

1.交叉验证的目的
在机器学习的相关研究中,如果是有监督的算法,需要将原始数据集分为训练集和测试集两个集合。训练集中的数据带有标签,用这些数据来训练出一个模型,告诉机器什么样的数据可以分成哪一类,然后用这个模型来预测测试集中数据的标签。然后用预测得到的标签跟真实的标签作比对,就可以得到这个模型的预测准确率,其实是考察这个模型的generalization ability(泛化能力),即,从训练集中总结出来的规律能不能用到别的数据上去。
那么,怎样分训练集和测试集呢?需要考虑两个问题:
1. 训练集中的数据要足够多,一般要大于原始数据集的一般,否则总结出来的规律太小众
2. 两组集合必须是原始集合的均匀取样,否则比如说,训练集选择都是1类数据,测试集都是2类数据,训练之后模型知道1类数据的特点,用它来分别2类数据,这好难。。。
于是,cross validation的目的就是:科学地统计训练模型的泛化能力。
2.交叉验证的分类
简单交叉验证、K-折交叉验证、留一交叉验证
2.1 简单交叉验证
将原始数据随机分为两组,一组做为训练集,一组做为验证集,利用训练集训练分类器,然后利用验证集验证模型,记录最后的分类准确率为此分类器的性能指标。
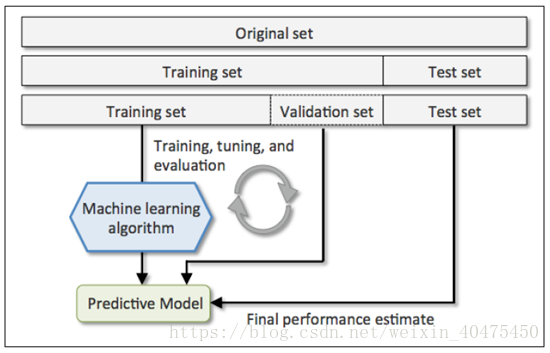
优点:
处理简单,只需随机把原始数据分为两组即可
缺点:
但没有达到交叉的思想,由于是随机的将原始数据分组,所以最后验证集分类准确率的高低与原始数据的分组有很大的关系,得到的结果并不具有说服性。
2.2 K-折交叉验证
将原始数据分成K组(一般是均分),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型,用这K个模型最终的验证集的分类准确率的平均数作为此K-CV下分类器的性能指标。K一般大于等于2,实际操作时一般从3开始取,只有在原始数据集合数据量小的时候才会尝试取2。
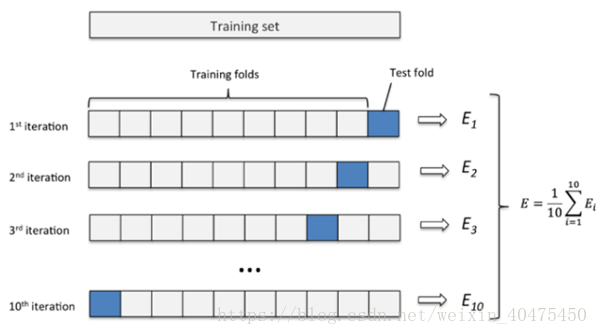
应用最多,K-CV可以有效的避免过拟合与欠拟合的发生,最后得到的结果也比较具有说服性。
Eg:十折交叉验证
1. 将数据集分成十份,轮流将其中9份作为训练数据,1份作为测试数据,进行试验。每次试验都会得出相应的正确率。
2. 10次的结果的正确率的平均值作为对算法精度的估计,一般还需要进行多次10折交叉验证(例如10次10折交叉验证),再求其均值,作为对算法准确性的估计
此外:
(1)多次 k 折交叉验证再求均值,例如:10 次10 折交叉验证,以求更精确一点。
(2)划分时有多种方法,例如对非平衡数据可以用分层采样,就是在每一份子集中都保持和原始数据集相同的类别比例。
(3)模型训练过程的所有步骤,包括模型选择,特征选择等都是在单个折叠 fold 中独立执行的。
2.3 留一交叉验证(Leave-One-Out Cross Validation记为LOO-CV)
在数据缺乏的情况下使用,如果设原始数据有N个样本,那么LOO-CV就是N-CV,即每个样本单独作为验证集,其余的N-1个样本作为训练集,故LOO-CV会得到N个模型,用这N个模型最终的验证集的分类准确率的平均数作为此下LOO-CV分类器的性能指标。
优点:
(1)每一回合中几乎所有的样本皆用于训练模型,因此最接近原始样本的分布,这样评估所得的结果比较可靠。
(2)实验过程中没有随机因素会影响实验数据,确保实验过程是可以被复制的。
缺点:
计算成本高,需要建立的模型数量与原始数据样本数量相同。当数据集较大时几乎不能使用。
Data = rand(9,3);%创建维度为9×3的随机矩阵样本
indices = crossvalind('Kfold', 9, 3);%将数据样本随机分割为3部分
for i = 1:3 %循环3次,分别取出第i部分作为测试样本,其余两部分作为训练样本
test = (indices == i);
train = ~test;
trainData = Data(train, :);
testData = Data(test, :);
end
程序解读:1、创建9X3的矩阵
2、把矩阵按将9行数据分成3个类
3、拿出每一类的数据拿出来进行验证
例如,最后运行的是第三类,可以看到分类中,1,5,9行为第三类数据,原始数据中的1,5,9行的数据为test_trian (检验数据),剩下的数据为测试数据。test对应的测试集数据逻辑值为1,train对应的训练集数据逻辑值为1。
函数解释:Indices = crossvalind('Kfold', N, K)
1、参数'Kfold'表明为了K折十字交叉验证,把数据集N随机分成平均的(或近似评价的)K份,Indices中为每个样本所属部分的索引(从1到K)
2、因为是随机分,因此重复调用会产生不同分法。
3、在K折十字交叉验证中,K-1份被用做训练,剩下的1份用来测试,这个过程被重复K次。
3.3 留M交叉验证
load carbig x = Displacement;
y = Acceleration;
函数解释:
[Train, Test] = crossvalind('LeaveMOut', N, M), where M is an integer, returns logical index vectors for cross-validation ofN observations by randomly selectingM of the observations to hold out for the evaluation set.M
defaults to1 when omitted. Using 'LeaveMOut' cross-validation within a loop does not guarantee disjointed evaluation sets. To guarantee disjointed evaluation sets, use'Kfold' instead.
M是整数,返回交叉索引逻辑索引向量,其中N个观测值,从N个观测值中随机选取M个观测值保留作为验证集,其余作为训练集。省略时,M默认为1,即留一法交叉验证。
在一个循环中使用LeaveMOut交叉验证不保证不连贯的验证集.为保证非连贯的验证集,使用K-fold方法替换。
参考文献:
[1] https://blog.csdn.net/weixin_40475450/article/details/80578943
[2] https://blog.csdn.net/whucv/article/details/8959460?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~all~first_rank_v2~rank_v25-4-8959460.nonecase&utm_term=matlab%E4%BA%A4%E5%8F%89%E9%AA%8C%E8%AF%81%E6%95%B0%E6%8D%AE%E9%9B%86%E7%9A%84%E6%96%B9%E6%B3%95
[3] https://ww2.mathworks.cn/help/bioinfo/ref/crossvalind.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号