人工智能课预习:7.1 强化学习介绍
强化学习介绍
定义
概念
强化学习 :智能体通过与环境交互,基于奖励反馈进行策略优化,以最大化长期累积回报的机器学习方法。
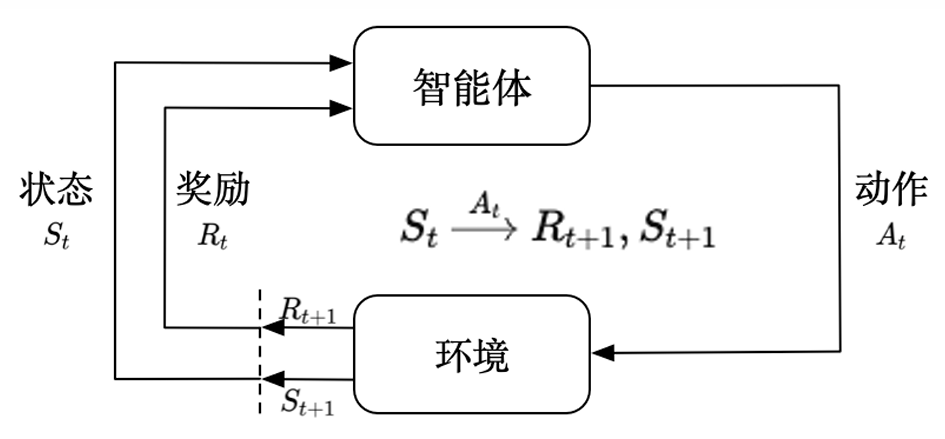
环境(Environment) :外部系统,决定状态如何变化并反馈奖励。接收动作并根据状态转移概率 \(P\) 切换到新状态,并给予奖励 \(𝑹_𝒕\)。
智能体(Agent) :决策主体,观察状态并根据策略 𝝅 选择动作 \(𝑨_𝒕\) 作用于环境。
智能体策略 \(\boldsymbol{\pi}\)
-
确定性策略(Deterministic Policy):𝑎 = 𝜋(𝑠)
-
随机性策略(Stochastic Policy):𝜋(𝑎|𝑠) = 𝑃 [ \(𝐴_𝑡\) = 𝑎 | \(𝑆_𝑡\) = 𝑠 ]
环境状态转移概率 \(\boldsymbol{\mathrm{P}}\)
奖励(Reward,\(R_t\)) :环境对智能体执行动作 \(A_t\) 的即时反馈信号。用于度量动作的好坏。
状态(State,\(S_t\)) :环境在时刻 \(t\) 的信息描述。
动作(Action,\(A_t\)) :智能体在状态 \(S_t\) 下做出的行动。
状态转移(State Transition) :环境根据当前状态 \(S_t\) 和动作 \(A_t\) 更新到新状态 \(S_{t + 1}\),同时给出奖励 \(R_{t + 1}\)。
回报(Return) :从某时刻起所有折扣奖励的总和 \(\boldsymbol{G_t}\)
\(\boldsymbol{\gamma \in [0,1]}\) 是折扣因子
价值函数(Value Function) :评估状态好坏的指标,衡量长期回报。
- 状态价值:
- 动作价值:
模型(Model) :预测环境的下一步变化,表示智能体对环境的估计。
- \(\boldsymbol{P}\)(预测下一时刻的状态):
- \(\boldsymbol{R}\)(预测下一步奖励):
示例:倒立摆(CartPole)
环境(environment):重力场
状态空间(state space):小车位置、速度,杆子角度、角速度
动作空间(action space):对小车施加的力或扭矩
测评的常用指标:
-
平均回合奖励:每个回合获得的总奖励取平均值
-
成功率:限定时间步中的成功率
-
步数:成功持续时间步
特点
试错学习(Trial-and-Error Learning)
不依赖标注数据,通过不断尝试动作、接收反馈(奖励/惩罚)逐步优化策略。
-
不同于监督学习:不依赖监督的“正确答案”,而是通过环境“奖励/惩罚”反馈自我修正。
-
例如:AlphaGo Zero 不需要人类指导,通过胜率结果优化策略,最终超越人类。
延迟奖励(Delayed Reward)
奖励可能滞后于动作,一个动作的好坏可能要经过多个步骤后才能体现。
-
需要智能体学会长期规划,而不是只关注短期利益。
-
例如:围棋中间某一步的价值可能要几步后才能体现。
序列决策(Sequential Decision Making)
智能体的决策具有时间依赖性,每个决策不仅影响当前奖励,还会影响未来的状态和奖励。
-
需考虑长期后果,优化整个策略,而非孤立优化每一步收益。
-
例如:围棋中每一步棋都影响整个棋局的发展,从而产生千变万化的局势走向。
长期回报最大化(Maximizing Cumulative Reward)
强化学习目标是最大化累积奖励,而非单步最优决策。
-
不同于监督学习学到“函数映射”,而是一个策略(Policy) ,告诉智能体在不同状态下应该执行哪个动作才能长期最优。
-
例如:围棋中“弃子争先”,不能为了局部优势而放弃全局的主动权。
环境交互(Environment Interaction)
智能体与环境的交互是动态且持续的,每一步动作影响后续状态,形成动态反馈循环。
-
智能体不仅仅发现数据模式,还可以通过动作改变数据分布。
-
例如:推荐系统根据用户点击行为(动作)调整推送内容(新状态)。
探索与利用权衡(Exploration vs. Exploitation Trade-off)
探索、尝试未知的动作,获取更多信息;利用基于已有经验选择当前最优动作。
-
智能体需要在探索新策略(可能更优)和利用已有策略(当前最佳)之间找到平衡。
-
例如:推荐系统如果一直推荐用户最常点击的内容,可能会错过用户的潜在兴趣。
强化学习与监督学习、无监督学习的区别
监督学习(Supervised Learning)
-
训练数据有明确标签
-
目标是最小化误差
-
学习 “函数映射”
无监督学习(Unsupervised Learning)
-
训练数据没有标签
-
目标是找到数据的潜在模式
-
发现 “数据结构”
强化学习(Reinforcement Learning)
-
数据由智能体通过试错获取
-
目标是最大化长期收益
-
学习 “策略”
应用
围棋、游戏、自动驾驶、机器人、推理大模型
发展
-
早期理论基础:马尔可夫决策过程(MDP)和动态规划(Dynamic Programming)
-
现代强化学习基石:时序差分(Temporal Difference,TD)学习,Q-Learning
-
与深度学习结合:DQN (Deep Q-Network),AlphaGo
-
现代深度强化学习的百花齐放:Actor-Critic 体系,离线强化学习,多智能体强化学习


 浙公网安备 33010602011771号
浙公网安备 33010602011771号