

LDM/SDM
LDM:
把图像VAE进隐空间,Diffusion加噪+UNetCrossAttn去噪,再VAE解码到像素空间输出
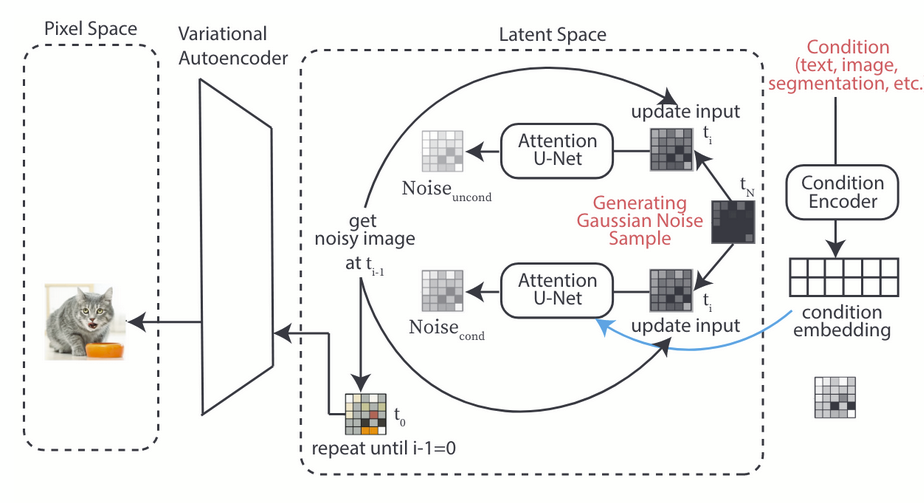
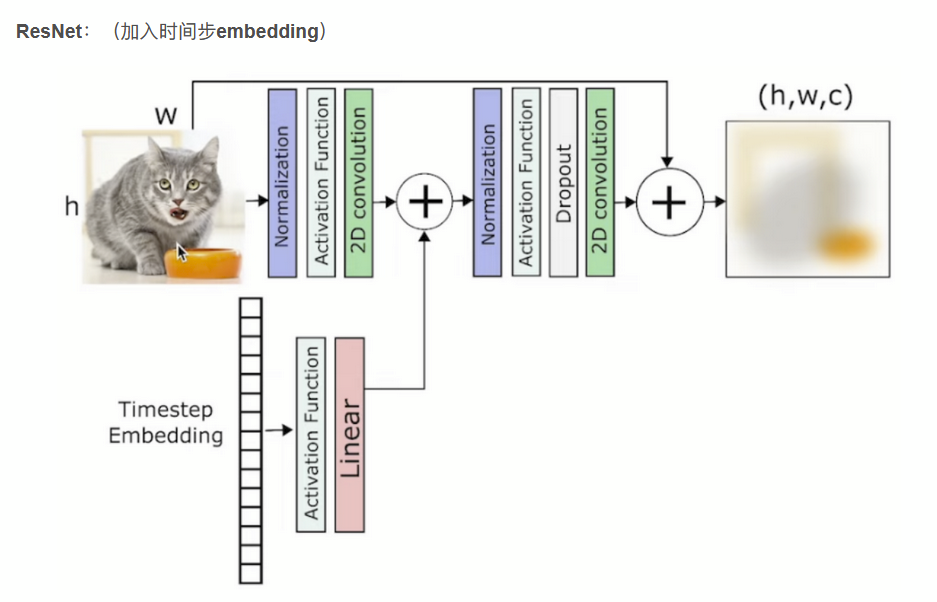
按照时间t,进行不同程度和类型的去噪,所以加入了time-embedding。
把加入了conditional和未加入conditional的图片线性融合,保证平滑
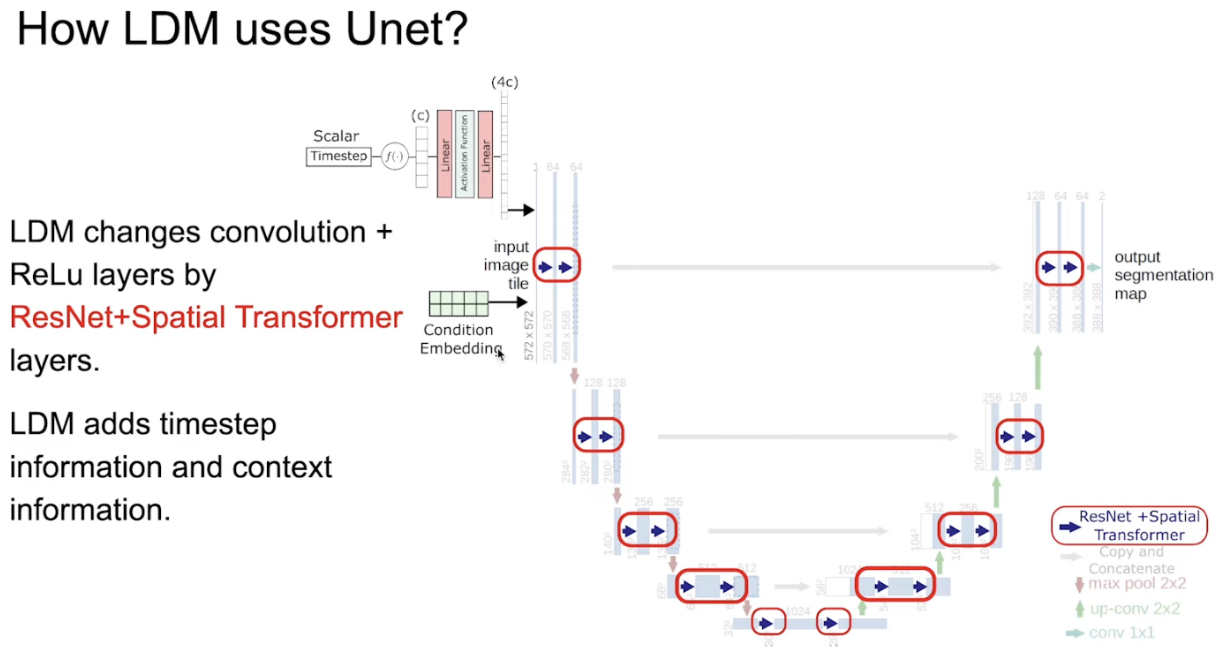
最前面接入resnet,是为了更好地保留中低级特征如边缘、纹理等,同时防止梯度消失,这也是优化unet的一种常用手段。
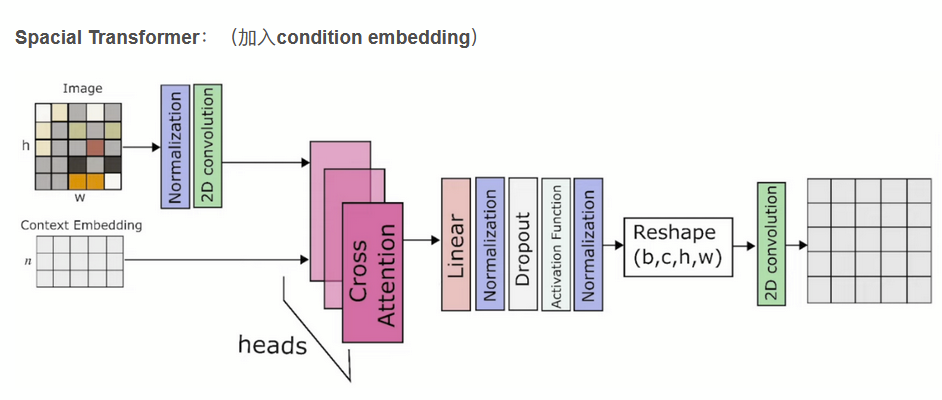
condition encoder随意,可以是CLIP
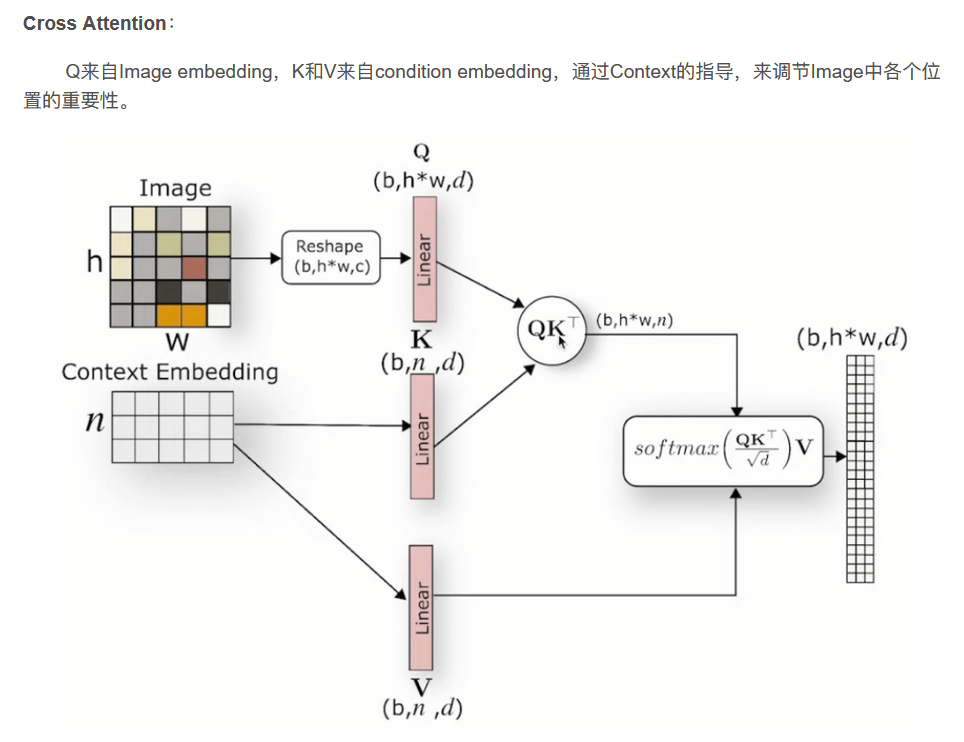
这里魔改了VAE:
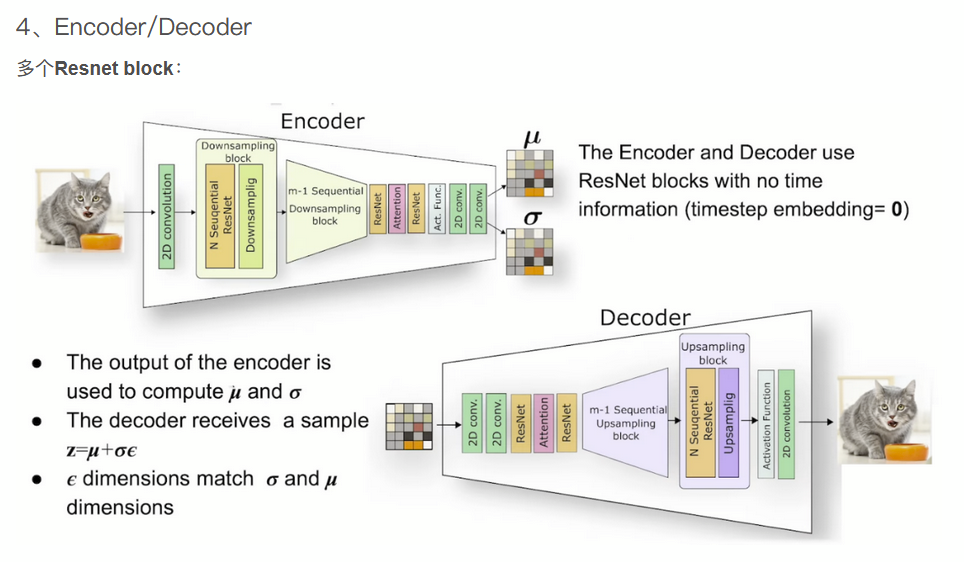
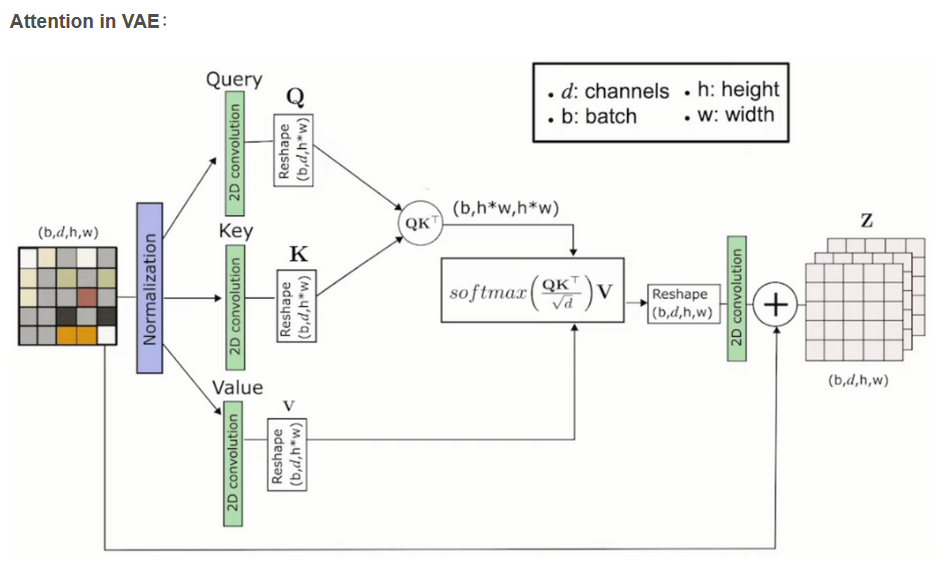
SDM:
灵梦卡哇伊内qwq

 浙公网安备 33010602011771号
浙公网安备 33010602011771号