第一次个人编程作业
github链接:https://github.com/Anquaner/Anquaner
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 论文查重程序设计+PSP表格使用+性能分析和改进+单元测试+git管理代码 |
1. PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 180 | 300 |
| Estimate | 估计这个任务需要多少时间 | 120 | 60 |
| Development | 开发 | 480 | 360 |
| Analysis | 需求分析 (包括学习新技术) | 180 | 300 |
| Design Spec | 生成设计文档 | 180 | 150 |
| Design Review | 设计复审 | 180 | 150 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 100 | 70 |
| Design | 具体设计 | 300 | 350 |
| Coding | 具体编码 | 200 | 250 |
| Code Review | 代码复审 | 150 | 180 |
| Test | 测试(自我测试,修改代码,提交修改) | 250 | 300 |
| Reporting | 报告 | 200 | 180 |
| Test Repor | 测试报告 | 100 | 120 |
| Size Measurement | 计算工作量 | 100 | 80 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 150 | 200 |
| 合计 | 2870 | 3050 |
2. 模块接口的设计与实现过程
-
算法设计
基于Levenshtein Distance算法计算文本相似度
Levenshtein Distance是一个度量两个字符序列之间差异的字符串度量标准,两个单词之间的Levenshtein Distance是将一个单词转换为另一个单词所需的单字符编辑(插入、删除或替换)的最小数量。Levenshtein Distance是1965年由苏联数学家Vladimir Levenshtein发明的。Levenshtein Distance也被称为编辑距离(Edit Distance)。
算法详情参考链接
-
类的设计及类成员函数设计
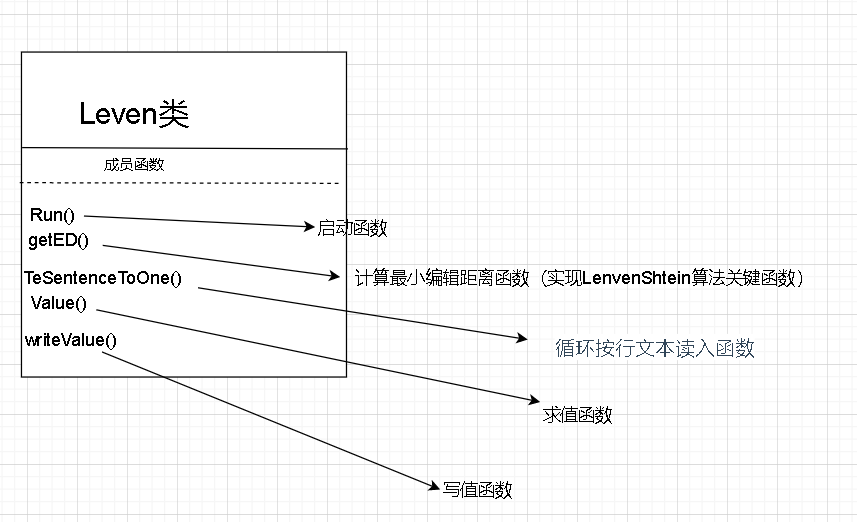
-
程序流程图
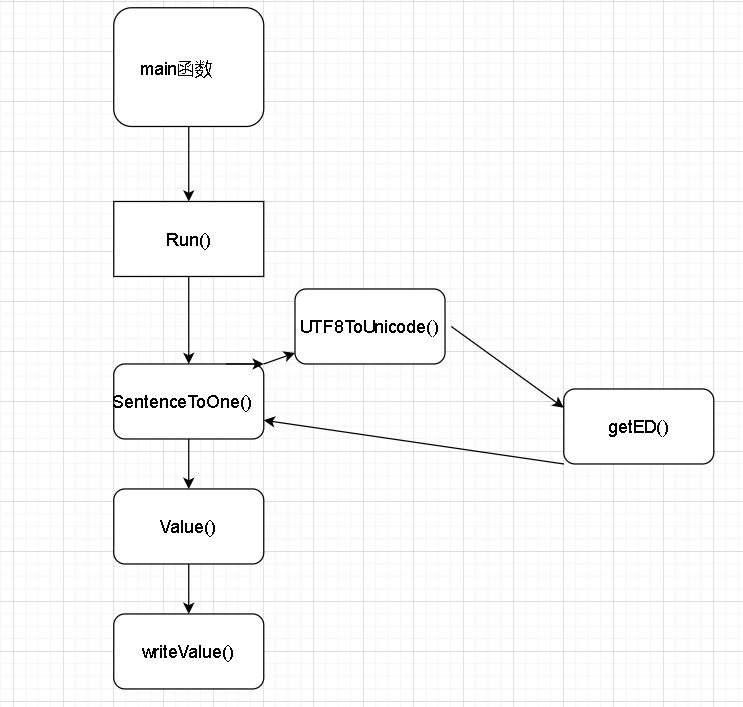
3.模块接口部分的性能改进
-
改进前
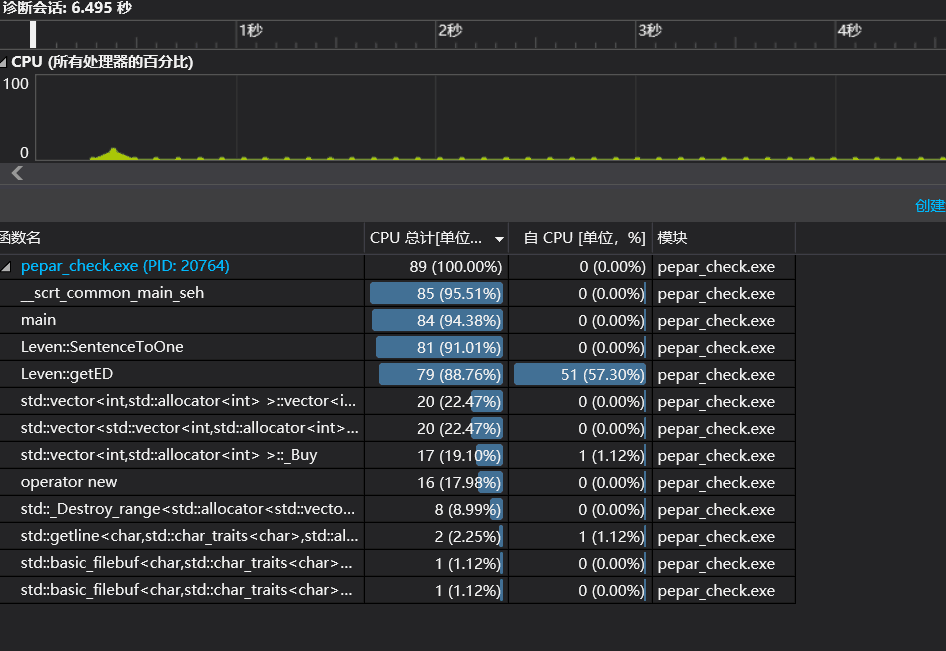
-
分析
由性能图分析可得,由于getED()函数占用的大量cpu资源。这是因为getED()函数读取文件时处理的是utf-8编码。而utf-8编码的可变长,一会儿一个字符串是占用一个字节,一会儿一个字符串占用两个字节,还有的占用三个及以上的字节,导致在内存中或者程序中变得不好琢磨。unicode编码虽然占用内存空间,但是在编程过程中或者在内存处理的时候会比utf-8编码更为简单,因为它始终保持一样的长度,一样的长度对于内存和代码来说,它的处理就会变得更加简单。所以utf-8编码在做网络传输和文件保存的时候,将unicode编码转换成utf-8编码,才能更好的发挥其作用;当从
文件中读取数据到内存中的时候,将utf-8编码转换为unicode编码。
新增函数UTF8ToUnicode()实现utf-8编码转换为unicode编码。

-
改进后
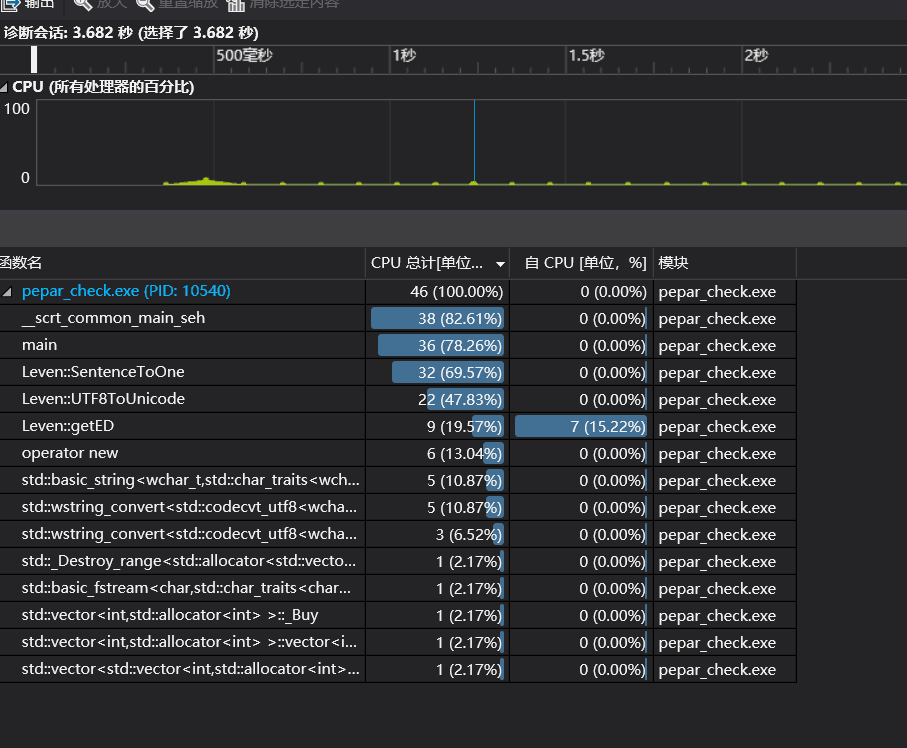
4.模块部分单元测试展示
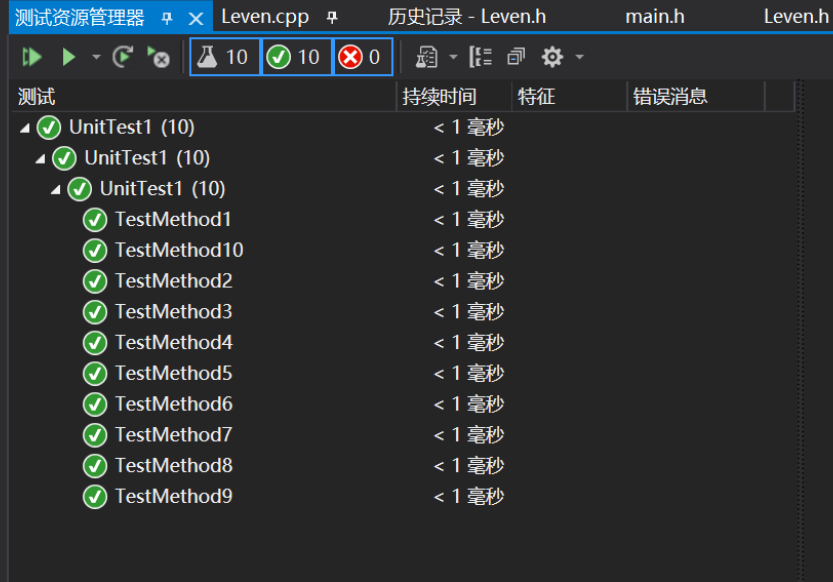
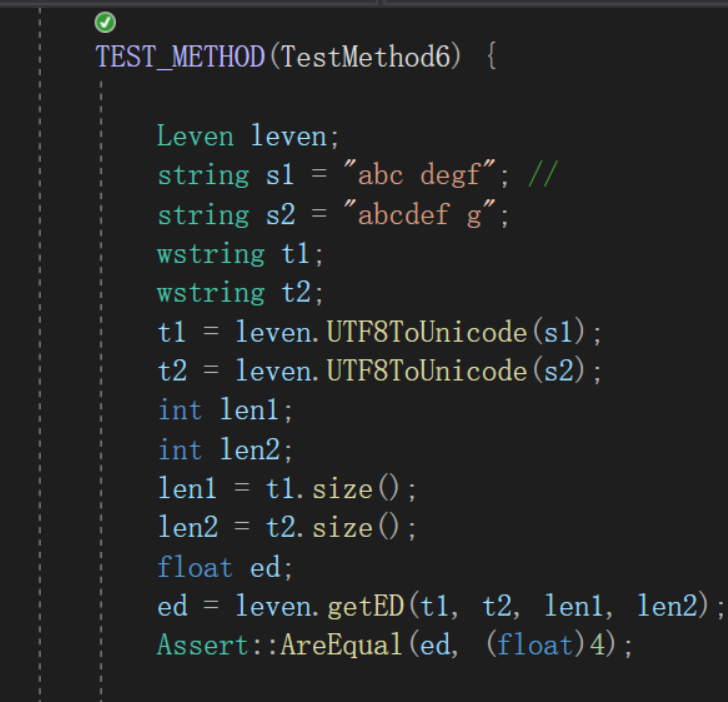
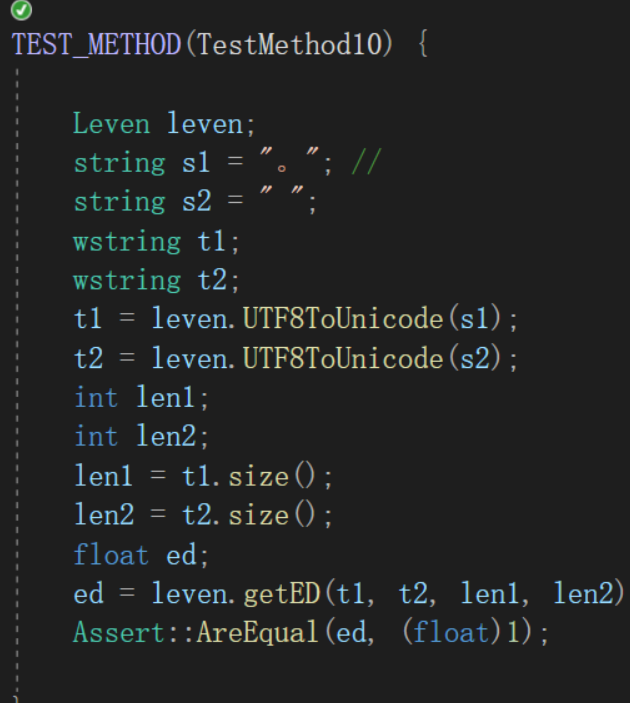
- 测试最小编辑距离
- 测试命令行参数


- 测试UTF8ToUnicode函数

- 文本查重运行结果
![]()
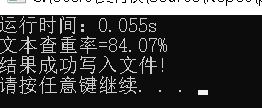
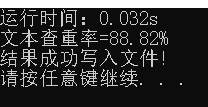
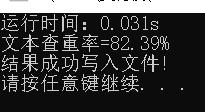

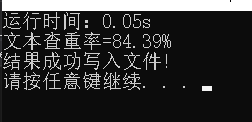
5.模块部分异常处理说明
- 参数个数和文件输入路径异常处理

- 捕捉库函数异常
![]()

6.个人总结
本来此次我是想用simhash算法,苦于C++标准库没有自然语言处理,而simhash算法第一步就是分词,上网查了下分词工具找到了结巴分词,但是是python库,我尝试了调用pythonjieba库,但是还是没有成功.后面发现github上有人实现了C++ jeiba.hpp,但是是gcc版本下的;到了VS2017报了好多错,因为能力有限就放弃了simhash算法。后面就选择了levenshetein算法。
我觉得这次项目收获最大的是学PSP表格了,单元测试。以前都没干过,也算一个新技能。
还有更加熟悉了VS这个开发工具。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号