
Hadoop概述
标签(空格分隔): hadoop
什么是Hadoop
- Hadoop common: hadoop公共组件
- Hadoop Distrilbuted File System(HDFS):分布式文件系统,提供高速访问存储
- Hadoop YARN: 作业调度框架和节点资源管理
- Hadoop MapReduce: 基于YARN系统的并行处理的框架
Hadoop是基于Apache开源的分布式存储及分布式计算平台
![image.png-451.5kB][1]
Hadoop能做什么
- 搭建大型数据仓库
- PB级别数据的存储、处理、分析、统计等业务
- 搜索引擎
- 日志分析
- 商业智能
- 数据挖掘
分布式文件系统 HDFS
- 源自Google的GFS论文,论文发表于2003年10月
- HDFS是GFS的克隆版
- HDFS特点:扩展必&容错性&海量数据存储
- 将文件切分成指定大小的数据块并以副本的形式存储在多个机器上
- 数据切分、多副本、容错等操作对用户是透明的
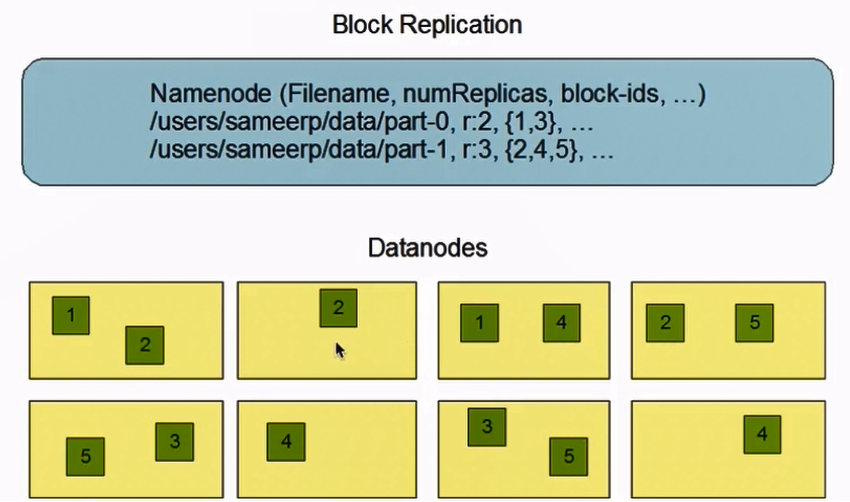
解释上图,/users/sameerp/data/part-0, r:2,{1,3},...,表明将part-0文件拆分为2个副本,id分别为1,3,在Datanodes中可以查找并合并成一个原始文件,part-1同理
资源调度系统YARN
- YARN: Yet Another Resource Negotiator
- 负责整个集群资源的管理和调度
- YARN: 扩展性&容错性&多框架资源统一调度
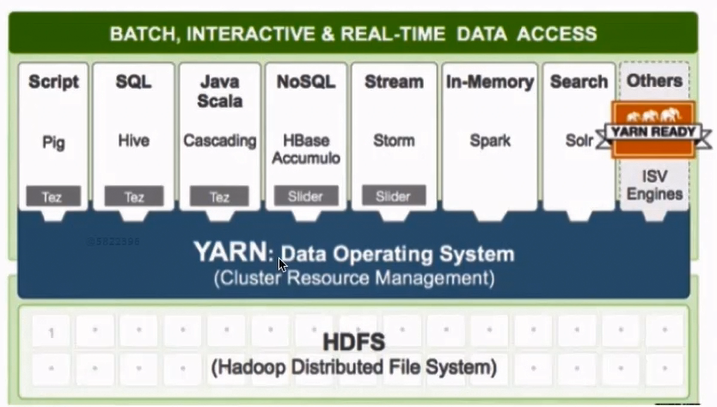
基于YARN可以运行多种的框架和系统
分布式计算框架MapReduce
- 源于Google的MapReduce论文,论文发表于2004年12月
- MapReduce是Google MapReduce的克隆版
- MapReduce特点:扩展性&容错性&海量数据离线处理

解释原型图片
'input' -> 'splitting' -> 'mapping' -> 'shuffling' -> 'Reducing' -> 'final result'
'输入' -> '分隔' -> '并行计算' -> '清洗' -> '汇总' -> '最终结果'
Hadoop优势之高扩展性
- 存储/计算资源不够时,可以横向的线性扩展机器
- 一个集群中可以包含数以千计的节点
Hadoop优势之其他
- 存储在廉价机器上,降低成本
- 成熟的生态圈
狭义Hadoop VS 广义Hadoop
- 狭义的Hadoop:是一个适合大数据分布式存储(HDFS)、分布式计算(MapReduce)和资源调度(YARN)的平台
- 广义的Hadoop:指的是Hadoop生态系统,Hadoop生态系统是一个很庞大的概念,hadoop是其中最重要最基础的一个部分;生态系统中的每一个子系统只解决某个特定的问题域(甚至可能很窄),不搞统一型的一个全能系统,而是小而精的多个小系统
Hadoop生态系统的特点
- 开源、社区活跃
- 囊括了大数据处理的方方面面
- 成熟的生态圈
Hadoop常用发行版及造型
- Apache Hadoop (存在jar包冲突)
- CDH: Cloudera Distributed Hadoop (无jar包冲突,web安装)
- HDP: Hortonworks Data Platform (安装升级不如CDH)
&emps;本次课程使用cdh5.7.0
[1]: http://static.zybuluo.com/anyu/vi61d248bymp2j4d6jdro53w/image.png

 浙公网安备 33010602011771号
浙公网安备 33010602011771号