SQLAlchemy的relationship,创建表详细步骤,使用faker创建假数据,utils——choice功能
relationship函数是sqlalchemy对关系之间提供的一种便利的调用方式, backref参数则对关系提供反向引用的声明
1 背景
如没有relationship,我们只能像下面这样调用关系数据

如果在User中使用relationship定义addresses属性的话,
addresses = relationship('Address')
则我们可以直接在User对象中通过addresses属性获得指定用户的所有地址
2 backref属性

大致原理应该就是sqlalchemy在运行时对Address对象动态的设置了一个指向所属User对象的属性,这样就能在实际开发中使逻辑关系更加清晰,代码更加简洁了
2 例子
>>> from sqlalchemy import Column, Integer, String
>>> class User(Base):
... __tablename__ = 'users'
...
... id = Column(Integer, primary_key=True)
... name = Column(String)
... fullname = Column(String)
... password = Column(String)
...
... def __repr__(self):
... return "<User(name='%s', fullname='%s', password='%s')>" % ( self.name, self.fullname, self.password)
>>> from sqlalchemy import ForeignKey
>>> from sqlalchemy.orm import relationship, backref
>>> class Address(Base):
... __tablename__ = 'addresses'
... id = Column(Integer, primary_key=True)
... email_address = Column(String, nullable=False)
... user_id = Column(Integer, ForeignKey('users.id'))
...
... user = relationship("User", backref=backref('addresses', order_by=id))
...
... def __repr__(self):
... return "<Address(email_address='%s')>" % self.email_address
ForeignKey表示,Addresses.user_id列的值应该等于users.id列中的值,即,users的主键
relationship(), 它告诉 ORM ,Address类本身应该使用属性Address.user链接到User类
relationship()的参数中有一个称为backref()的relationship()的子函数,反向提供详细的信息, 即在users中添加User对应的Address对象的集合,保存在User.addresses中
两个互补关系,
Address.user
和
User.addresses
被称为一个双向关系,并且这是
SQLAlchemy ORM
的一个关键特性
本文学习使用 SQLAlchemy 连接 MySQL 数据库,创建一个博客应用所需要的数据表,并介绍了使用 SQLAlchemy 进行简单了 CURD 操作及使用 Faker 生成测试数据。
1.1 知识要点
- 学会用 SQLALchemy 连接数据库(MySQL, SQLite, PostgreSQL), 创建数据表;
- 掌握表数据之间一对一,一对多及多对多的关系并能转化为对应 SQLAlchemy 描述;
- 掌握使用 SQLAlchemy 进行 CURD 操作;
- 学会使用 Faker 生成测试数据
2. ORM 与 SQLAlchemy 简单介绍
ORM 全称 Object Relational Mapping, 翻译过来叫对象关系映射。简单的说,ORM 将数据库中的表与面向对象语言中的类建立了一种对应关系。这样,我们要操作数据库,数据库中的表或者表中的一条记录就可以直接通过操作类或者类实例来完成。

SQLAlchemy 是Python 社区最知名的 ORM 工具之一,为高效和高性能的数据库访问设计,实现了完整的企业级持久模型。
接下来我们将使用 SQLAlchemy 和 MySQL 构建一个博客应用的实验库。
3. 连接与创建
安装SQLAlchemy
pip install sqlalchemy数据库我们采用Mysql,安装过程这里省略。可参考我的lnmp安装步骤http://www.jianshu.com/p/1e51985b46dd
启动mysql服务
systemctl start mysqld进入数据库命令行
mysql更改数据库授权,远程主机可访问
update mysql.user set Host='%' where HOST='localhost' and User='root';接下来我们使用图形化数据库操作工具(Navicat Premium)来操作数据库
创建一个blog的数据库

安装数据库驱动
pip install pymysql3.1 连接数据库
新建一个db.py的文件,写入下面的内容:
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
__author__ = 'junxi'
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
engine = create_engine('mysql+pymysql://blog:123456@localhost:3306/blog?charset=utf8')
Base = declarative_base()
print(engine)运行:
Engine(mysql+pymysql://blog:***@localhost:3306/blog?charset=utf8)3.2 描述表结构
要使用 ORM, 我们需要将数据表的结构用 ORM 的语言描述出来。SQLAlchmey 提供了一套 Declarative 系统来完成这个任务。我们以创建一个 users 表为例,看看它是怎么用 SQLAlchemy 的语言来描述的:
编辑db.py:
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
__author__ = 'junxi'
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, String, Integer, Text, Boolean, DateTime, ForeignKey, Table
from sqlalchemy.orm import relationship, sessionmaker
engine = create_engine('mysql+pymysql://blog:123456@localhost:3306/blog?charset=utf8')
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
username = Column(String(64), nullable=False, index=True)
password = Column(String(64), nullable=False)
email = Column(String(64), nullable=False, index=True)
def __repr__(self):
return "%s(%r)" % (self.__class__.__name__, self.username)
if __name__ == '__main__':
Base.metadata.create_all(engine)我们看到,在 User 类中,用 __tablename__ 指定在 MySQL 中表的名字。我们创建了三个基本字段,类中的每一个 Column 代表数据库中的一列,在 Colunm中,指定该列的一些配置。第一个字段代表类的数据类型,上面我们使用 String, Integer 俩个最常用的类型,其他常用的包括:
Text
Boolean
SmallInteger
DateTime
ForeignKey
nullable=False 代表这一列不可以为空,index=True 表示在该列创建索引。
另外定义 __repr__ 是为了方便调试,你可以不定义,也可以定义的更详细一些。
运行 db.py
运行程序,我们在Mysql命令行中看看表是如何创建的:
C:\Windows\system32>mysql -ublog -p123456
mysql> use blog;
Database changed
mysql> show create table users\G;
*************************** 1. row ***************************
Table: users
Create Table: CREATE TABLE `users` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(64) NOT NULL,
`password` varchar(64) NOT NULL,
`email` varchar(64) NOT NULL,
PRIMARY KEY (`id`),
KEY `ix_users_username` (`username`),
KEY `ix_users_email` (`email`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)4. 关系定义
4.1 一对多关系
一个普通的博客应用,用户和文章显然是一个一对多的关系,一篇文章属于一个用户,一个用户可以写很多篇文章,那么他们之间的关系可以这样定义:
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
username = Column(String(64), nullable=False, index=True)
password = Column(String(64), nullable=False)
email = Column(String(64), nullable=False, index=True)
articles = relationship('Article')
def __repr__(self):
return "%s(%r)" % (self.__class__.__name__, self.username)
class Article(Base):
__tablename__ = 'articles'
id = Column(Integer, primary_key=True)
title = Column(String(255), nullable=False, index=True, name="标题")
content = Column(Text)
user_id = Column(Integer, ForeignKey("users.id"))
author = relationship('User')
def __repr__(self):
return "%s(%r)" % (self.__class__.__name__, self.title)每篇文章有一个外键指向 users 表中的主键 id, 而在 User 中使用 SQLAlchemy 提供的 relationship 描述 关系。而用户与文章的之间的这个关系是双向的,所以我们看到上面的两张表中都定义了 relationship。
SQLAlchemy 提供了 backref 让我们可以只需要定义一个关系:articles = relationship('Article', backref='author')
添加了这个就可以不用再在 Article 中定义 relationship 了!
4.2 一对一关系
在 User 中我们只定义了几个必须的字段, 但通常用户还有很多其他信息,但这些信息可能不是必须填写的,我们可以把它们放到另一张 UserInfo 表中,这样User 和 UserInfo 就形成了一对一的关系。你可能会奇怪一对一关系为什么不在一对多关系前面?那是因为一对一关系是基于一对多定义的:
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
username = Column(String(64), nullable=False, index=True)
password = Column(String(64), nullable=False)
email = Column(String(64), nullable=False, index=True)
articles = relationship('Article')
userinfo = relationship('UserInfo', backref='user', uselist=False)
def __repr__(self):
return "%s(%r)" % (self.__class__.__name__, self.username)
class UserInfo(Base):
__tablename__ = 'userinfos'
id = Column(Integer, primary_key=True)
name = Column(String(64))
qq = Column(String(11))
phone = Column(String(11))
link = Column(String(64))
user_id = Column(Integer, ForeignKey('users.id'))定义方法和一对多相同,只是需要添加 userlist=False 。
4.3 多对多关系
一篇博客通常有一个分类,好几个标签。标签与博客之间就是一个多对多的关系。多对多关系不能直接定义,需要分解成俩个一对多的关系,为此,需要一张额外的表来协助完成:
"""
# 这是创建表的另一种写法
article_tag = Table(
'article_tag', Base.metadata,
Column('article_id', Integer, ForeignKey('articles.id')),
Column('tag_id', Integer, ForeignKey('tags.id'))
)
"""
class ArticleTag(Base):
__tablename__ = 'article_tag'
id = Column(Integer, primary_key=True)
article_id = Column(Integer, ForeignKey('articles.id'))
tag_id = Column(Integer, ForeignKey('tags.id'))
class Tag(Base):
__tablename__ = 'tags'
id = Column(Integer, primary_key=True)
name = Column(String(64), nullable=False, index=True)
def __repr__(self):
return "%s(%r)" % (self.__class__.__name__, self.name)4.4 映射到数据库
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
__author__ = 'junxi'
"""
mysql://username:password@hostname/database
postgresql://username:password@hostname/database
sqlite:////absolute/path/to/database
sqlite:///c:/absolute/path/to/database
"""
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, String, Integer, Text, Boolean, DateTime, ForeignKey, Table
from sqlalchemy.orm import relationship, sessionmaker
engine = create_engine('mysql+pymysql://blog:123456@localhost:3306/blog?charset=utf8')
Base = declarative_base()
# print(engine)
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
username = Column(String(64), nullable=False, index=True)
password = Column(String(64), nullable=False)
email = Column(String(64), nullable=False, index=True)
articles = relationship('Article')
userinfo = relationship('UserInfo', backref='user', uselist=False)
def __repr__(self):
return "%s(%r)" % (self.__class__.__name__, self.username)
class UserInfo(Base):
__tablename__ = 'userinfos'
id = Column(Integer, primary_key=True)
name = Column(String(64))
qq = Column(String(11))
phone = Column(String(11))
link = Column(String(64))
user_id = Column(Integer, ForeignKey('users.id'))
class Article(Base):
__tablename__ = 'articles'
id = Column(Integer, primary_key=True)
title = Column(String(255), nullable=False, index=True)
content = Column(Text)
user_id = Column(Integer, ForeignKey("users.id"))
author = relationship('User')
def __repr__(self):
return "%s(%r)" % (self.__class__.__name__, self.title)
"""
# 这是创建表的另一种写法
article_tag = Table(
'article_tag', Base.metadata,
Column('article_id', Integer, ForeignKey('articles.id')),
Column('tag_id', Integer, ForeignKey('tags.id'))
)
"""
class ArticleTag(Base):
__tablename__ = 'article_tag'
id = Column(Integer, primary_key=True)
article_id = Column(Integer, ForeignKey('articles.id'))
tag_id = Column(Integer, ForeignKey('tags.id'))
class Tag(Base):
__tablename__ = 'tags'
id = Column(Integer, primary_key=True)
name = Column(String(64), nullable=False, index=True)
def __repr__(self):
return "%s(%r)" % (self.__class__.__name__, self.name)
if __name__ == '__main__':
Base.metadata.create_all(engine)进入MySQL查看:
mysql> use blog;
Database changed
mysql> show tables;
+----------------+
| Tables_in_blog |
+----------------+
| article_tag |
| articles |
| tags |
| userinfos |
| users |
+----------------+
5 rows in set (0.00 sec)所有的表都已经创建好了!
SqlAlchemy本身没有chocie,需要安装这个才能提供choice功能 pip install sqlalchemy-utils 复制代码 from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column,Integer,String from sqlalchemy_utils import ChoiceType from sqlalchemy import create_engine Base = declarative_base() class User(Base): __tablename__ = 'users' type_choices=( (1,'北京'), (2,'上海'), ) id = Column(Integer, primary_key=True) #必须要有主键 name =Column(String(64)) types=Column(ChoiceType(type_choices,Integer())) # 注意:Integer后面要有括号 __table_args__ = { 'mysql_engine': 'InnoDB', 'mysql_charset': 'utf8' } def init_db(): """ 根据类创建数据库表 :return: """ engine = create_engine( "mysql+pymysql://root:123@127.0.0.1:3306/db1?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) Base.metadata.create_all(engine) def drop_db(): """ 根据类删除数据库表 :return: """ engine = create_engine( "mysql+pymysql://root:123@127.0.0.1:3306/db1?charset=utf8", max_overflow=0, # 超过连接池大小外最多创建的连接 pool_size=5, # 连接池大小 pool_timeout=30, # 池中没有线程最多等待的时间,否则报错 pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置) ) Base.metadata.drop_all(engine) if __name__ == '__main__': drop_db() init_db() 复制代码 #! /usr/bin/env python # -*- coding: utf-8 -*- # __author__ = "HuChong" # Date: 2018/1/12 from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine from ru import User engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/db1", max_overflow=0, pool_size=5) Session = sessionmaker(bind=engine) session = Session() obj1 = User(name="xz",types=1) obj2 = User(name="zz",types=2) session.add_all([obj1,obj2]) session.commit() session.close() 复制代码 复制代码 #! /usr/bin/env python # -*- coding: utf-8 -*- # __author__ = "HuChong" # Date: 2018/1/12 from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine from ru import User engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/db1", max_overflow=0, pool_size=5) Session = sessionmaker(bind=engine) session = Session() result_list=session.query(User).all() print(result_list) for item in result_list: print(item.types) print(item.types.code,item.types.value) session.close() #######打印结果如下######## ''' [<ru.User object at 0x0386D770>, <ru.User object at 0x0386D7D0>] Choice(code=1, value=北京) 1 北京 Choice(code=2, value=上海) 2 上海 '''
1. 安装 pip install Faker 2. 语法 faker [-h] [--version] [-o output] [-l {bg_BG,cs_CZ,...,zh_CN,zh_TW}] [-r REPEAT] [-s SEP] [-i {package.containing.custom_provider otherpkg.containing.custom_provider}] [fake] [fake argument [fake argument ...]] __faker:__是安装在您的环境时,脚本,在发展中可以使用,而不是python -m faker __-h,--help:__显示帮助消息 __--version:__显示程序的版本号 __-o FILENAME:__重定向输出到指定的文件名 __-l {bg_BG,cs_CZ,...,zh_CN,zh_TW}:__允许使用本地化的供应商 __-r REPEAT:__将生成的输出的特定数量的 __-s SEP:__将生成的每个产生的输出后的指定的分隔 __-i {my.custom_provider other.custom_provider}:__使用其他自定义供应商名单。请注意,是包含您提供一流的,而不是定制的Provider类本身包的导入路径。 __fake:__是产生一个输出,该假的名称,如 name,address或text __[fake argument ...]:__可选参数传递到假(例如,简档假取的逗号分隔的字段名作为第一个参数的可选列表) 3. 使用 I. 引用 from faker import Faker from faker import Factory #引入工厂类 II. 创建初始化生成器 fake = Faker() 可以在初始化时设置本地化,即是设定区域,如下: fake = Faker("zh_CN") fake.name() image.png III. 属性 除了生成姓名,faker还提供很多其他属性/方法用作数据生成 fake.city() # 城市名称 North Karen ***************************** fake.street_name() # 街道名称 Lopez Dale ***************************** fake.country_code() # 国家编号 ML ***************************** fake.longitude() # 经度 109.213240 ***************************** fake.address() # 地址 7927 Christopher Lake Thomasmouth, ME 73174 ***************************** fake.latitude() # 纬度 -79.2992145 ***************************** fake.street_address() # 街道地址 7775 Jacob Wall Apt. 561 ***************************** fake.city_suffix() # 市 view ***************************** fake.postcode() # 邮政编码 34098 ***************************** fake.country() # 国家 Estonia ***************************** fake.street_suffix() # 街道后缀 River ***************************** fake.building_number() # 建筑编号 5330 ***************************** fake.license_plate() # 车牌号 Q97 2BU ***************************** fake.rgb_css_color() #颜色RGB rgb(220,140,229) ***************************** fake.safe_color_name() # 颜色名称 white ***************************** fake.company() # 公司名 Roberts, Bates and Parker ***************************** fake.credit_card_number(card_type=None) # 信用卡卡号 3568612931335293 ***************************** fake.date_time(tzinfo=None) # 随机日期时间 1996-07-18 02:05:39 ***************************** fake.file_extension(category=None) # 文件扩展信息 bmp ***************************** fake.ipv4(network=False) # ipv4地址 96.137.50.163 ***************************** 4. 实例 这里用一个生成user-agent的实例来展示用法,可广泛应用于爬虫当中 #引入 from faker import Faker #初始化 faker = Faker(locale='zh_CN') agent_list = [] for i in range(10): #生成ua ua = faker.user_agent() agent_list.append(ua)
举一个比较经典的关系,部门与员工(以下是我的需求情况,算是把该有的关系都涉及到了)
1.每个部门会有很多成员(这里排除一个成员属于多个部门的情况) ---> 一对多
2.每个部门都有一个负责人 ---> 多对一
3.每个部门可能有一个上级部门 ---> 自关联多对一
4.每个员工都有一个主属部门 ---> 多对一
5.每个员工可能有很多附属部门 ---> 多对多
6.每个员工可能有很多上级员工 ---> 自关联多对多
二. 设计部门与成员表模型
直接附上模型表代码,但是不包含关系映射(单独写一步)

from sqlalchemy.ext.declarative import declarative_base
BaseModel = declarative_base() # 创建模型对象的基类
# 部门
class Department(BaseModel):
__tablename__ = 'dep'
id = Column(Integer(), primary_key=True, autoincrement=True)
name = Column(String(30),nullable=False,unique=True) # 部门名称
staff_id = Column(Integer(),ForeignKey('staff.id')) # 负责人
up_dep_id = Column(Integer(),ForeignKey('dep.id')) # 上级部门----自关联
def __repr__(self): # 方便打印查看
return '<Department %s>' % self.name
# 员工
class Staff(BaseModel):
__tablename__ = 'staff'
id = Column(Integer(), primary_key=True, autoincrement=True)
name = Column(String(30),nullable=False,unique=True) # 员工名称
main_dep_id = Column(Integer(),ForeignKey('dep.id')) # 主要部门
def __repr__(self):
return '<Staff %s>' % self.name
三. 设计第三方表模型--附属部门与上级员工
建立多对多关系映射时secondary参数需要指定一个第三方表模型对象,但不是自己写的Class哦,而是一个Table对象
from sqlalchemy import Table # 使用Table专门生成第三方表模型
# 第三方表--附属部门
aux_dep_table = Table('staff_aux_dep',BaseModel.metadata,
Column('id',Integer(),primary_key=True, autoincrement=True),
Column('dep_id', Integer(), ForeignKey('dep.id',ondelete='CASCADE')),
Column('staff_id', Integer(), ForeignKey('staff.id',ondelete='CASCADE'))
)
# 第三方表--上级员工
up_obj_table = Table('staff_up_obj',BaseModel.metadata,
Column('id',Integer(),primary_key=True, autoincrement=True),
Column('up_staff_id', Integer(), ForeignKey('staff.id',ondelete='CASCADE')),
Column('down_staff_id', Integer(), ForeignKey('staff.id',ondelete='CASCADE'))
)
四. 生成表
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test?charset=utf8') # 关联数据库
DBSession = sessionmaker(engine) # 创建DBSession类
session = DBSession() # 创建session对象
BaseModel.metadata.create_all(engine) # 数据库生成表
五. relationship--关系映射
简单来说, relationship函数是sqlalchemy对关系之间提供的一种便利的调用方式, relationship的返回值赋给的变量名为正向调用的属性名,绑定给当前表模型类中,而backref参数则是指定反向调用的属性名,绑定给关联的表模型类中,如下部门表中Department.staffs就为正向,Staff.main_dep就为反向。
先导入relationship
from sqlalchemy.orm import relationship
先映射部门表,需要注意的是:
1. 是由于部门与员工之间有多重外键约束,在多对一或一对多关系相互映射时需要用foreign_keys指定映射的具体字段
2. 自关联多对一或一对多时候,需要用remote_side参数指定‘一’的一方,值为一个Colmun对象(必须唯一)
# 部门
class Department(BaseModel):
__tablename__ = 'dep'
id = Column(Integer(), primary_key=True, autoincrement=True)
name = Column(String(30), nullable=False, unique=True) # 部门名称
staff_id = Column(Integer(), ForeignKey('staff.id')) # 负责人
up_dep_id = Column(Integer(), ForeignKey('dep.id')) # 上级部门----自关联
# 主属部门为此部门的所有员工,反向Staff实例.main_dep获取员工的主属部门
main_staffs = relationship('Staff', backref='main_dep', foreign_keys='Staff.main_dep_id')
# 部门的直属上级部门,反向Department实例.down_deps,获取部门的所有直属下级部门(自关联多对一需用remote_side=id指定‘一’的一方)
up_dep = relationship('Department', backref='down_deps', remote_side=id)
重新生成数据(当调用属性映射的为‘多’的一方,则代表的是一个InstrumentedList 类型的结果集,是List的子类,对这个集合的修改,就是修改外键关系)
staff_names = ['我','你','他','她','它'] dep_names = ['1部','2部','21部','22部'] staff_list = [Staff(name=name) for name in staff_names] dep_list = [Department(name=name) for name in dep_names] # 为所有员工初始分配一个主属部门(按列表顺序对应) [dep.main_staffs.append(staff) for staff,dep in zip(staff_list,dep_list)] # 关联上下级部门(2部的上级为1部,2部的下级为21、22部) dep_list[1].up_dep = dep_list[0] dep_list[1].down_deps.extend(dep_list[2:]) session.add_all(staff_list + dep_list) session.commit() # 数据持久化到数据库
部门表关系映射 查询测试
dep_2 = session.query(Department).filter_by(name='2部').one() # 获取 2部 部门 staff_me = session.query(Staff).filter(Staff.name=='我').one() # 获取 ‘我’ 员工
print(dep_2.main_staffs) # 主属部门为2部的所有员工 print(dep_2.up_dep) # 2部的上级部门 print(dep_2.down_deps) # 2部的所有直属下级部门 print(staff_me.main_dep) # 员工‘我’ 的主属部门 # [<Staff 你>] # <Department 1部> # [<Department 21部>, <Department 22部>] # <Department 1部>
映射员工表,需要注意的是:
1. 多对多关系中需要用secondary参数指定第三方表模型对象
2. 自关联多对多需要用primaryjoin和secondaryjoin指定主副连接关系,查询逻辑是根据主连接关系对应的第三方表的字段查询(例,查询id为10的员工的所有上级对象,就会在第三方表里查询down_staff_id=10对应的所有数据,而把每条数据的up_staff_id值对应员工表的id查询出来的对象集合,就为id为10的员工的所有上级对象了)
# 员工
class Staff(BaseModel):
__tablename__ = 'staff'
id = Column(Integer(), primary_key=True, autoincrement=True)
name = Column(String(30), nullable=False, unique=True) # 员工名称
main_dep_id = Column(Integer(), ForeignKey('dep.id')) # 主要部门
# 员工的所有附属部门,反向为所有附属部门为此部门的员工
aux_deps = relationship(Department, secondary=aux_dep_table,backref = 'aux_staffs')
# 员工的所有直属上级员工,反向为员工的所有直属下级员工(自关联多对多需要指定第三方表主连接关系与副连接关系,查询逻辑是根据主连接关系对应的第三方表的字段查询)
up_staffs = relationship('Staff', secondary=up_obj_table,
primaryjoin = id == up_obj_table.c.down_staff_id, # 主连接关系 为 本表id字段对应第三方表的down_staff_id
secondaryjoin = id == up_obj_table.c.up_staff_id, # 副连接关系 为 本表id对应第三表的up_staff_id
backref = 'down_staffs')
建立数据映射关系
staff_all_list = session.query(Staff).all() # 获取所有员工对象列表 dep_1 = session.query(Department).filter_by(name='1部').one() # 获取 部门 1部 dep_2 = session.query(Department).filter_by(name='2部').one() # 获取 部门 2部 staff_me = session.query(Staff).filter_by(name='我').one() # 获取员工 ‘我’ dep_1.aux_staffs.extend(staff_all_list) # 分配所有员工的附属部门都为1部 staff_me.aux_deps.append(dep_2) # 给员工‘我’额外分配附属部门2部 staff_all_list.remove(staff_me) staff_me.down_staffs.extend(staff_all_list) # 将所有除员工‘我’以外的员工 都成为 员工‘我’的下级 session.commit()
员工表关系映射 查询测试
staff_you = session.query(Staff).filter_by(name='你').one() # 获取员工 你 print(dep_1.aux_staffs.all()) # 所有附属部门为1部的员工 print(staff_me.aux_deps.all()) # 员工‘我’ 的所有附属部门 print(staff_me.down_staffs.all()) # 员工‘我’ 的所有直属下级员工 print(staff_you.up_staffs.all()) # 员工‘你’ 的所有直属上级员工 # [<Staff 我>, <Staff 你>, <Staff 他>, <Staff 她>, <Staff 它>] # [<Department 1部>] # [<Staff 你>, <Staff 他>, <Staff 她>, <Staff 它>] # [<Staff 我>]
如果我们想根据调用属性获得的集合,再进行筛选,可以吗?
模拟个场景,我已经知道了员工‘我’有一个附属部门叫‘1部’了,我想知道除了‘1部’的其他附属部门,如下:
from sqlalchemy import not_ staff_me.aux_deps.filter(not_(Department.name=='1部')) # AttributeError: 'InstrumentedList' object has no attribute 'filter'
报错了,也是,之前都说了,调用属性映射的为‘多’的一方代表的是一个InstrumentedList 对象,只有为Query对象才能有filter、all、one等的方法。
那么该怎么转换成Query对象呢,通过查看relationship的参数,发现了lazy,通过改变它的值可以在查询时可以得到不同的结果,他有很多值可以选择:
1. 默认值为select, 他直接会导出所有的结果对象合成一个列表
aux_deps = relationship(Department, secondary=aux_dep_table, backref='aux_staffs', lazy='select') print(type(staff_me.aux_deps)) print(staff_me.aux_deps) # <class 'sqlalchemy.orm.collections.InstrumentedList'> # [<Department 1部>, <Department 2部>]
2. dynamic,他会生成一个继承与Query的AppenderQuery对象,可以用于继续做过滤操作,这就是我们模拟的场景想要的,需要注意的是,如果调用属性映射的不是‘多’而是‘一’的一方,那么就会报错(虽然为默认值select没有影响,但本来就一个结果,就不要加lazy参数了)
aux_deps = relationship(Department, secondary=aux_dep_table, backref='aux_staffs', lazy='dynamic') print(type(staff_me.aux_deps)) print(staff_me.aux_deps.all()) # 获取员工‘我’的所有附属部门 print(staff_me.aux_deps.filter(not_(Department.name == '1部')).all()) # 获取员工‘我’除1部以外的所有附属部门 # <class 'sqlalchemy.orm.dynamic.AppenderQuery'> # [<Department 1部>, <Department 2部>] # [ <Department 2部>]
3. 其他的还有很多参数,例如joined,连接查询,使用不当会有性能问题,以下为谷歌翻译的,大家有兴趣可以去看看原文https://docs.sqlalchemy.org/en/latest/orm/relationship_api.html,ctrl+f搜lazy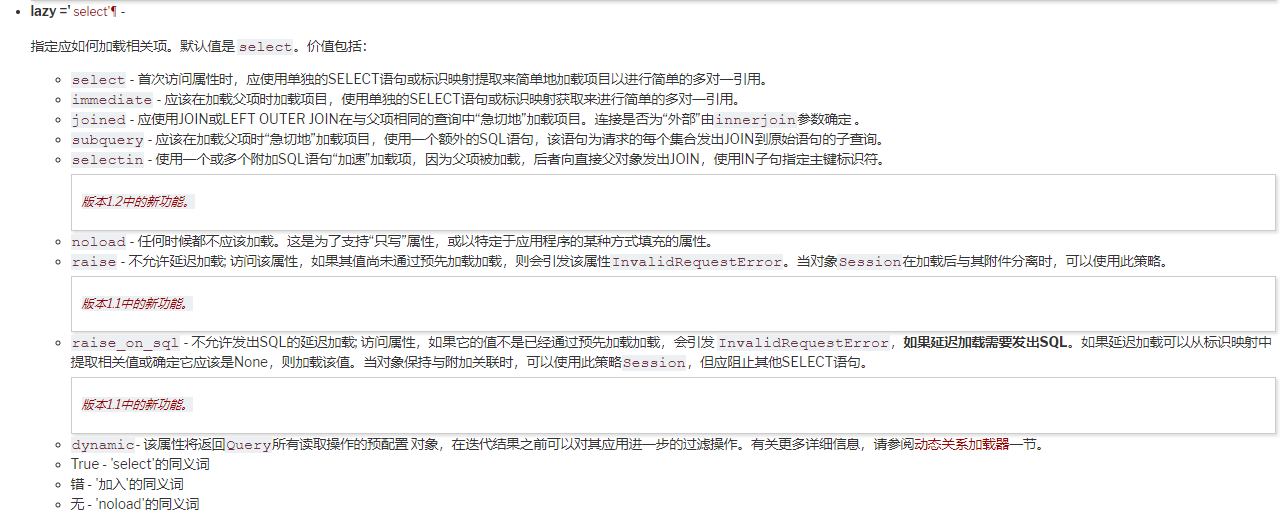
我们现在知道当需要对映射的结果集继续筛选的时候,可以在relationship指定lazy参数为'dynamic',但是在这里加好像只是正向调用的时候有效,反向还是为InstrumentedList 对象
dep_1 = session.query(Department).filter_by(name='1部').one() # 获取 部门 1部 print(dep_1.aux_staffs.all()) # 获取所有附属部门为1部的员工 # AttributeError: 'InstrumentedList' object has no attribute 'all'
如果反向的时候我们该加在哪里呢?其实backref参数也可以接受一个元祖,里面只能是两个参数,一个跟之前一样是个字符串,为反向调用的属性名,另一个就是一个加关于反向调用时的参数(dict对象)
aux_deps = relationship(Department, secondary=aux_dep_table, backref=('aux_staffs',{'lazy':'dynamic'}), lazy='dynamic')
print(type(dep_1.aux_staffs.all()))
print(dep_1.aux_staffs.all()) # 获取所有附属部门为1部的员工
# <class 'sqlalchemy.orm.dynamic.AppenderQuery'>
# [<Staff 我>, <Staff 你>, <Staff 他>, <Staff 她>, <Staff 它>]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号