库并表计算:交,并,外联等
E。CAP理论:分布式数据库在一致性(consistency),可用性(availability),分区容错性(partiton
tolerance)无法完全保证。这是因为,分区如果出错,为保证可用性,一个区会变动数据提供要求数据,另一个区无法保证一致性了。现在分布式数据库主要用在sns等领域,对于一致性要求较低。
F.Tabular Data(表列数据):不太懂,求大神指导。
G.数据框和序列:这是numpy包重要的数据结构,方便数据处理和清洗工作。
H.分库分表(Sharding):数据库内部,为了读写分离,优化。
横向分区:就是横着来分区了,举例来说明一下,假如有100W条数据,分成十份,前10W条数据放到第一个分区,第二个10W条数据放到第二个分区,依此类推。
纵向分区:就是竖来分区了,举例来说明,在设计用户表的时候,开始的时候没有考虑好,而把个人的所有信息都放到了一张表里面去,这样这个表里面就会有比较大的字段,如个人简介,而这些简介呢,也许不会有好多人去看,所以等到有人要看的时候,在去查找,分表的时候,可以把这样的大字段,分开来。
range 分区:这种模式允许将数据划分不同范围。例如可以将一个表通过年份划分成若干个分区。
list分区:这种模式允许系统通过预定义的列表的值来对数据进行分割。
hash分区:这中模式允许通过对表的一个或多个列的Hash Key进行计算,最后通过这个Hash码不同数值对应的数据区域进行分区。例如可以建立一个对表主键进行分区的表。
子分区是分区表中每个分区的再次分割,子分区既可以使用HASH希分区,也可以使用KEY分区。
I.OLAP(在线分析处理):就是BI软件的上一级。有Cognos等产品。
J.多维数据模型:因子分析,PCA(主成分分析),多元回归等
K.ETL(抽取,转换,加载):一般可以使用panda包来完成,也可以使用专业工具。
L.报告,BI,分析: PPT技能,tableau,fineBI,excel,spss数据分析等
M.Json&XML(数据交换格式):json,xml方便对象数据,在各种平台间相互交换
N.NoSQL(非关系型数据库):Redis,MongoDB等,面对web应用提供文件存储服务的数据库
O.Regex(正则表达式):这里面太多内容.
P.Vendor LandScape:大数据展示的一个工具(不了解)
Q.Env Setup:安卓的编译脚本(不懂)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号