

数字电路模拟程序
第二阶段大作业总结 老传统: Hello World!😉
来自NCHU 23级 物联网工程 71班❤️
1. 前言
1.1 知识点覆盖
-
JAVA基础语法
- 正则表达式:
使用Pattern和Matcher进行复杂字符串模式匹配 - 泛型与集合:
List,Map<K,V>,ArrayList,HashMap等数据结构 - 异常处理:
NumberFormatException,NullPointerException等异常 - 字符串处理:
split(),substring(),contains(),lastIndexOf()等 - 包装类与空值处理:
使用Boolean包装类处理三态逻辑
- 正则表达式:
-
面向对象特性
- 抽象类与继承:
Pin抽象类,InputPin和OutputPin子类据说可以省略Pin类 😏
- 接口设计:
Component接口定义组件通用行为 - 多态与运行时绑定:
通过接口类型引用具体组件对象 - 封装类与访问控制:
split(),substring(),contains(),lastIndexOf()等 - 构造方法与重载:
支持不同参数的构造方法
- 抽象类与继承:
-
程序设计模式
- 工程模式:
ComponentFactory根据字符串标识符创建组件实例 - 组合关系:
Circuit组合多个Component,Component组合多个Pin - 模板方法:
LogicGate抽象类定义算法骨架,子类实现具体逻辑其实就是接口定义的模板函数 😏
- 迭代器模式:
使用增强for循环遍历集合元素其实就是for each 😎
- 工程模式:
-
核心算法
- 电路模拟算法:
迭代传播信号直到稳定状态此处也是参考DeepSeek的算法 😗 想破头也是不知道要这么设计,学废了😅
- 拓扑排序思想:
按组件类型和编号顺序计算但注意这里不是严格的拓扑排序,因为存在反馈电路,所以采用迭代直到稳定的方式配合...也是改了几遍才满意 😅
- 引脚连接查找:
基于ID的快速映射和查找 - 三态逻辑处理:
支持有效值、无效值和高阻态 - 组合电路计算:
各个逻辑元件有不同的计算逻辑,需要分别实现
- 电路模拟算法:
-
输入输出
- 流式输入处理:
使用Scanner读取标准输入,按行处理,直到遇到结束标志"end" - 复杂格式解析:
解析INPUT:、[连接]等格式的输入数据为了与工厂类配合,也是磨了很久😵
- 格式化输出
按照元件类型和编号顺序,输出每个元件的输出引脚状态,对于译码器和数据分配器有特殊的输出格式
- 流式输入处理:
1.2 题量
-
第一次作业:
核心实现:
- 组件类:5个(AndGate、OrGate、NotGate、XorGate、XnorGate)
- 核心类:5个(Pin、InputPin、OutputPin、CircuitInput、LogicGate)
- 辅助类:3个(Connection、Circuit、ComponentFactory)
- 总计类数:13个
- 代码行数:约700行
主要复杂度:
- 处理5种基本逻辑门
- 简单的连接关系建立
- 信号传播计算
- 组件排序输出
-
第二次作业:
核心实现-
新增组件类:5个(ThreeStateGate、Decoder、Multiplexer、Demultiplexer)
-
总组件类:9个(在第一次基础上新增4个)
-
核心类:新增约5个(包含增强的LogicGate等)
- 总计类数:约18个(相比第一次增加5个)
- 代码行数:约1000行(在第一次代码基础上增加)
新增复杂度
- 三态逻辑:支持无效状态(null值)
- 多输入输出组件:译码器、多路选择器、分配器
- 控制引脚概念:新增引脚类型
- 复杂排序逻辑:9种组件按特定顺序输出
- 特殊输出格式:译码器输出索引、分配器输出模式
- 增强的连接查找:支持更复杂的引脚编号规则
- 增强的工厂模式:支持9种组件创建
-
1.3 难度
正常情况,题目是依次递增,但后来总结才感觉最麻烦的还是设计,为了类之间的配合,需要考虑很多细节. 比如为了实现工厂类的独立,输入的正则表达式应该怎么设计合适? 到底要不要设计Pin? 到底要不要设计Connection,将电路和引脚进一步抽出来?...
最后也是选择:
设计最多的类,写最多的代码...👽👹
第一次作业的代码就给我干到将近700行(了解其他同学普遍500左右的代码量)... 但第二次没怎么改,只是增加了新组件,修改了一些逻辑.只增加了200行左右.好在所有测试点可以过。
最后细想,想要做到只增不改的开闭原则还是很难.😵
但是写完可运行的代码还只是开始,更麻烦的是测试(第一次还好,关键是第二次).PTA提供的测试用例完全不够,需要自己设计一些测试用例.光这一步就很劝退.很多时候写代码都是按照常规思路,设计的测试用例往往只会按照自己的思路.很多隐含的🐛很难发现.
这个时候几个办法:
1.睡觉😴,等代码忘得差不多再测试👊👊👊.
2.向同学借测试用例👬
3.让AI设计测试用例(一般不靠谱)👎👎👎
2. 设计与分析
WEEK1
week1.1 类图设计
最开始的设计,选择设计Pin和Connection以及工厂类,类图比较复杂:

实际实现的类图(此处偷下懒😋,就直接使用IDEA自带的类图工具生成):
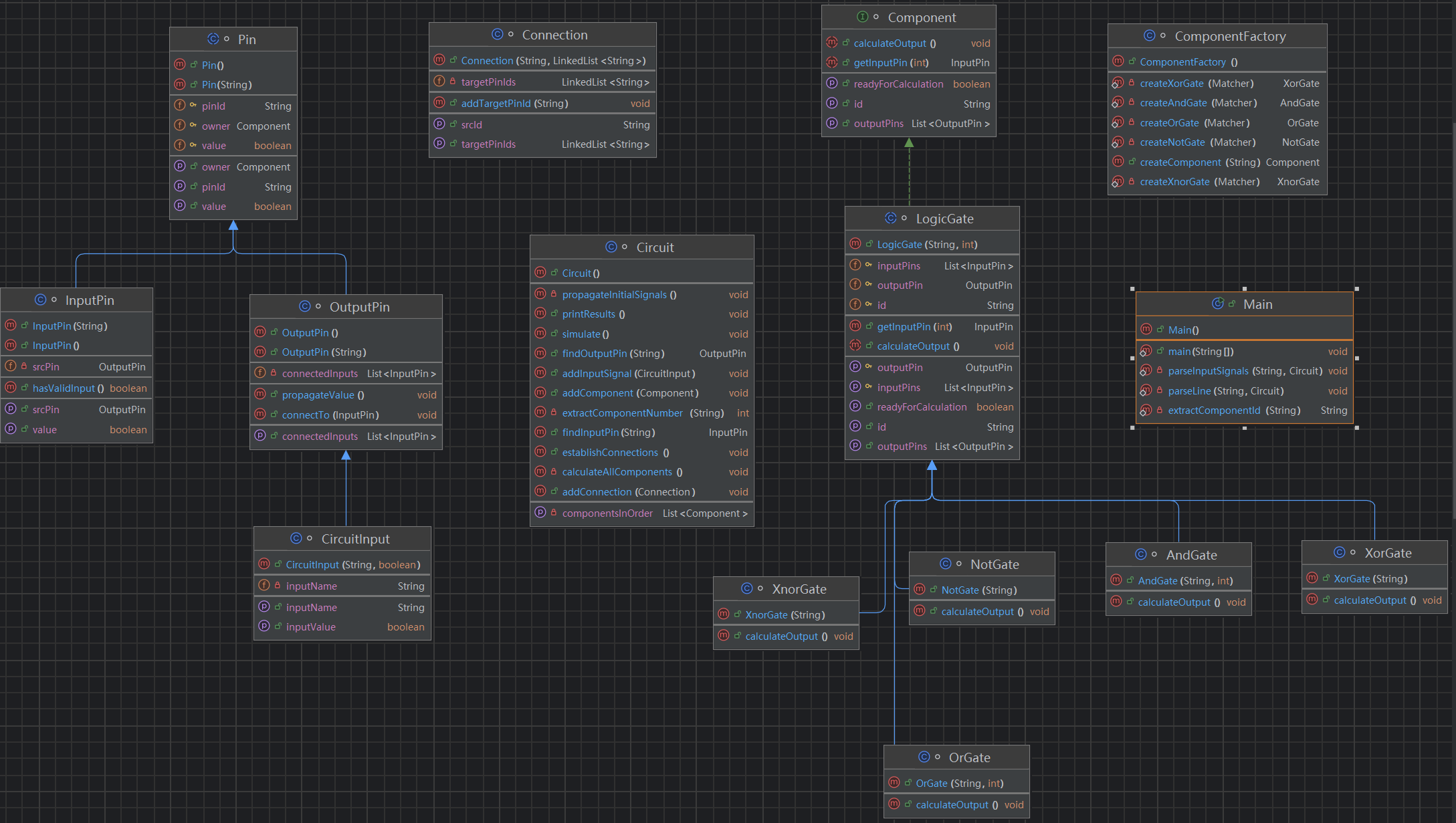
也是把解析输入部分的类放到了主函数里,显得简单一些.
也是吸取之前大作业的经验,尽可能解耦,做到"单一职责".
week1.2 核心思路
整体流程:
main逐行读取输入
->
根据前缀区分INPUT和连接信息[两种格式
->
INPUT行解析为CircuitInput对象添加到电路输入
->
连接行解析为Connection对象并动态创建相关组件
->
所有输入解析完成后调用circuit.simulate()开始模拟
->
simulate()按顺序执行:建立连接->传播初始信号->迭代计算所有组件->输出结果
信号流向的核心机制让我想起了"水往低处流"的原理🤔:
- 引脚连接建立:OutputPin.connectTo()建立与InputPin的双向链接,就像接通水管
- 信号传播:CircuitInput.setInputValue()触发propagateValue(),像源头放水
- 组件计算:LogicGate.calculateOutput()基于输入引脚值计算输出,像水处理器
- 迭代稳定:do-while循环确保信号完全传播,像等待水流稳定
设计巧思:通过Component接口统一所有元件,就像给不同电器都装上标准插头💡,让Circuit可以统一管理。LogicGate抽象类提取公共逻辑,避免了重复代码。
week1.3 SourceMonitor分析报告
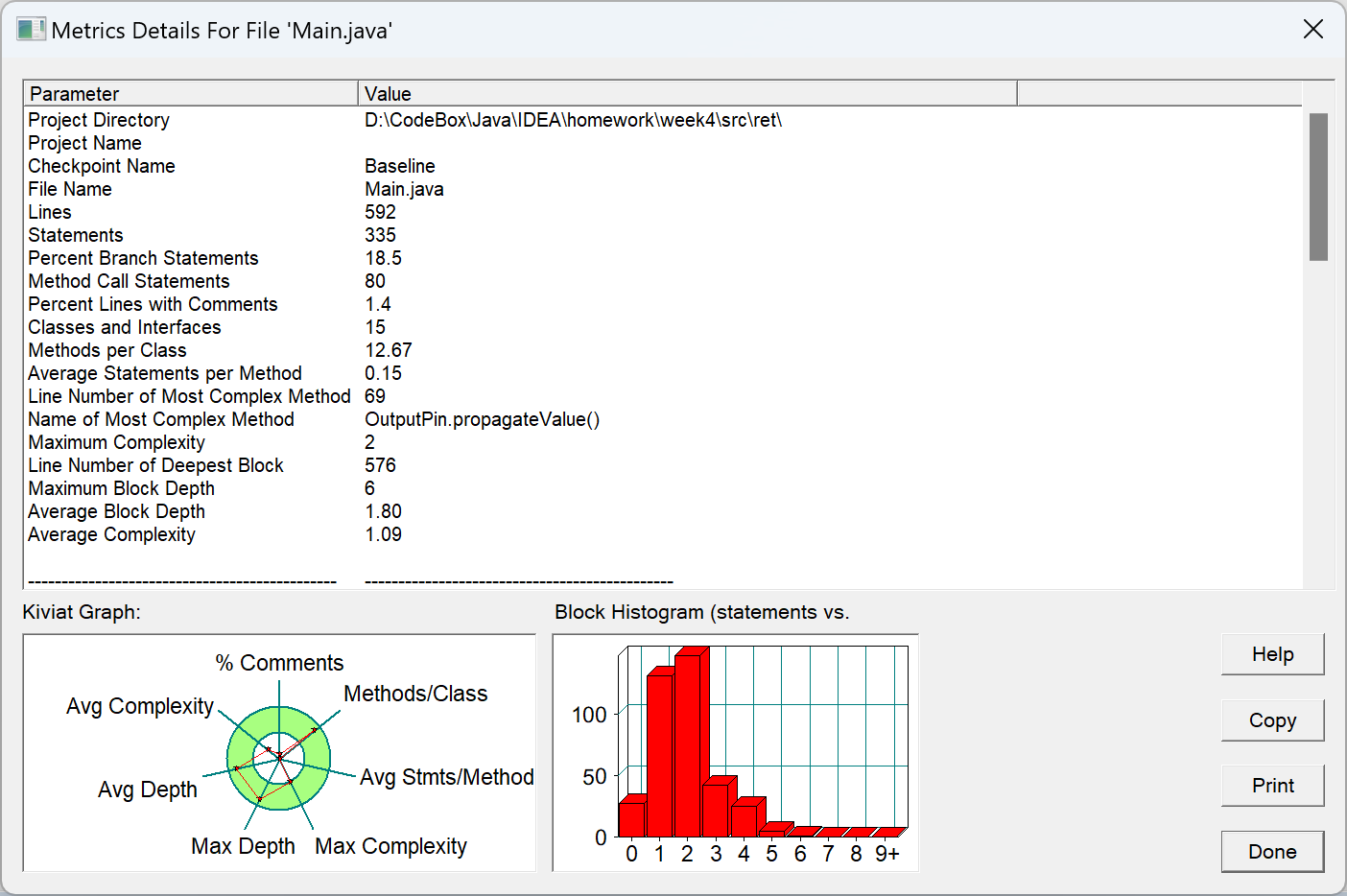
| 指标类别 | 具体数值/信息 |
|---|---|
| 代码行数 | 592 |
| 有效语句数 | 335 |
| 分支百分比 | 18.5% |
| 函数调用语句数 | 80 |
| 注释比例 | 1.4% |
| 类数量 | 15 |
| 方法数/类 | 12.67 |
| 方法平均语句数 | 0.15 |
| 最复杂方法的行号 | 69 |
| 最复杂方法名称 | OutputPin.propagateValue() |
| 最大复杂度 | 2 |
| 最深嵌套行数 | 576 |
| 最大嵌套深度 | 6 |
| 平均嵌套深度 | 1.80 |
| 平均复杂度 | 1.09 |
分析:
-
优势
- 核心逻辑复杂度低(最大复杂度=2、平均复杂度=1.09):核心方法OutputPin.propagateValue()的复杂度仅为2,整体业务逻辑无高复杂度分支/循环嵌套,逻辑本质简单,后续优化、重构的改造成本低。
- 具备模块化拆分意识(类数量=15):未采用“单体类”设计,拆分出15个类体现了对业务模块的初步解耦思路,为后续按职责边界精细化重构奠定了基础。
- 分支逻辑可控(分支百分比=18.5%):代码中条件判断类的分支占比适中,无大量密集的分支嵌套,减少了逻辑分叉带来的理解和调试难度。
-
核心问题
- 注释覆盖严重不足(注释比例=1.4%):几乎无有效注释说明业务逻辑、方法用途或嵌套分支意图,尤其是长达576行的嵌套代码块,后续维护、接手时易误解逻辑,增加改造成本。
- 方法粒度过度细碎(方法平均语句数=0.15):单个方法仅包含极少量语句,存在过度拆分问题,破坏了代码的连贯性,阅读时需频繁跳转方法,降低开发效率。
- 嵌套逻辑冗余(最大嵌套深度=6、最深嵌套行数=576):多层条件/循环嵌套大幅提升了代码阅读和调试难度,难以快速跟踪执行流程,易出现逻辑遗漏或错误。
- 类职责仍不均衡(方法数/类=12.67):类的方法数量均值偏高,说明部分类仍承载了过多职责,未完全实现按业务职责的合理拆分,存在“类内耦合”风险。
好像有点解耦过头了😢
各个类之间的来回调用也使得嵌套逻辑很深😖
但也是方便拓展,后续可以根据需求添加新的组件,而不需要修改现有的代码.😎👍
week1.4 踩坑心得
耦合度这么低,虽然是好处,但具体实现的时候要考虑的很多😢
-
信号传播迭代计算:
究竟是在创建组件时自己传播,还是最后模拟电路时传播呢?最开始以为一次遍历所有组件就能完成计算,忽略了组件间的依赖关系可能导致多轮计算。
这里也是参考了DeepSeek给出的迭代算法才结局问题.
每次计算前保存旧值,计算后比较是否变化,采用 do-while 循环直到所有组件输出稳定:do { changed = false; for (Component component : orderedComponents) { if (component.isReadyForCalculation()) { boolean oldOutput = component.getOutputPins().get(0).getValue(); component.calculateOutput(); boolean newOutput = component.getOutputPins().get(0).getValue(); if (oldOutput != newOutput) { changed = true; } } } iteration++; } while (changed && iteration < maxIterations); -
关于排序
直接用字符串比较 "A(2)1" 和 "A(2)10",结果 "A(2)10" 排在 "A(2)2" 前面。
实际需要一步步提取数字部分进行比较.
也是服了,为自己偷懒买单,找了半天.其实多想一步就可以了😖
week1.5 改进建议
看完SourceMonitor报告后,觉得自己像个代码界的"极端分子"😅——要么过度解耦,要么过度>耦合。针对发现的问题,我觉得可以这样改进:
-
注释是给未来的自己看的:要养成写注释的好习惯,特别是复杂算法和关键决策点。比如迭代计算那部分,不加注释的话,一个月后自己都看不懂😂。
-
方法合并与拆分要找平衡点:像那些只有一两行的方法,可以考虑合并到调用者中,减少跳转。但核心算法还是要保持独立,方便测试。
-
嵌套逻辑扁平化:发现最深嵌套6层时我自己都吓一跳😨!可以用卫语句(guard clauses)提前返回,或者把部分逻辑提取为独立方法。
-
类职责再细化:Circuit类现在像个"大管家"管太多事👨💼,可以考虑拆分成ConnectionManager、CalculationEngine、OutputFormatter等专门类。
-
输入解析可增强:现在Main里的解析函数比较脆弱,可以增加更多校验,为后续的异常处理打基础。
WEEK2
week2.1 类图设计
在上一次的基础上,这次只是增加新类,并修改一些处理逻辑,类图没有很大变化:
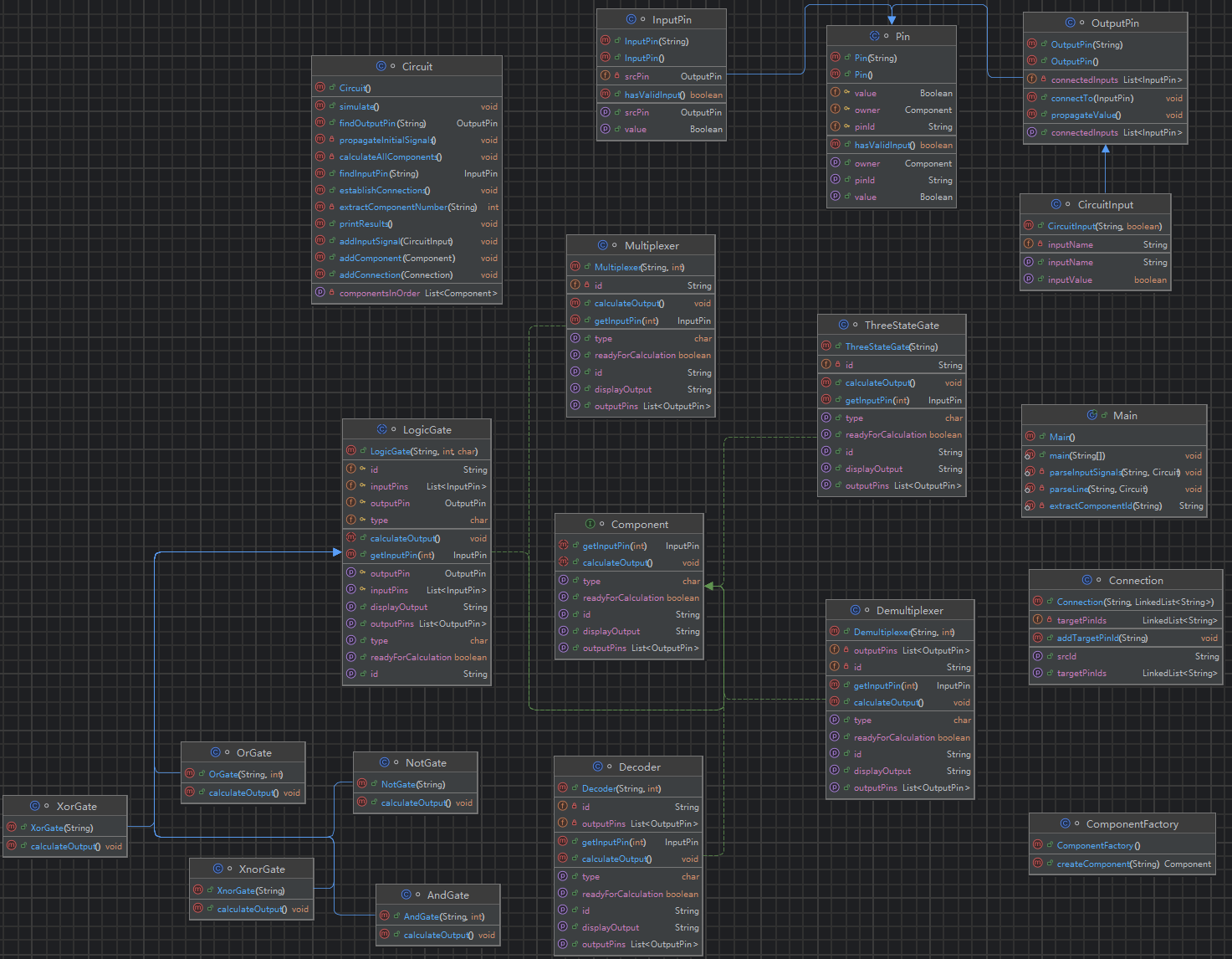
week2.2 核心思路
核心思路在保持原有框架基础上,做了几个关键升级:
-
三态逻辑的引入是最挑战的部分💪:
- 将boolean改为Boolean,支持true/false/null三种状态
- InputPin.getValue()返回null表示无效输入
- OutputPin.propagateValue()传播null值表示高阻态
-
控制引脚的新概念让我重新思考引脚分类🤔:
- 原来只有输入/输出引脚
- 新增控制引脚,如三态门的0号引脚
- 译码器的0-2号引脚也是控制引脚
- 引脚编号规则变得更复杂😕
-
多输出组件的处理需要新策略💡:
- 原来所有组件只有一个输出引脚(编号0)
- 译码器有多个输出引脚(编号从6开始)
- 输出格式也要调整:译码器输出索引,分配器输出模式
-
工厂模式升级就像开了分店🏬:
- 正则表达式模式从5个增加到8个
- 支持更复杂的组件标识符格式
- 创建逻辑要考虑更多边界情况
整体流程依然是:解析输入->建立连接->传播信号->迭代计算->输出结果,但每个环节都更复杂了。
就像从"单人单车"升级到了"货运列车"🚂,能承载更多,但调度也更复杂。😖
week2.3 SourceMonitor分析报告
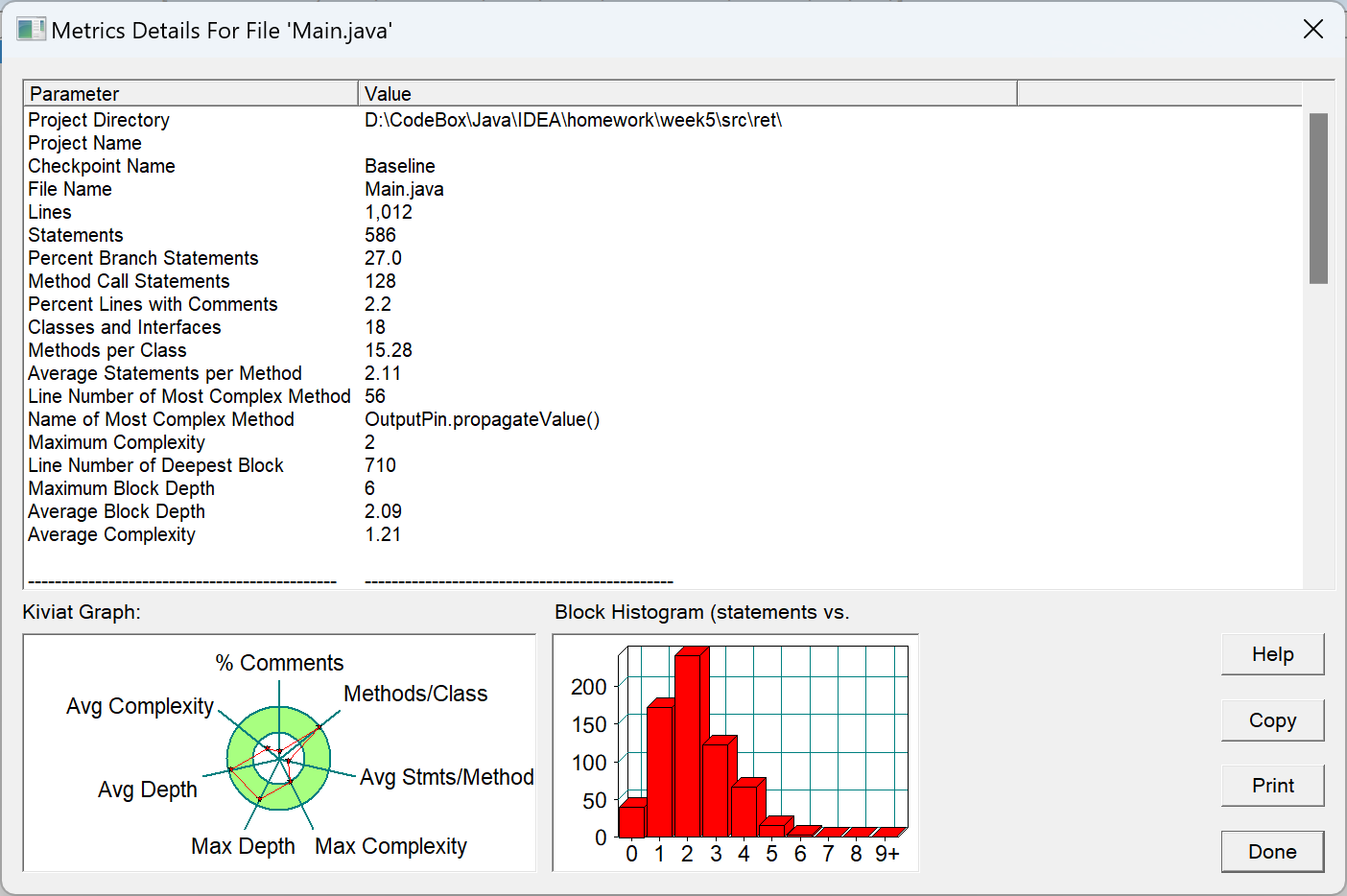
| 指标类别 | 具体数值/信息 |
|---|---|
| 代码行数 | 1,012 |
| 有效语句数 | 586 |
| 分支百分比 | 27.0% |
| 函数调用语句数 | 128 |
| 注释比例 | 2.2% |
| 类数量 | 18 |
| 方法数/类 | 15.28 |
| 方法平均语句数 | 2.11 |
| 最复杂方法的行号 | 56 |
| 最复杂方法名称 | OutputPin.propagateValue() |
| 最大复杂度 | 2 |
| 最深嵌套行数 | 710 |
| 最大嵌套深度 | 6 |
| 平均嵌套深度 | 2.09 |
| 平均复杂度 | 1.21 |
分析:
-
优势
- 核心逻辑复杂度可控(最大复杂度=2、平均复杂度=1.21):核心方法
OutputPin.propagateValue()的复杂度仅为2,整体业务逻辑无高复杂度分支/循环,逻辑本质简单,后续优化、重构的改造成本较低。 - 模块化拆分程度提升(类数量=18):相比之前进一步拆分了业务模块,体现了更明确的解耦思路,为按职责边界精细化维护奠定了基础。
- 方法交互性较好(函数调用语句数=128):方法间调用较为活跃,避免了代码的孤立冗余,一定程度上提升了逻辑的联动性。
- 核心逻辑复杂度可控(最大复杂度=2、平均复杂度=1.21):核心方法
-
核心问题
- 注释覆盖仍严重不足(注释比例=2.2%):几乎无有效注释说明业务逻辑,尤其是长达710行的嵌套代码块(最大嵌套深度=6),后续维护、接手时易误解逻辑,增加改造成本。
- 部分类职责偏多(方法数/类=15.28):单个类平均承载超15个方法,部分类的职责仍过度集中,存在“类内耦合”风险,修改时易影响多个功能模块。
- 嵌套逻辑冗余(最大嵌套深度=6、最深嵌套行数=710):多层条件/循环嵌套大幅提升了代码阅读和调试难度,难以快速跟踪执行流程,易出现逻辑遗漏或错误。
本次代码指标反映出「核心逻辑简单、模块化拆分有进步,但注释、类职责、嵌套结构仍需优化」的特征,重点需解决注释缺失与类职责集中的问题。
week2.4 踩坑心得
第二次作业踩的坑比第一次深多了🤕,简直是在坑里建了个地下停车场🅿️!
-
三态逻辑的null值处理让我头疼了一整天🤯:
开始以为把boolean改成Boolean就行了
实际发现要修改getValue()、setValue()、hasValidInput()等几十个地方
最坑的是:if(value)要改成if(value != null && value),不然就是NullPointerException大礼包📦 -
控制引脚的编号规则像个迷宫:
三态门:0控制、1输入、2输出
译码器:0-2控制、3-5输入、6-13输出
多路选择器:0-1控制、2-5输入、6输出
每个组件都要查文档确认编号规则,差点写了个映射表📃 -
特殊输出格式考验字符串处理能力🖊️:
译码器输出M(3)1:3
分配器输出F(2)1:--0-
原来简单的组件ID-0:0/1不够用了
得为每个组件设计getDisplayOutput()方法 -
工厂模式的扩展还算顺利😌:
感谢第一次作业的设计,新增组件只需:加正则模式、加创建方法
但正则表达式越来越复杂,快成"天书"了📜
特别是X(?:\((\d+)\))?(\d+)这种,自己写的,三天后都看不懂
最大的教训:设计要为变化预留空间。第一次作业的良好抽象,让第二次作业的扩展相对顺利。但也有一些地方没考虑周全,比如引脚编号规则,如果一开始就设计成可配置的,就不会这么痛苦了。👍
week2.5 改进建议
经历了两次作业的"洗礼",我觉得这个数字电路模拟程序还有不少改进空间🚧
- 配置化引脚规则:硬编码的引脚编号规则是维护的噩梦:nightmare:。可以考虑用配置文件或枚举类定义每个组件的引脚布局。
- 更智能的连接验证:现在建立连接时基本不验证,可以增加:引脚类型匹配、不重复连接、无回路检测等。
- 性能优化:迭代计算的最大迭代次数现在是硬编码的1000次,可以考虑更智能的收敛判断。
- 测试覆盖:手动测试太痛苦了😱!应该建立单元测试框架,特别是边界情况和异常场景。
3.总结
总算写到这了😄📝
两次数字电路模拟作业的迭代,本质是从"基础逻辑门"到"复杂组合电路",从"二值逻辑"到"三态逻辑"的完整实践。每一步都涉及到设计模式的运用、架构的扩展和细节的打磨,让我对"面向对象设计"、"迭代开发"和"可扩展架构"有了更深刻的理解。
3.1 这些坑,踩了才懂
-
"设计模式不是摆设,是实用工具箱"
第一次作业时,看着工厂模式、模板方法模式这些概念觉得"用不用都行",结果硬着头皮把所有创建逻辑塞在一起,代码看着就头疼。第二次作业被迫用上工厂模式才发现——好设计能自动解决问题!新增9种组件?加几个正则表达式和创建方法就行,完全不用改核心逻辑。这才明白,设计模式不是"考试知识点",是"避免重复劳动的利器"。 -
"过度设计也是坑,平衡才是王道"
追求"极致解耦"的结果就是:15个类之间来回调用,最深嵌套6层!SourceMonitor报告一看,平均每个方法只有0.15条语句,跳来跳去像玩"代码跳房子"😵。第二次稍微收敛了点,但问题还在。这才体会到:设计要在"过度简单"和"过度复杂"之间找平衡,就像走钢丝,太左太右都会掉下去。 -
"三态逻辑不是1+2=3那么简单"
以为把boolean改成Boolean就万事大吉,结果发现null值像病毒一样需要到处处理:if判断、空值传播、输出格式...连最简单的if(value)都得改成if(value != null && value)。最痛苦的是调试时看到一片null却不知道从哪里开始漏的。架构的小改动,需要代码的大调整,这个教训值了。 -
"正则表达式是双刃剑"
第一次用正则解析组件ID时还觉得挺酷,第二次看到X(?:\\((\\d+)\\))?(\\d+)这种"天书"时,内心是崩溃的。更崩溃的是,一周后自己都看不懂自己写的正则了。复杂的正则表达式是"写给机器的情书",人类看不懂,但机器很享受——然后维护的人就倒霉了。 -
"AI是助手,不是设计师"
遇到问题时问AI(DeepSeek),确实能快速找到语法错误或给出实现思路。但让AI设计整个架构?算了吧,它会把简单问题复杂化,或者按照"教科书式"的方式给出不切实际的方案。AI适合解决"怎么实现",不适合解决"为什么这样设计"。核心算法和架构设计,还得靠人脑。 -
代码要早点开始写
第二次的代码星期六晚上才开动,导致后来测试根本来不及,好在最后借了两个测试用例,才知道代码不足在哪。下次不要拖沓太久。
3.2 "大作业"还多,慢慢来
虽然两次作业有进步,但还有很多"优化空间":
-
注释要"说人话":1.4%和2.2%的注释比例,基本等于没注释。复杂算法(比如迭代传播)不加注释,一个月后自己都看不懂在干嘛。好注释不是"每行都写",而是"关键逻辑说清楚",比如"为什么要迭代1000次而不是100次"。
-
嵌套要"扁平化":最大嵌套深度6层,看着就头晕。可以用卫语句提前返回,或者提取独立方法,把"代码金字塔"变成"代码平房"。
-
测试要"自动化":手动测试太痛苦了,特别是译码器、分配器这种多输出组件。应该建立单元测试框架,把各种边界情况都覆盖到。
-
配置要"灵活化":硬编码的引脚编号规则(三态门0控制1输入2输出)是维护的噩梦。改成配置文件或者枚举类定义,下次加新组件就不用翻代码了。
OK了,这次的Blog就到这!
感谢阅读,我们下次作业再见!
😉❤️😆

 浙公网安备 33010602011771号
浙公网安备 33010602011771号