

AI框架---LangChain
概述
what


为什么要用LangChain?

LangChain的核心
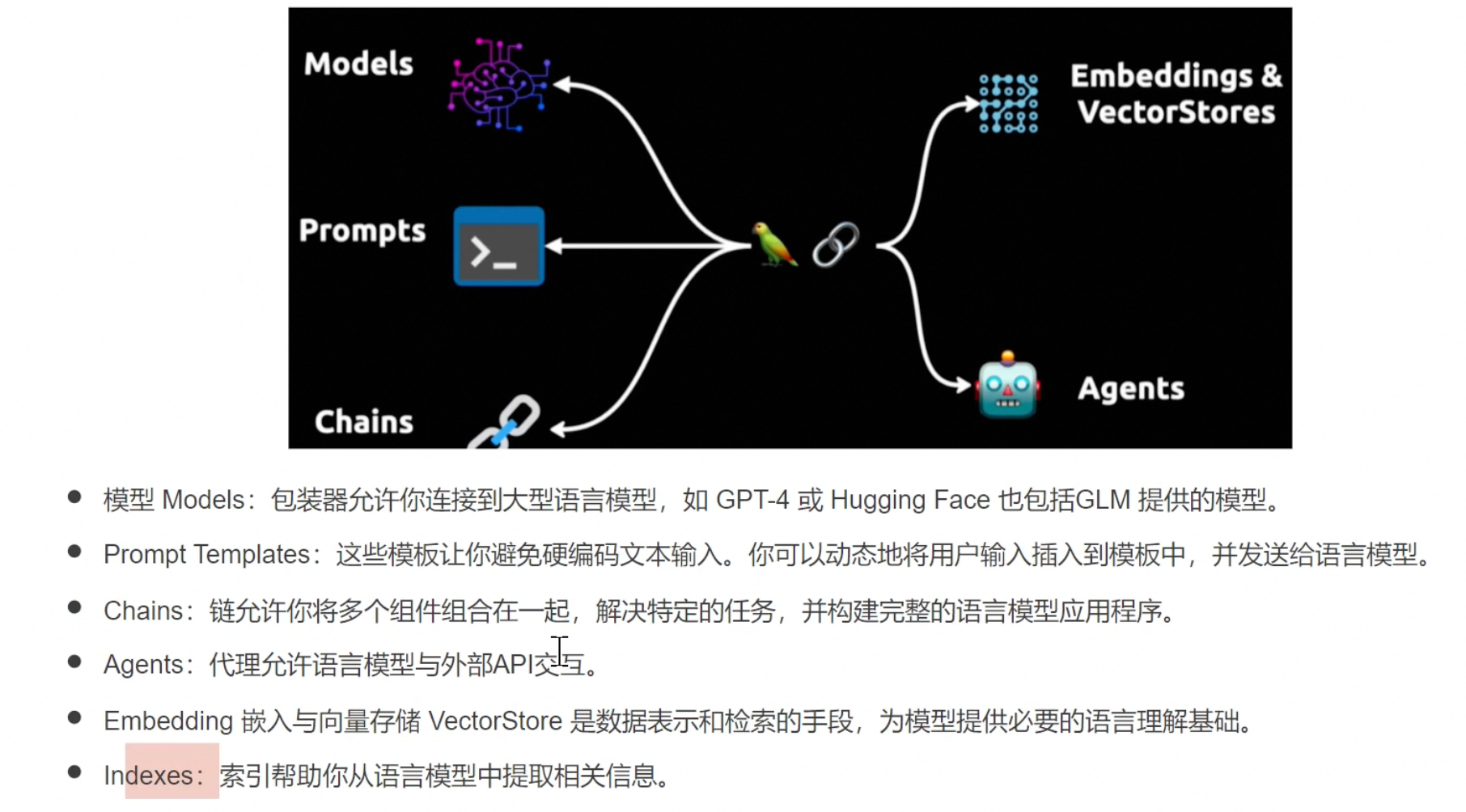
LangChain底层原理
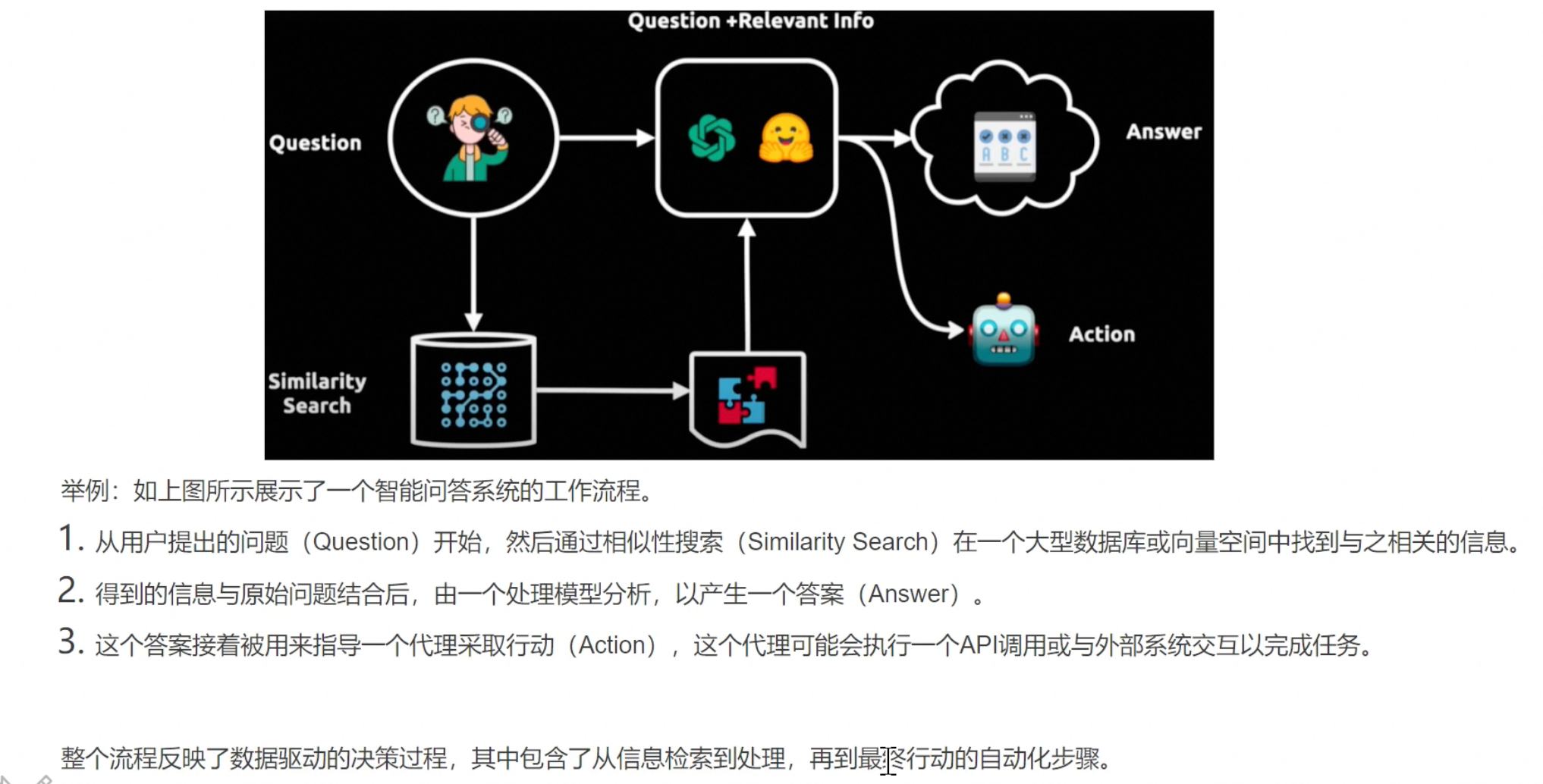
LangChain应用场景

LangChain实战操作
安装
https://www.langchain.com/
监控工具:LangSmish
https://www.smith.langchain.com/settings
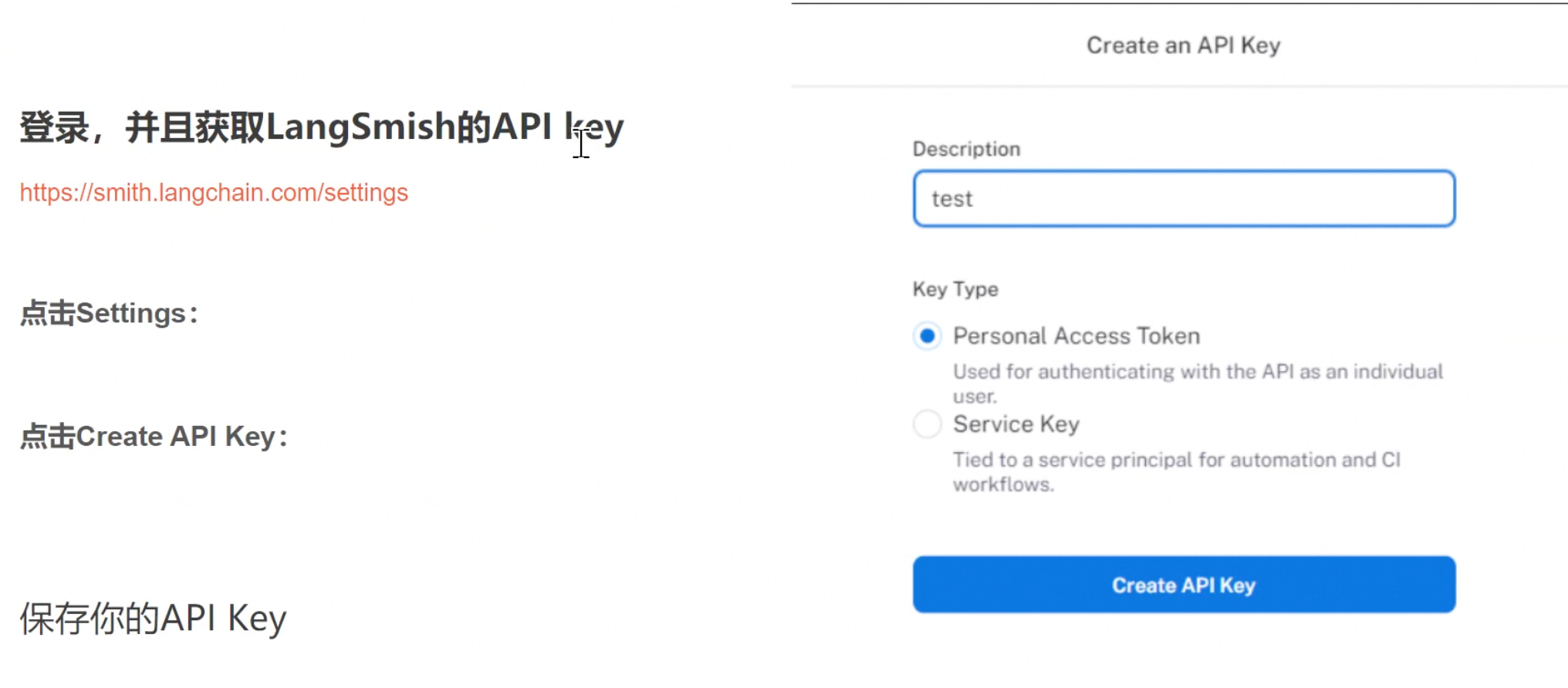
LangSmish是什么?

实现LLM应用程序

TongYiDemo
import os
from fastapi import FastAPI
from langchain_community.llms import Tongyi
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langserve import add_routes
#langSmith
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "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"
#通义千问apikey
os.environ["DASHSCOPE_API_KEY"] = "sk-43bfa6b513dd4164ad2f50b8b34df5b5"
#定义大模型
model = Tongyi(model_name="qwen-turbo", temperature=0.5)
#解析器
parser = StrOutputParser()
#提示词模版
prompt_template = ChatPromptTemplate([
('system', '请将下面的语句翻译成{language}'),
('user', '{text} ')
])
#链
chain = prompt_template | model | parser
#打印结果
print(chain.invoke({'language': 'English', 'text':'我下午还有一节课,不能去玩了。 '}))
#将程序部署成API服务
app = FastAPI(title='我的langchain翻译器', version='1.0', desciption='可以翻译成任何语言')
add_routes(
app,
chain,
path="/chainDemo",
)
if __name__ == '__main__':
import uvicorn
uvicorn.run(app, host="localhost", port=8000)
Client
from langserve import RemoteRunnable
if __name__ == '__main__':
client = RemoteRunnable('http://localhost:8000/chainDemo/')
print(client.invoke({'language': 'japanese', 'text': '滚'}))
http调用
POST + http://localhost:8000/chainDemo/invoke JSON协议
构建聊天机器人

import os
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_community.llms import Tongyi
from langchain_core.messages import HumanMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnableWithMessageHistory
#langSmith
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "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"
# os.environ["LANGCHAIN_PROJECT"] = "langchainchatdemo"
#通义千问apikey
os.environ["DASHSCOPE_API_KEY"] = "sk-43bfa6b513dd4164ad2f50b8b34df5b5"
#定义大模型
model = Tongyi(model_name="qwen-turbo", temperature=0.5)
#提示词模版
prompt_template = ChatPromptTemplate([
('system', '你是一个乐于助人的助手,用{language}尽你所能回答所有的问题'),
MessagesPlaceholder(variable_name='my_msg')
])
#链
chain = prompt_template | model
#存储聊天记录
store = {} #所有用户的聊天记录,key:sessionId
#定义函数:根据sessionId获取用户的聊天记录
def get_history_by_session_id(session_id: str):
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
do_message = RunnableWithMessageHistory(
chain,
get_history_by_session_id,
input_messages_key='my_msg' #每次聊天发送的msg的key
)
#配置,定义sessionId
config = {'configurable': {'session_id': 'zs123'}}
#第一轮对话
resp = do_message.invoke(
{
'my_msg': [HumanMessage(content='你好,我是apy')],
'language': '中文'
},
config=config
)
print(resp)
#第二轮对话
resp2 = do_message.invoke(
{
'my_msg': [HumanMessage(content='我的名字是什么?')],
'language': '中文'
},
config=config
)
print(resp2)
#第三轮对话,流式对话
for resp in do_message.invoke({'my_msg': [HumanMessage(content='给我讲个笑话')], 'language': 'English'}, config=config):
print(resp, end='-') #每个resp都是一个token
#对话记录
print('--------------')
print(store)
构建向量数据库和检索器

import os
from langchain_community.llms import Tongyi
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
#langSmith
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "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"
#通义千问apikey
os.environ["DASHSCOPE_API_KEY"] = "sk-43bfa6b513dd4164ad2f50b8b34df5b5"
#定义大模型
model = Tongyi(model_name="qwen-turbo", temperature=0.5)
#数据准备
documents = [
Document(
page_content="狗是伟大的伴侣,以忠诚和友好文明",
metadata={"source": "哺乳动物宠物文档"}
),
Document(
page_content="猫是独立空间的宠物",
metadata={"source": "哺乳动物宠物文档"}
)
]
#实例化一个向量数据库空间
vector_store = Chroma.from_documents(documents, DashScopeEmbeddings(model="text-embedding-v1"))
#相似度查询:分数越低越相似
# print(vector_store.similarity_search_with_score('咔菲猫'))
#检索器,bind(k=1)返回相似度最高的一个
retriever = RunnableLambda(vector_store.similarity_search).bind(k=1)
# print(retriever.batch(['咖菲猫', '鲨鱼']))
#提示模版
message = """
使用提供的上下文回答这个问题:
{question}
上下文:
{context}
"""
prompt_template = ChatPromptTemplate.from_messages([('human', message)])
chain = {'question': RunnablePassthrough(), 'context': retriever} | prompt_template | model
resp = chain.invoke('请介绍一下猫')
print(resp)
构建代理Agent

获得tavily api key
https://docs.tavily.com/welcome


 浙公网安备 33010602011771号
浙公网安备 33010602011771号