

PyTorch 循环神经网络(RNN)
循环神经网络(Recurrent Neural Networks, RNN)是一类神经网络架构,专门用于处理序列数据,能够捕捉时间序列或有序数据的动态信息,能够处理序列数据,如文本、时间序列或音频。
RNN 在自然语言处理(NLP)、语音识别、时间序列预测等任务中有着广泛的应用。
在 RNN 中,数据不仅沿着网络层级流动,还会在每个时间步骤上传播到当前的隐层状态,从而将之前的信息传递到下一个时间步骤。
隐状态(Hidden State): RNN 通过隐状态来记住序列中的信息。
隐状态是通过上一时间步的隐状态和当前输入共同计算得到的。
公式:

- ht:当前时刻的隐状态。
- ht-1:前一时刻的隐状态。
- Xt:当前时刻的输入。
- Whh、Wxh:权重矩阵。
- b:偏置项。
- f:激活函数(如 Tanh 或 ReLU)。
输出(Output): RNN 的输出不仅依赖当前的输入,还依赖于隐状态的历史信息。

- yt:在时间步 t 的输出向量(可选,取决于具体任务)。
- Why:是隐藏状态到输出的权重矩阵。。
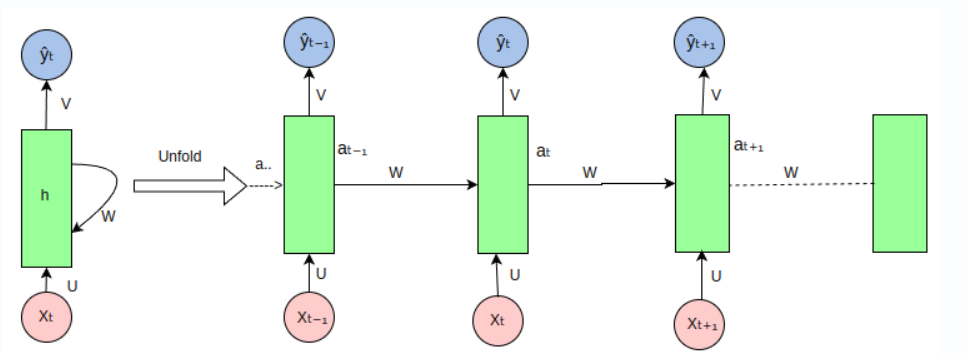
循环神经网络(RNN)在处理序列数据时的展开(unfold)视图如下:
import torch import torch.nn as nn import torch.optim as optim import matplotlib.pyplot as plt import numpy as np # 数据集:字符序列预测(Hello -> Elloh) char_set = list("hello") char_to_idx = {c: i for i, c in enumerate(char_set)} idx_to_char = {i: c for i, c in enumerate(char_set)} # 数据准备 input_str = "hello" target_str = "elloh" input_data = [char_to_idx[c] for c in input_str] target_data = [char_to_idx[c] for c in target_str] # 转换为独热编码 input_one_hot = np.eye(len(char_set))[input_data] # 转换为 PyTorch Tensor inputs = torch.tensor(input_one_hot, dtype=torch.float32) targets = torch.tensor(target_data, dtype=torch.long) # 模型超参数 input_size = len(char_set) hidden_size = 8 output_size = len(char_set) num_epochs = 200 learning_rate = 0.1 # 定义 RNN 模型 class RNNModel(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(RNNModel, self).__init__() self.rnn = nn.RNN(input_size, hidden_size, batch_first=True) self.fc = nn.Linear(hidden_size, output_size) def forward(self, x, hidden): out, hidden = self.rnn(x, hidden) out = self.fc(out) # 应用全连接层 return out, hidden model = RNNModel(input_size, hidden_size, output_size) # 定义损失函数和优化器 criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=learning_rate) # 训练 RNN losses = [] hidden = None # 初始隐藏状态为 None for epoch in range(num_epochs): optimizer.zero_grad() # 前向传播 outputs, hidden = model(inputs.unsqueeze(0), hidden) hidden = hidden.detach() # 防止梯度爆炸 # 计算损失 loss = criterion(outputs.view(-1, output_size), targets) loss.backward() optimizer.step() losses.append(loss.item()) if (epoch + 1) % 20 == 0: print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}") # 测试 RNN with torch.no_grad(): test_hidden = None test_output, _ = model(inputs.unsqueeze(0), test_hidden) predicted = torch.argmax(test_output, dim=2).squeeze().numpy() print("Input sequence: ", ''.join([idx_to_char[i] for i in input_data])) print("Predicted sequence: ", ''.join([idx_to_char[i] for i in predicted])) # 可视化损失 plt.plot(losses, label="Training Loss") plt.xlabel("Epoch") plt.ylabel("Loss") plt.title("RNN Training Loss Over Epochs") plt.legend() plt.show()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号