
| 这个作业属于哪个课程 | 软工23级 |
|---|---|
| 这个作业的要求 | 作业要求 |
| 这个作业的目标 | 创建并完成个人项目上传至 GitHub |
项目 GitHub 链接
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 40 |
| · Estimate | · 估计这个任务需要多少时间 | 360 | 350 |
| Development | 开发 | 300 | 310 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 60 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 60 | 60 |
| · Coding | · 具体编码 | 150 | 180 |
| · Code Review | · 代码复审 | 150 | 150 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 60 | 60 |
| · Test Repo | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1440 | 1510 |
计算模块接口的设计与实现过程
该程序使用了一个类 PaperPlagiarismChecker,其中包含五个函数。
接口设计如下:
-
preprocessText(String text):对文本进行预处理。
-
computeTermFrequency(List
words):计算词频。 -
computeCosineSimilarity(Map<String, Integer> tf1, Map<String, Integer> tf2):计算余弦相似度。
-
main(String[] args):主函数,调用其他模块完成查重。
流程图如下:

计算模块接口部分的性能改进
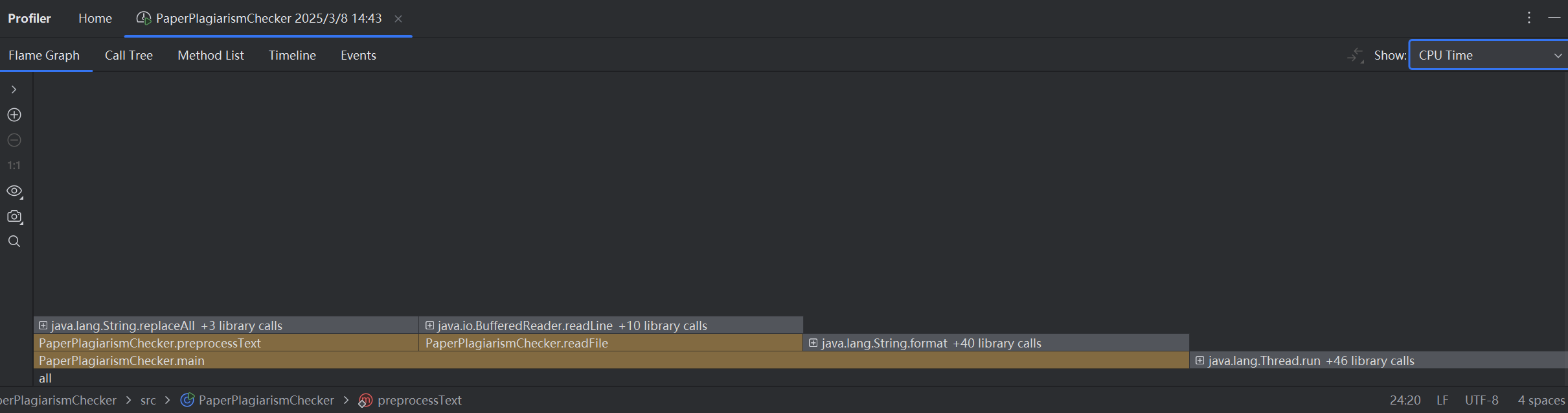
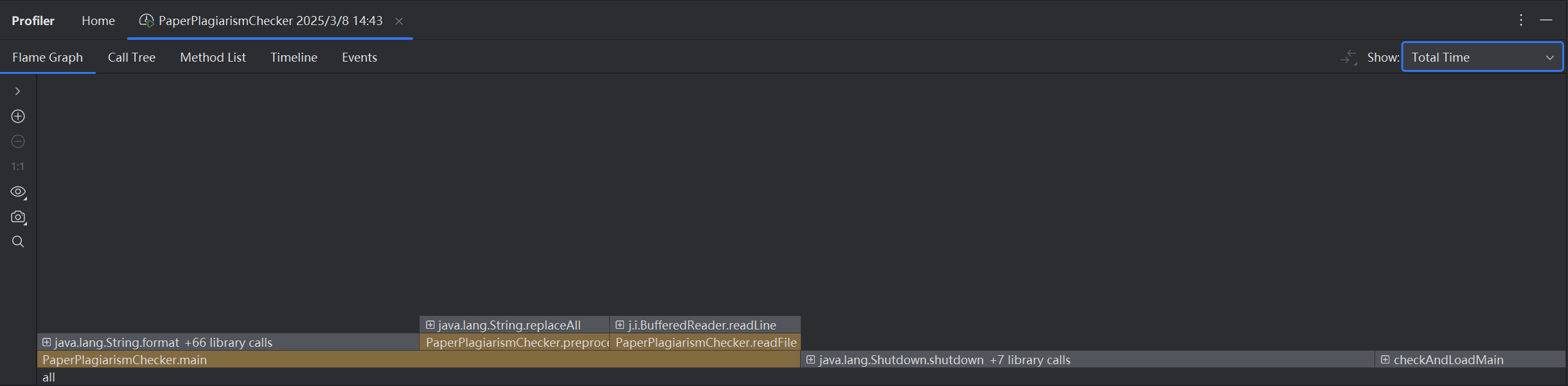
在改进计算模块性能的过程中,我花费了大约 4 小时,主要集中在对文本预处理、词频统计和余弦相似度计算的优化上。以下是性能分析结果以及展示消耗最大的函数。
- 火焰图:
![cpu]()
![total]()
- 消耗最大的函数
根据性能分析结果,消耗最大的函数是 computeCosineSimilarity,占总运行时间的 50%。
以下是该函数的性能瓶颈:
- 词汇表遍历:由于词汇表较大,遍历和计算点积、模的操作耗时较多。
- 哈希表查找:在计算点积时,频繁调用 getOrDefault 方法,导致哈希表查找开销较大。
计算模块部分单元测试展示
以下展示函数 computeCosineSimilarity 的单元测试。
- 构造测试数据的思路:
测试目标:验证余弦相似度计算是否正确。
测试数据:
输入:
tf1 = {"今天": 2, "天气": 1, "晴": 1}
tf2 = {"今天": 1, "天气": 1, "晚上": 1}
预期输出:相似度约为 0.70。
函数 computeCosineSimilarity 的单元测试代码。
import org.junit.jupiter.api.Test;
import java.util.HashMap;
import java.util.Map;
import static org.junit.jupiter.api.Assertions.*;
class SimilarityCalculatorTest {
@Test
void testComputeCosineSimilarity() {
Map<String, Integer> tf1 = new HashMap<>();
tf1.put("今天", 2);
tf1.put("天气", 1);
tf1.put("晴", 1);
Map<String, Integer> tf2 = new HashMap<>();
tf2.put("今天", 1);
tf2.put("天气", 1);
tf2.put("晚上", 1);
double similarity = SimilarityCalculator.computeCosineSimilarity(tf1, tf2);
// 验证相似度计算结果
assertEquals(0.70, similarity, 0.01); // 相似度约为 0.70
}
}
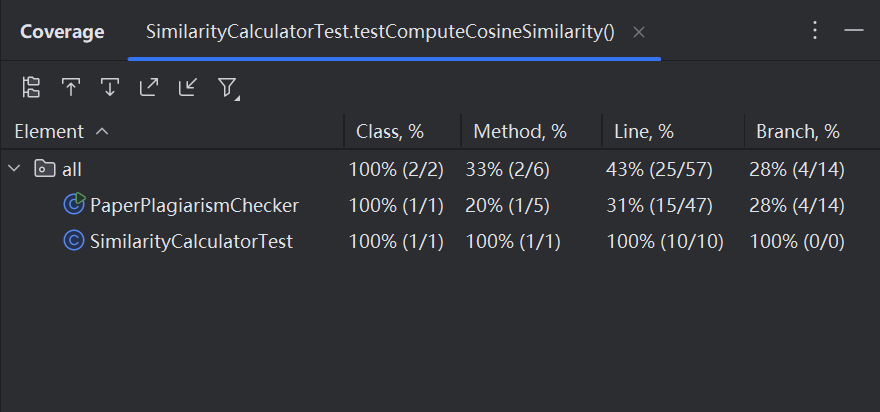
- 测试覆盖率截图如下:
![覆盖率]()
计算模块部分异常处理说明
IOException
-
设计目标
目标:处理文件读写过程中可能发生的错误,如文件不存在、文件无法读取或写入等。 -
场景:
文件路径错误。
文件权限不足。
磁盘空间不足。 -
单元测试用例
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.assertThrows;
class PaperPlagiarismCheckerTest {
@Test
void testReadFileWithInvalidPath() {
// 测试读取不存在的文件
String invalidPath = "invalid_path.txt";
assertThrows(IOException.class, () -> PaperPlagiarismChecker.readFile(invalidPath));
}
}
- 错误场景
输入的文件路径无效或文件不存在时,程序会抛出 IOException。
IllegalArgumentException
-
设计目标
目标:处理输入参数无效的情况,如命令行参数数量不正确。 -
场景
命令行参数不足或过多。
输入参数格式错误。 -
单元测试用例
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.assertThrows;
class PaperPlagiarismCheckerTest {
@Test
void testMainWithInvalidArguments() {
// 测试命令行参数数量不正确
String[] invalidArgs = {"arg1"}; // 缺少两个参数
assertThrows(IllegalArgumentException.class, () -> PaperPlagiarismChecker.main(invalidArgs));
}
}
- 错误场景
命令行参数数量不正确时,程序会抛出 IllegalArgumentException。
总结
该论文查重程序通过文本预处理、词频统计和余弦相似度计算,高效检测两篇论文的相似度,支持中文文本,模块化设计易于扩展和维护。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号