抖音用户行为浏览与分析
一、选题的背景
本项目是大数据—基于抖音用户数据集的可视化分析。抖音作为当下非常热门的短视频软件,其背后的数据有极高的探索价值。
抖音用户浏览视频行为记录,包括什么人、看了谁的作品,以及相关信息(用户城市等),和行为描述信息(是否点赞等)
分析用户之间的互动数据,包括视频播放量、点赞数量、转发和评论关注度等。
浏览行为中涉及到不同的活动主体,如用户、作者、作品等,通过综合浏览数据,针对不同主体,制定不同的特征去描述主体的特点,
使用数据分析方法对浏览行为数据进行统计,得到不同主体的特征,并对不同主体的特征进行数据分析与挖掘。
二、大数据分析设计方案
1.本数据集的数据内容与数据特征分析
逻辑回归模型:
逻辑回归模型是针对线性可分问题的一种易于实现而且性能优异的分类模型。 它假设数据服从 伯努利分布,通过 极大化似然函数 的方法,运用 梯度下降法来求解参数,来达到将数据二分类的目的。
朴素贝叶斯模型:
一种简单但极为强大的预测建模算法。假设每个输入变量是独立的。这是一个强硬的假设,实际情况并不一定,但是这项技术对于绝大部分的复杂问题仍然非常有效朴素贝叶斯模型由两种类型的概率组成:
单棵决策树模型:
单层决策树(decision stump),也称决策树桩,它是一种简单的决策树,通过给定的阈值,进行分类。从树(数据结构)的观点来看,它由根节点(root)与叶子节点(leaves)直接相连。用作分类器(classifier)的 decision stump 的叶子节点也就意味着最终的分类结果。
随机森林:
随机森林是一种比较新的机器学习模型(非线性基于树的模型)集成学习方法。通过反复二分数据进行分类或回归,计算量大大降低,2001年 Breiman把分类树组合成随机森林,即在变量(列)的使用和数据(行)的使用上进行随机化,生成很多分类树,再汇总分类树结果。
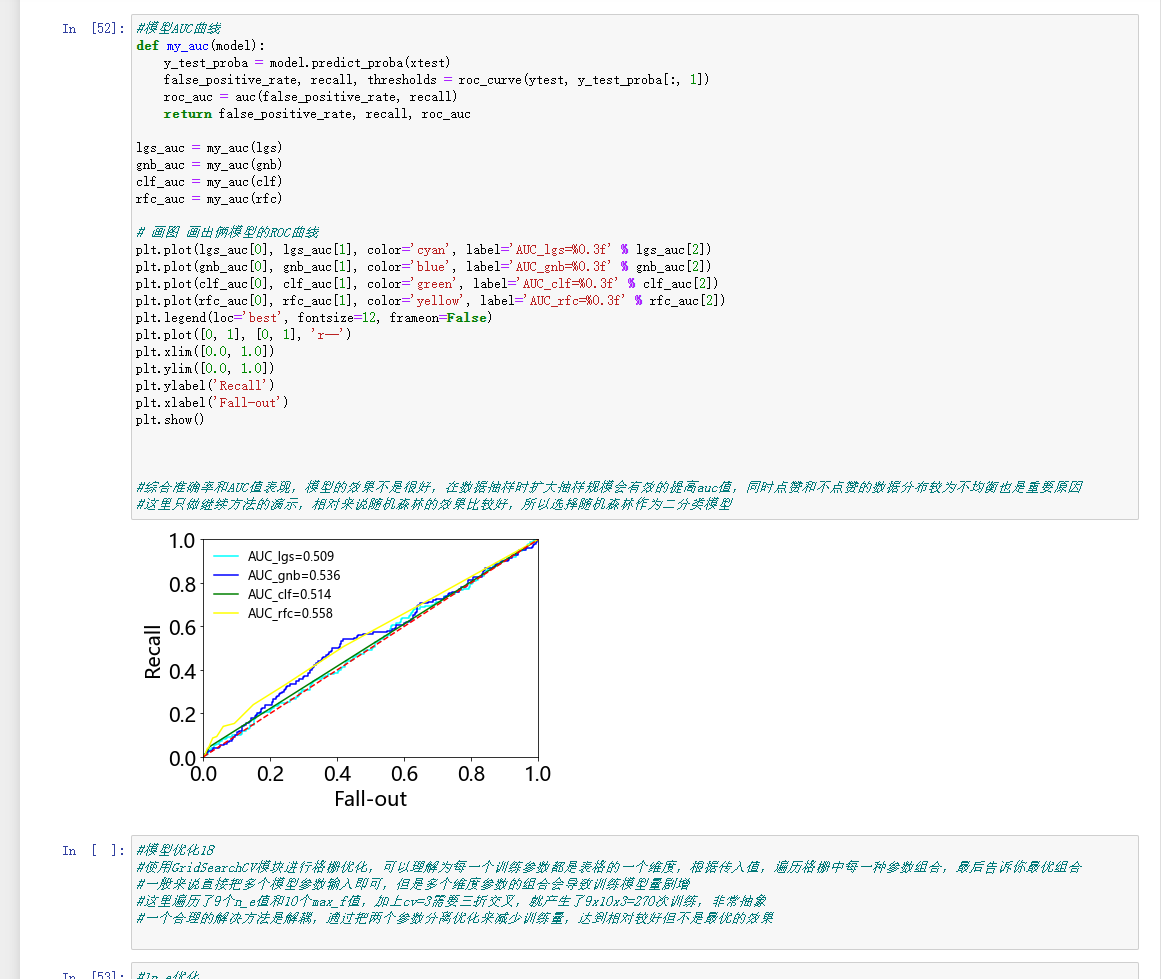
模型AUC曲线:
AUC(Area Under Curve)被定义为ROC曲线下与坐标轴围成的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值。
三、数据分析步骤(70 分)
1.数据源
请说明数据源采用的哪一个开放的数据集?如果是采集的,请说明采集来源
与方式。
主要是在和鲸社区上拿的,该数据有10+万条数据。
https://aistudio.baidu.com/aistudio/datasetdetail/63963/0
2.数据清洗
3.大数据分析过程及采用的算法
利用统计分析、数据挖掘和机器学习方法,对数据进行分析处理,获得分析结果,是数据分析处理流程的重要步骤。
●常规的统计方法
●通过使用机器学习的方法,处理采集到的数据。
逻辑回归、朴素贝叶斯、单棵决策树、随机森林

●使用的第三方库
如 sklearn 等,或其它
使用的库
4.数据可视化
数据可视化借助于图形化手段,将数据分析结果直观、清晰、有效地展现出
来。使得用户可以从不同的维度观察数据,对数据有更深入地理解。
说明每个可视化图形表示的意义
1、不同浏览量用户比、不同点赞量用户比、用户浏览量、
2、城市的占比分布
3、使用抖音频率观看时间的分布
4、#作品时长与播放量、完播率、点赞率的关系
5、#用户观看时段与播放量、完播率、点赞率的关系
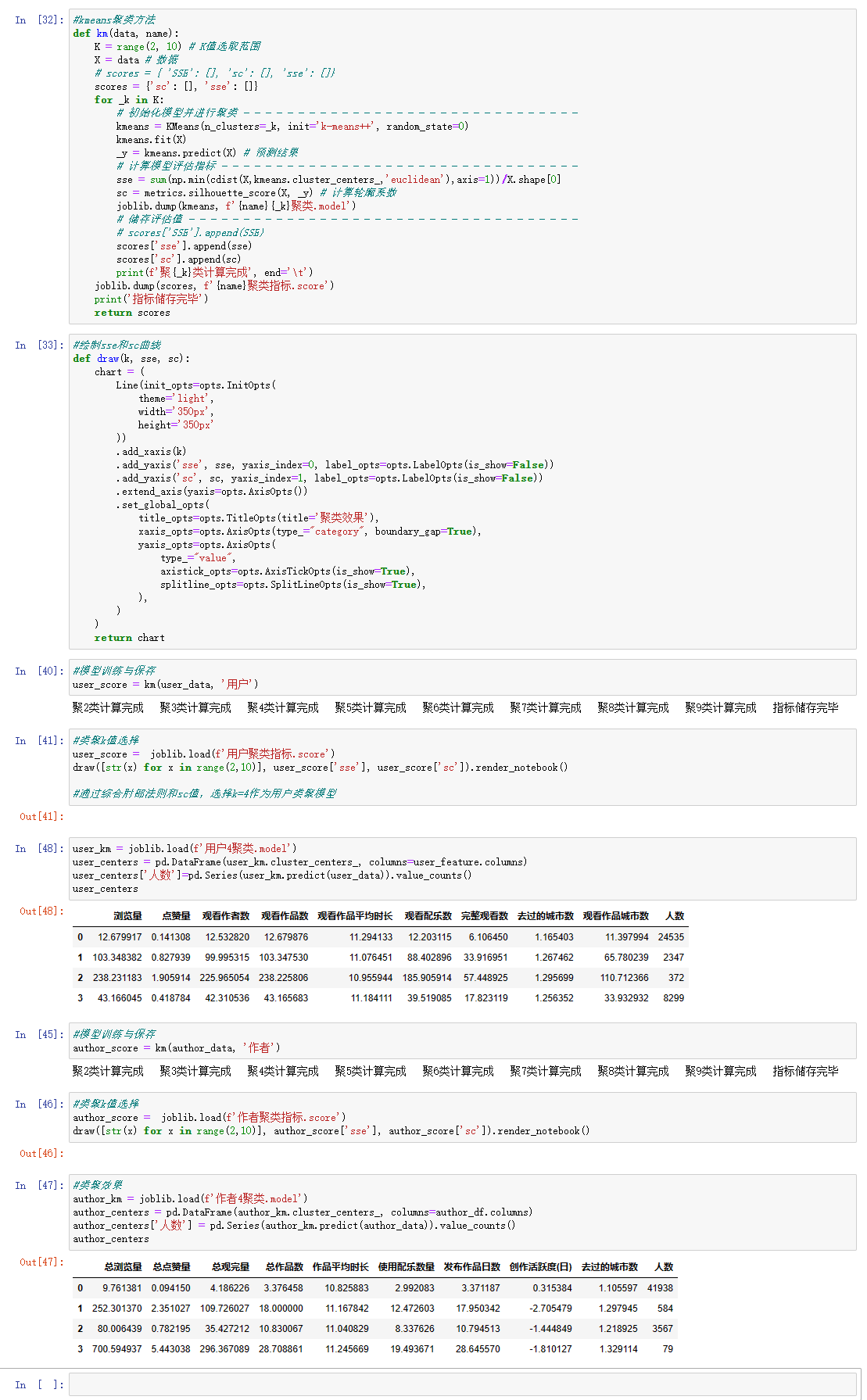
6、Kmeans聚类方法
7、模型AUC曲线
8、模型训练
- 附完整程序源代码(以及输出结果)
#导入需要的库
import pandas as pd
import numpy as np
from pyecharts.charts import *
from pyecharts import options as opts
from sklearn.cluster import KMeans
import joblib
from sklearn import metrics
from scipy.spatial.distance import cdist
from matplotlib import ticker
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, auc
from sklearn import ensemble
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.size'] = 20
# 中文乱码解决方法
plt.rcParams['font.family'] = ['Arial Unicode MS','Microsoft YaHei','SimHei','sans-serif']
plt.rcParams['axes.unicode_minus'] = False
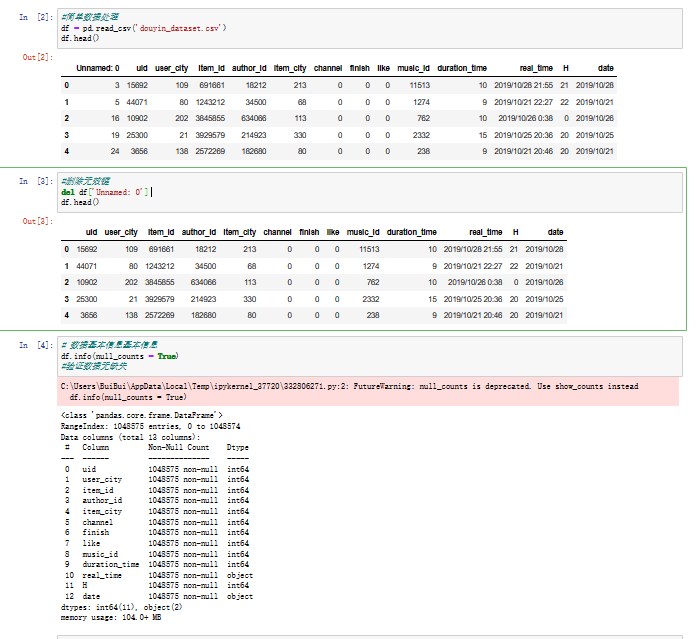
#简单数据处理
df = pd.read_csv('douyin_dataset.csv')
df.head()
#删除无效键
del df['Unnamed: 0']
df.head()
# 数据基本信息基本信息
df.info(null_counts = True)
#验证数据无缺失
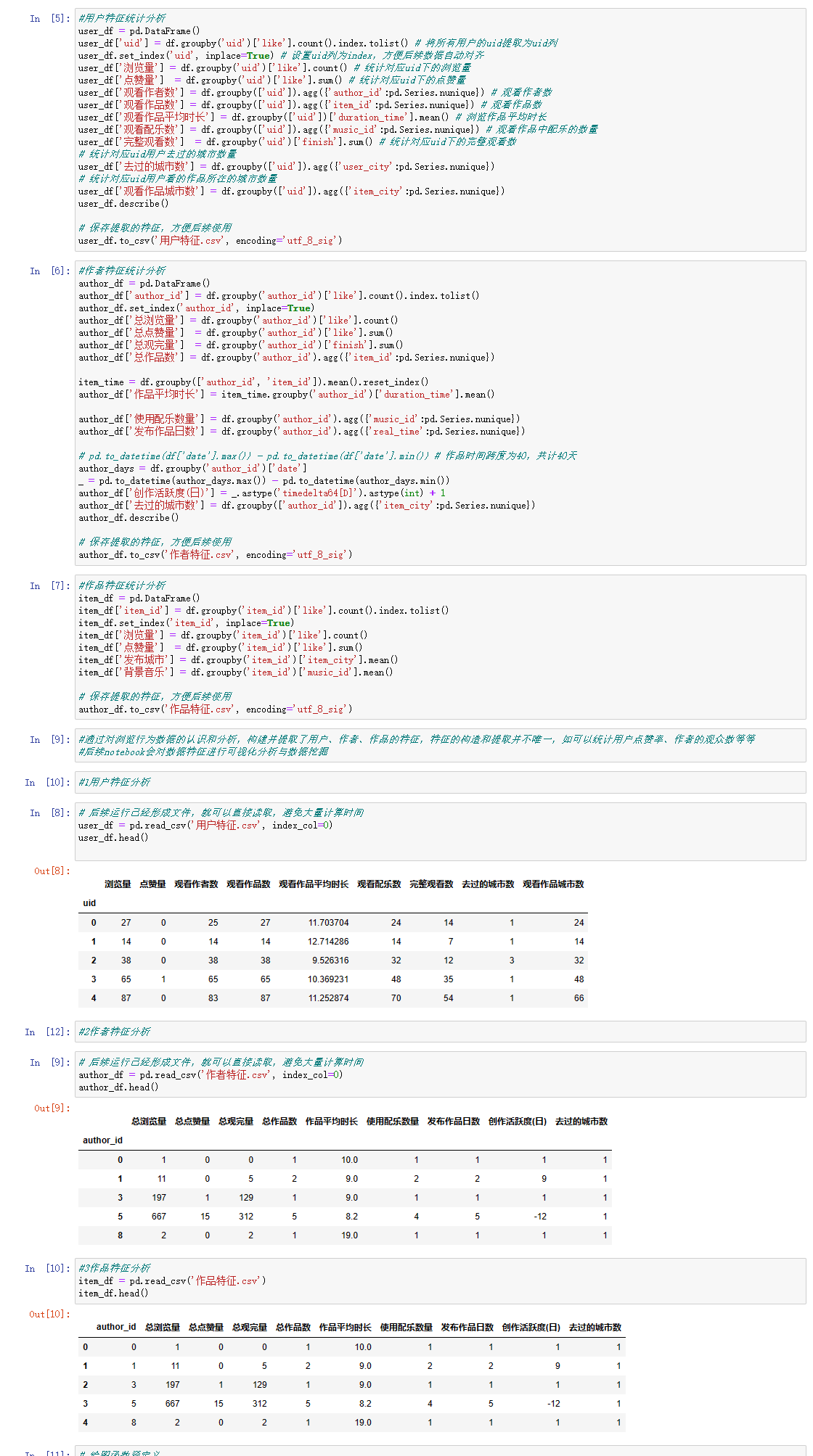
#用户特征统计分析
user_df = pd.DataFrame()
user_df['uid'] = df.groupby('uid')['like'].count().index.tolist() # 将所有用户的uid提取为uid列
user_df.set_index('uid', inplace=True) # 设置uid列为index,方便后续数据自动对齐
user_df['浏览量'] = df.groupby('uid')['like'].count() # 统计对应uid下的浏览量
user_df['点赞量'] = df.groupby('uid')['like'].sum() # 统计对应uid下的点赞量
user_df['观看作者数'] = df.groupby(['uid']).agg({'author_id':pd.Series.nunique}) # 观看作者数
user_df['观看作品数'] = df.groupby(['uid']).agg({'item_id':pd.Series.nunique}) # 观看作品数
user_df['观看作品平均时长'] = df.groupby(['uid'])['duration_time'].mean() # 浏览作品平均时长
user_df['观看配乐数'] = df.groupby(['uid']).agg({'music_id':pd.Series.nunique}) # 观看作品中配乐的数量
user_df['完整观看数'] = df.groupby('uid')['finish'].sum() # 统计对应uid下的完整观看数
# 统计对应uid用户去过的城市数量
user_df['去过的城市数'] = df.groupby(['uid']).agg({'user_city':pd.Series.nunique})
# 统计对应uid用户看的作品所在的城市数量
user_df['观看作品城市数'] = df.groupby(['uid']).agg({'item_city':pd.Series.nunique})
user_df.describe()
# 保存提取的特征,方便后续使用
user_df.to_csv('用户特征.csv', encoding='utf_8_sig')
#作者特征统计分析
author_df = pd.DataFrame()
author_df['author_id'] = df.groupby('author_id')['like'].count().index.tolist()
author_df.set_index('author_id', inplace=True)
author_df['总浏览量'] = df.groupby('author_id')['like'].count()
author_df['总点赞量'] = df.groupby('author_id')['like'].sum()
author_df['总观完量'] = df.groupby('author_id')['finish'].sum()
author_df['总作品数'] = df.groupby('author_id').agg({'item_id':pd.Series.nunique})
item_time = df.groupby(['author_id', 'item_id']).mean().reset_index()
author_df['作品平均时长'] = item_time.groupby('author_id')['duration_time'].mean()
author_df['使用配乐数量'] = df.groupby('author_id').agg({'music_id':pd.Series.nunique})
author_df['发布作品日数'] = df.groupby('author_id').agg({'real_time':pd.Series.nunique})
# pd.to_datetime(df['date'].max()) - pd.to_datetime(df['date'].min()) # 作品时间跨度为40,共计40天
author_days = df.groupby('author_id')['date']
_ = pd.to_datetime(author_days.max()) - pd.to_datetime(author_days.min())
author_df['创作活跃度(日)'] = _.astype('timedelta64[D]').astype(int) + 1
author_df['去过的城市数'] = df.groupby(['author_id']).agg({'item_city':pd.Series.nunique})
author_df.describe()
# 保存提取的特征,方便后续使用
author_df.to_csv('作者特征.csv', encoding='utf_8_sig')
#作品特征统计分析
item_df = pd.DataFrame()
item_df['item_id'] = df.groupby('item_id')['like'].count().index.tolist()
item_df.set_index('item_id', inplace=True)
item_df['浏览量'] = df.groupby('item_id')['like'].count()
item_df['点赞量'] = df.groupby('item_id')['like'].sum()
item_df['发布城市'] = df.groupby('item_id')['item_city'].mean()
item_df['背景音乐'] = df.groupby('item_id')['music_id'].mean()
# 保存提取的特征,方便后续使用
author_df.to_csv('作品特征.csv', encoding='utf_8_sig')
# 后续运行已经形成文件,就可以直接读取,避免大量计算时间
user_df = pd.read_csv('用户特征.csv', index_col=0)
user_df.head()
# 后续运行已经形成文件,就可以直接读取,避免大量计算时间
author_df = pd.read_csv('作者特征.csv', index_col=0)
author_df.head()
#3作品特征分析
item_df = pd.read_csv('作品特征.csv')
item_df.head()
# 绘图函数预定义
def line_chart(t, data):
chart = (
Line(init_opts = opts.InitOpts(theme='light',width='600px', height='400px'))
.add_xaxis([i[0] for i in data])
.add_yaxis(
'',
[i[1] for i in data],
is_symbol_show=False,
areastyle_opts=opts.AreaStyleOpts(opacity=1, color="cyan"))
.set_global_opts(
title_opts=opts.TitleOpts(title=t),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=True),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),),))
return chart
def pie_chart(t, data_pair):
# 新建一个饼图
chart = (
Pie(init_opts=opts.InitOpts(theme='light',width='600px', height='400px'))
.add('', data_pair ,radius=["30%", "45%"], # 半径范围,内径和外径
label_opts=opts.LabelOpts(formatter="{b}: {d}%") # 标签设置,{d}表示显示百分比)
.set_global_opts(
title_opts=opts.TitleOpts(
title=t),
legend_opts=opts.LegendOpts(pos_left="0%",pos_top="55",orient='vertical')))
return chart
def tree_chart(t, data):
chart = (
TreeMap(init_opts=opts.InitOpts(theme='light', width='700px', height='500px'))
.add(
"城市用户数", # 系列名称
data, # 数据
leaf_depth=1, # 叶子节点深度 城市为1
label_opts=opts.LabelOpts(position="inside", formatter='{b}城\n{c}用户'), # 标签设置
levels=[ # 针对每一层的样式设置
opts.TreeMapLevelsOpts(
treemap_itemstyle_opts=opts.TreeMapItemStyleOpts(
border_color="#555", border_width=4, gap_width=4)),
opts.TreeMapLevelsOpts(
color_saturation=[0.3, 0.6], # 颜色饱和度范围
treemap_itemstyle_opts=opts.TreeMapItemStyleOpts(
border_color_saturation=0.7, gap_width=2, border_width=2))])
.set_global_opts(
title_opts=opts.TitleOpts(
title=t, pos_left='center',
title_textstyle_opts=opts.TextStyleOpts(color='#00BFFF', font_size=20)),
legend_opts=opts.LegendOpts(is_show=False)))
return chart
def bar_chart(t, data):
chart = (
Bar(init_opts=opts.InitOpts(theme='light',width='700px',height='500px'))
.add_xaxis([x[0] for x in data])
.add_yaxis('', [x[1] for x in data],
itemstyle_opts={ # 图元样式
'shadowBlur': 10, # 光影大小
'shadowColor': 'rgba(0, 0, 0, 0.5)', # 阴影颜色
'shadowOffsetY': 5,
'shadowOffsetX': 5, # 偏移量
'barBorderRadius': [0, 10, 10, 0], # 圆角设置},
# 标签设置
label_opts=opts.LabelOpts(
is_show=True, # 显示标签
position='insideRight', # 显示位置
formatter='{c}' # 显示内容 {c}显示数值))
.set_global_opts(
title_opts=opts.TitleOpts(title=t),
xaxis_opts=opts.AxisOpts(position='top'),
visualmap_opts=opts.VisualMapOpts( # 视觉组件
is_show=False,
max_=200,
min_=10,
dimension=0, # 指定使用的数据维度
range_color=['#ffffff', '#00704a'] # 颜色范围)))
return chart
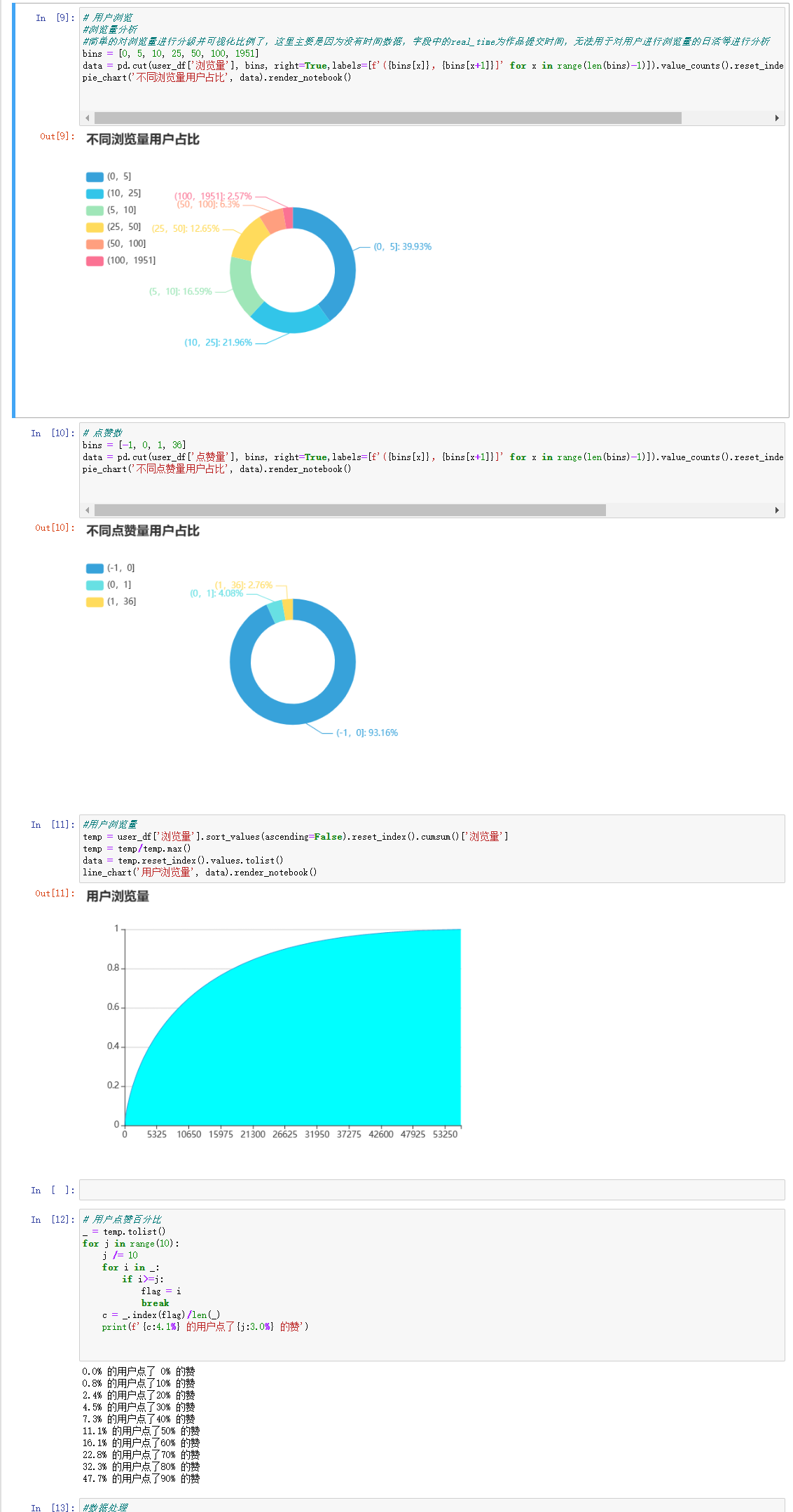
# 用户浏览
#浏览量分析
#简单的对浏览量进行分级并可视化比例了,这里主要是因为没有时间数据,字段中的real_time为作品提交时间,无法用于对用户进行浏览量的日活等进行分析
bins = [0, 5, 10, 25, 50, 100, 1951]
data = pd.cut(user_df['浏览量'], bins, right=True,labels=[f'({bins[x]},{bins[x+1]}]' for x in range(len(bins)-1)]).value_counts().reset_index().values.tolist()
pie_chart('不同浏览量用户占比', data).render_notebook()
# 点赞数
bins = [-1, 0, 1, 36]
data = pd.cut(user_df['点赞量'], bins, right=True,labels=[f'({bins[x]},{bins[x+1]}]' for x in range(len(bins)-1)]).value_counts().reset_index().sort_values(by='index').values.tolist()
pie_chart('不同点赞量用户占比', data).render_notebook()
#用户浏览量
temp = user_df['浏览量'].sort_values(ascending=False).reset_index().cumsum()['浏览量']
temp = temp/temp.max()
data = temp.reset_index().values.tolist()
line_chart('用户浏览量', data).render_notebook()
# 用户点赞百分比
_ = temp.tolist()
for j in range(10):
j /= 10
for i in _:
if i>=j:
flag = i
break
c = _.index(flag)/len(_)
print(f'{c:4.1%} 的用户点了{j:3.0%} 的赞')
#数据处理
item_df = pd.DataFrame()
item_df['id'] = df.groupby('item_id')['like'].count().index.tolist()
item_df['背景音乐'] = df.groupby('item_id')['music_id'].mean().tolist()
item_df['发布城市'] = df.groupby('item_id')['item_city'].mean().tolist()
item_df['浏览量'] = df.groupby('item_id')['like'].count().tolist()
item_df['点赞量'] = df.groupby('item_id')['like'].sum().tolist()
item_df['点赞率'] = item_df['点赞量']/item_df['浏览量']
item_df.describe()
#作品浏览量分布
bins = [0, 1, 2, 4, 1600]
item_df['浏览量等级'] = pd.cut(item_df['浏览量'], bins, labels=[f'({bins[x]},{bins[x+1]}]' for x in range(len(bins)-1)])
data = item_df.groupby('浏览量等级')['id'].count().reset_index().values.tolist()
pie_chart('不同浏览量作品占比', data).render_notebook()
#作品点赞分布
bins = [0, 1, 2, 3, 4, 5, 6, 7, 10, 35]
item_df['点赞等级'] = pd.cut(item_df['点赞量'], bins, labels=[f'[{bins[x]},{bins[x+1]})' for x in range(len(bins)-1)], right=False)
data = item_df.groupby('点赞等级')['id'].count().reset_index().values.tolist()
pie_chart('点赞数分布', data).render_notebook()
user_df = df.groupby('user_city').agg({'uid':pd.Series.nunique}).sort_index()
user_df['用户浏览量'] = df.groupby('user_city')['like'].count()
user_df['用户点赞数'] = df.groupby('user_city')['like'].sum()
user_df['城市作品数'] = df.groupby('item_city').agg({'item_id':pd.Series.nunique})['item_id']
user_df['城市作品浏览量'] = df.groupby('item_city')['like'].count()
user_df['城市作品点赞数'] = df.groupby('item_city')['like'].sum()
user_df.info(null_counts=True)
#发现存在空值,因为有三个城市是没有作品但是有用户的,所以使用0进行填充
user_df.rename (columns = {'uid':'用户数'},inplace = True)
user_df.fillna(0, inplace=True)
user_df.describe()
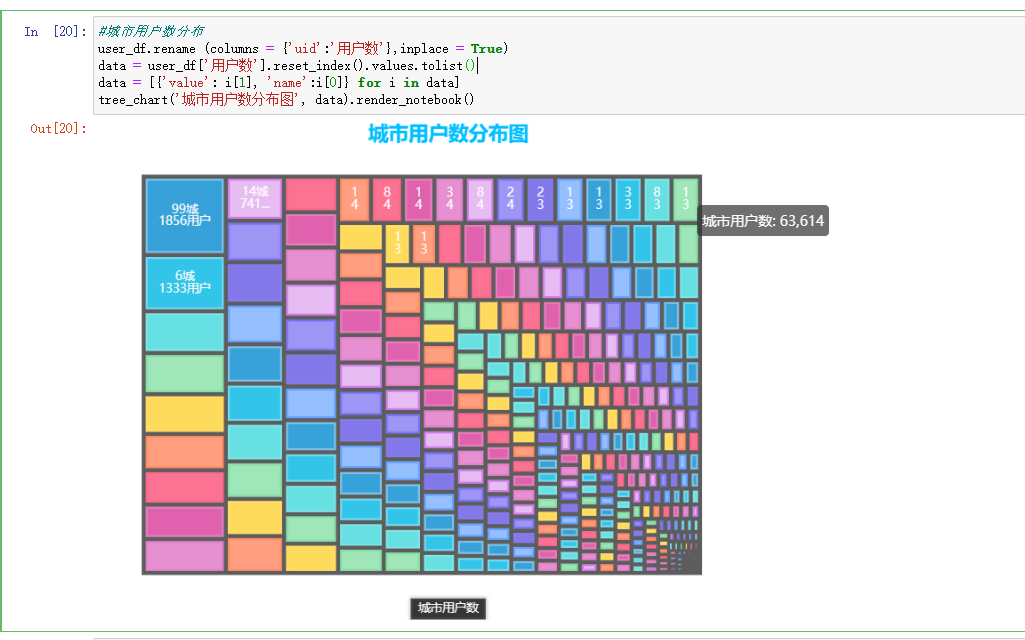
#城市用户数分布
user_df.rename (columns = {'uid':'用户数'},inplace = True)
data = user_df['用户数'].reset_index().values.tolist()
data = [{'value': i[1], 'name':i[0]} for i in data]
tree_chart('城市用户数分布图', data).render_notebook()
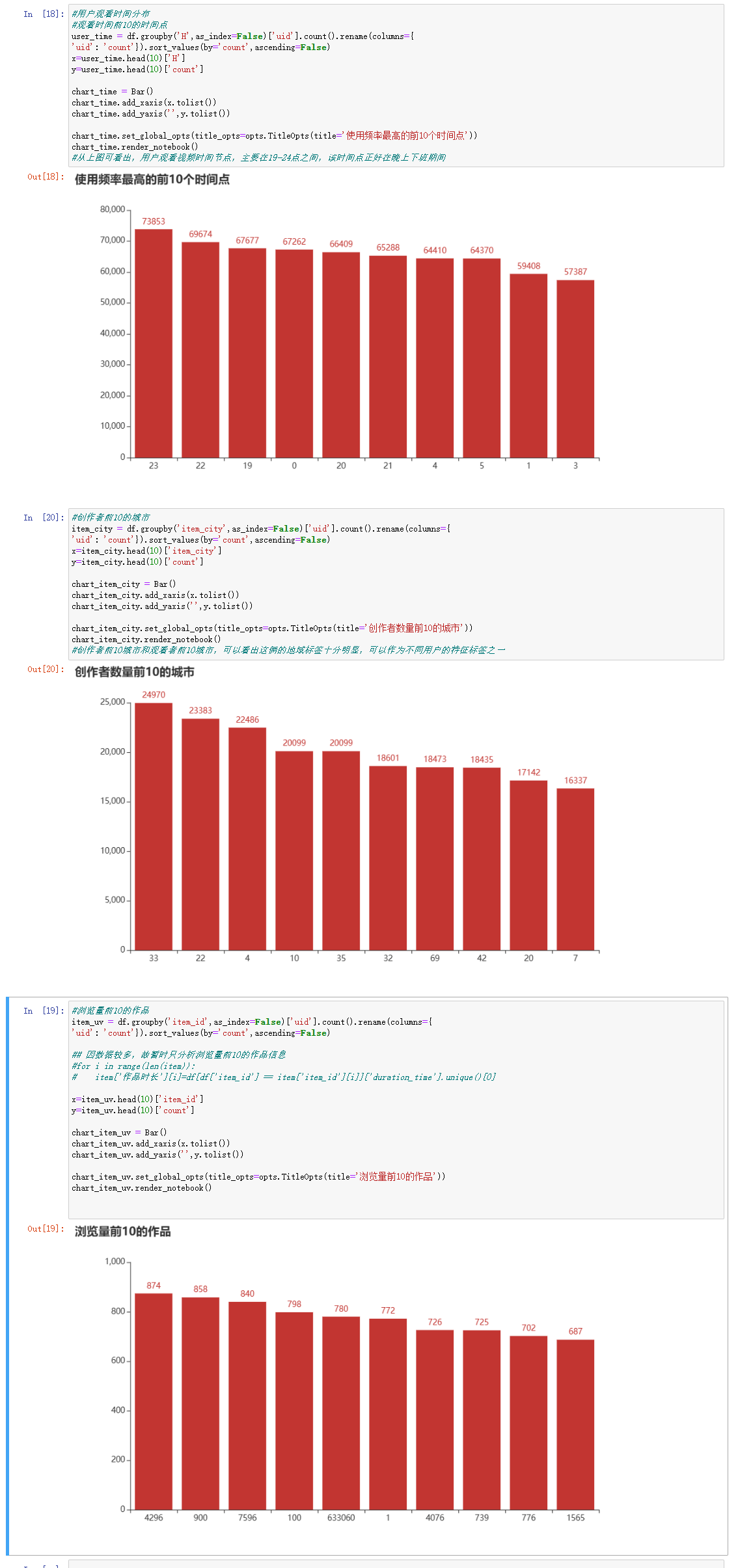
#用户观看时间分布
#观看时间前10的时间点
user_time = df.groupby('H',as_index=False)['uid'].count().rename(columns={
'uid': 'count'}).sort_values(by='count',ascending=False)
x=user_time.head(10)['H']
y=user_time.head(10)['count']
chart_time = Bar()
chart_time.add_xaxis(x.tolist())
chart_time.add_yaxis('',y.tolist())
chart_time.set_global_opts(title_opts=opts.TitleOpts(title='使用频率最高的前10个时间点'))
chart_time.render_notebook()
#从上图可看出,用户观看视频时间节点,主要在19-24点之间,该时间点正好在晚上下班期间
#创作者前10的城市
item_city = df.groupby('item_city',as_index=False)['uid'].count().rename(columns={
'uid': 'count'}).sort_values(by='count',ascending=False)
x=item_city.head(10)['item_city']
y=item_city.head(10)['count']
chart_item_city = Bar()
chart_item_city.add_xaxis(x.tolist())
chart_item_city.add_yaxis('',y.tolist())
chart_item_city.set_global_opts(title_opts=opts.TitleOpts(title='创作者数量前10的城市'))
chart_item_city.render_notebook()
#创作者前10城市和观看者前10城市,可以看出这俩的地域标签十分明显,可以作为不同用户的特征标签之一
#浏览量前10的作品
item_uv = df.groupby('item_id',as_index=False)['uid'].count().rename(columns={
'uid': 'count'}).sort_values(by='count',ascending=False)
## 因数据较多,故暂时只分析浏览量前10的作品信息
#for i in range(len(item)):
# item['作品时长'][i]=df[df['item_id'] == item['item_id'][i]]['duration_time'].unique()[0]
x=item_uv.head(10)['item_id']
y=item_uv.head(10)['count']
chart_item_uv = Bar()
chart_item_uv.add_xaxis(x.tolist())
chart_item_uv.add_yaxis('',y.tolist())
chart_item_uv.set_global_opts(title_opts=opts.TitleOpts(title='浏览量前10的作品'))
chart_item_uv.render_notebook()
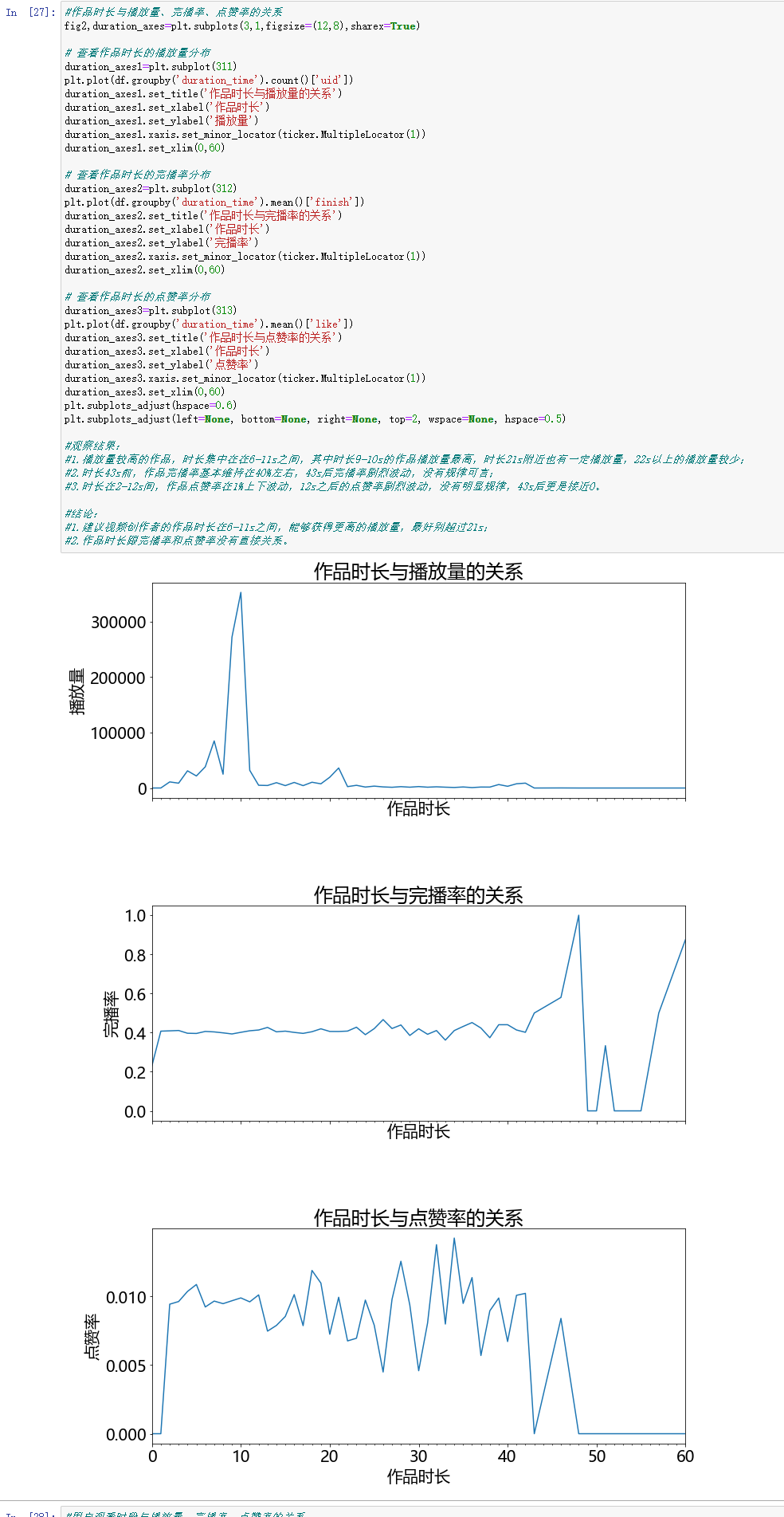
#作品时长与播放量、完播率、点赞率的关系
fig2,duration_axes=plt.subplots(3,1,figsize=(12,8),sharex=True)
# 查看作品时长的播放量分布
duration_axes1=plt.subplot(311)
plt.plot(df.groupby('duration_time').count()['uid'])
duration_axes1.set_title('作品时长与播放量的关系')
duration_axes1.set_xlabel('作品时长')
duration_axes1.set_ylabel('播放量')
duration_axes1.xaxis.set_minor_locator(ticker.MultipleLocator(1))
duration_axes1.set_xlim(0,60)
# 查看作品时长的完播率分布
duration_axes2=plt.subplot(312)
plt.plot(df.groupby('duration_time').mean()['finish'])
duration_axes2.set_title('作品时长与完播率的关系')
duration_axes2.set_xlabel('作品时长')
duration_axes2.set_ylabel('完播率')
duration_axes2.xaxis.set_minor_locator(ticker.MultipleLocator(1))
duration_axes2.set_xlim(0,60)
# 查看作品时长的点赞率分布
duration_axes3=plt.subplot(313)
plt.plot(df.groupby('duration_time').mean()['like'])
duration_axes3.set_title('作品时长与点赞率的关系')
duration_axes3.set_xlabel('作品时长')
duration_axes3.set_ylabel('点赞率')
duration_axes3.xaxis.set_minor_locator(ticker.MultipleLocator(1))
duration_axes3.set_xlim(0,60)
plt.subplots_adjust(hspace=0.6)
plt.subplots_adjust(left=None, bottom=None, right=None, top=2, wspace=None, hspace=0.5)
#观察结果:
#1.播放量较高的作品,时长集中在在6-11s之间,其中时长9-10s的作品播放量最高,时长21s附近也有一定播放量,22s以上的播放量较少;
#2.时长43s前,作品完播率基本维持在40%左右,43s后完播率剧烈波动,没有规律可言;
#3.时长在2-12s间,作品点赞率在1%上下波动,12s之后的点赞率剧烈波动,没有明显规律,43s后更是接近0。
#结论:
#1.建议视频创作者的作品时长在6-11s之间,能够获得更高的播放量,最好别超过21s;
#2.作品时长跟完播率和点赞率没有直接关系。
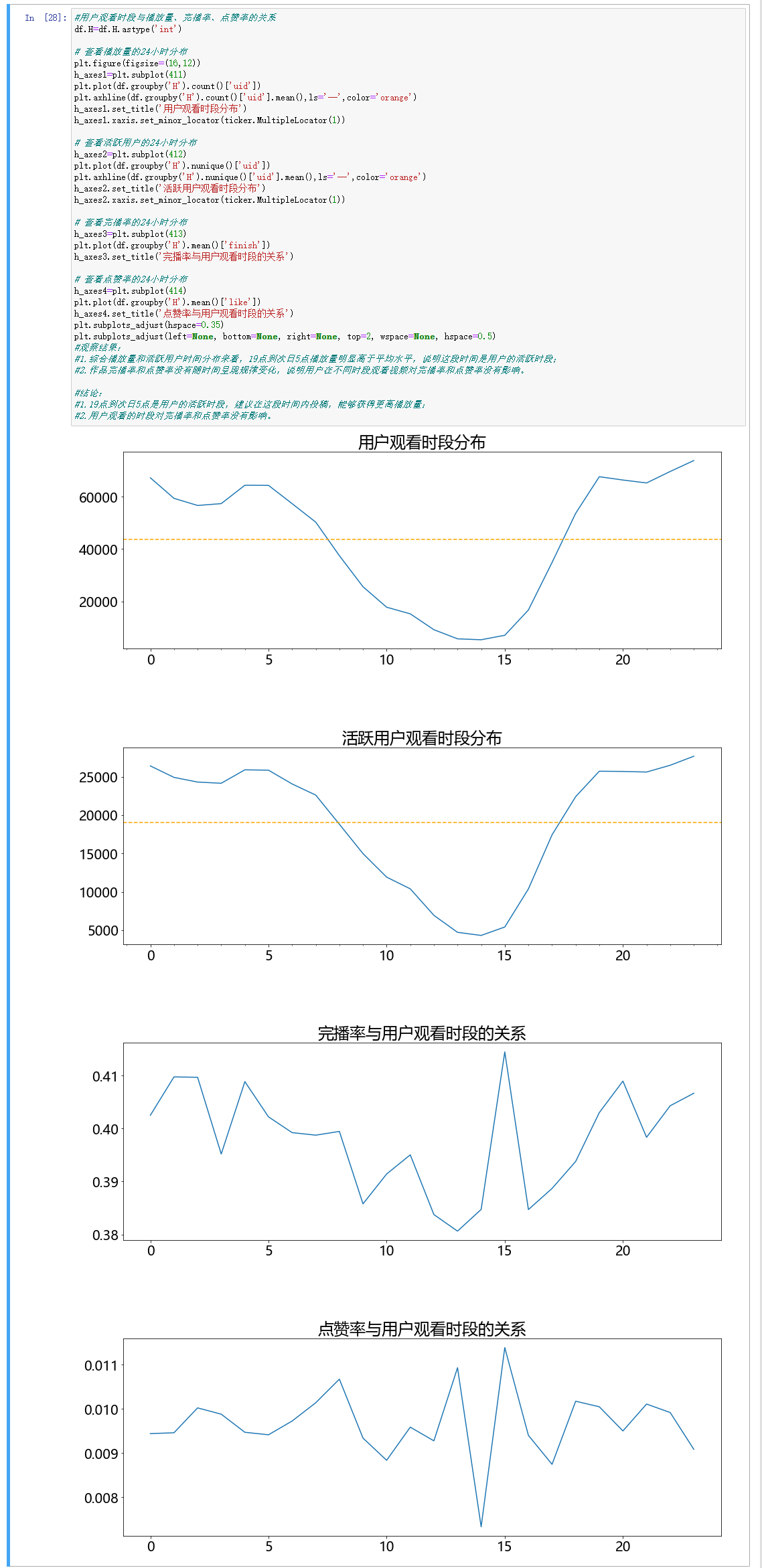
#用户观看时段与播放量、完播率、点赞率的关系
df.H=df.H.astype('int')
# 查看播放量的24小时分布
plt.figure(figsize=(16,12))
h_axes1=plt.subplot(411)
plt.plot(df.groupby('H').count()['uid'])
plt.axhline(df.groupby('H').count()['uid'].mean(),ls='--',color='orange')
h_axes1.set_title('用户观看时段分布')
h_axes1.xaxis.set_minor_locator(ticker.MultipleLocator(1))
# 查看活跃用户的24小时分布
h_axes2=plt.subplot(412)
plt.plot(df.groupby('H').nunique()['uid'])
plt.axhline(df.groupby('H').nunique()['uid'].mean(),ls='--',color='orange')
h_axes2.set_title('活跃用户观看时段分布')
h_axes2.xaxis.set_minor_locator(ticker.MultipleLocator(1))
# 查看完播率的24小时分布
h_axes3=plt.subplot(413)
plt.plot(df.groupby('H').mean()['finish'])
h_axes3.set_title('完播率与用户观看时段的关系')
# 查看点赞率的24小时分布
h_axes4=plt.subplot(414)
plt.plot(df.groupby('H').mean()['like'])
h_axes4.set_title('点赞率与用户观看时段的关系'