
11.10tips+R语言7章+土培数据分析
ctrl+alt+delete:启动任务管理器,结束软件进程。
vars<-c("mpg","hp","wt")
head(mtcars[vars])
描述性统计分析
summary()函数提供了最小值、最大值、四分位数和数值型变量的均值,以及因子向量和逻
辑型向量的频数统计。
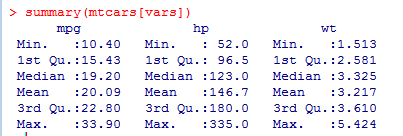
summary(mtcars[vars])
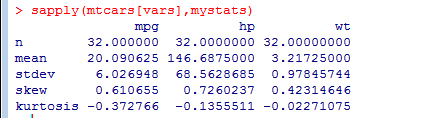
mystats<-function(x,na.omit=FALSE){if(na.omit)
x<-x[!is.na(x)]
m<-mean(x)
n<-length(x)
s<-sd(x)
skew<-sum((x-m)^3/s^3)/n
kurt<-sum((x-m)^4/s^4)/n-3
return(c(n=n,mean=m,stdev=s,skew=skew,kurtosis=kurt))}
sapply(mtcars[vars],mystats)
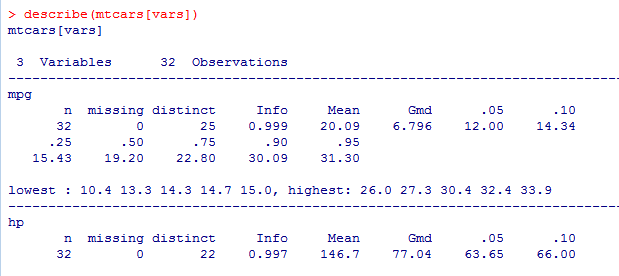
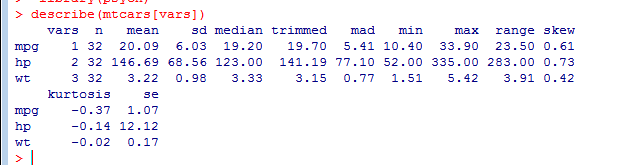
通过Hmisc包中的describe()函数计算描述性统计量
library(Hmisc)
describe(mtcars[vars])
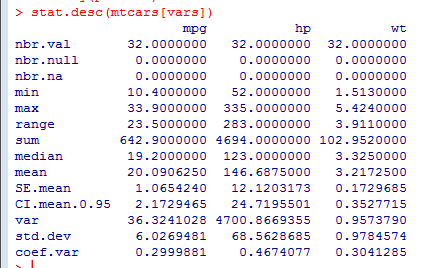
通过pastecs包中的stat.desc()函数计算描述性统计量
library(pastecs)
stat.desc(mtcars[vars])
describe:它可以计算非缺失值的数量、平均数、标准差、中位数、截尾均值、绝对中位差、最小值、最大值、值域、偏度、峰度和平均值的标准误。
library(psych)
describe(mtcars[vars])
使用aggregate()分组获取描述性统计量
aggregate(mtcars[vars],by=list(am=mtcars$am),mean)

aggregate(mtcars[vars],by=list(am=mtcars$am),sd)

使用by()分组计算描述性统计量
dstats<-function(x)(c(mean=mean(x),sd=sd(x)))
by(mtcars[vars],mtcars$am,dstats)
library(doBy)
summaryBy(mpg+hp+wt~am,data=mtcars,FUN=mystats)

R提供了多种检验类别型变量独立性的方法。三种检验分别为卡方独立性检验、Fisher精确检验和Cochran-Mantel–Haenszel检验
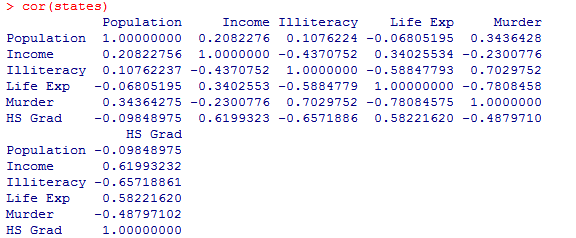
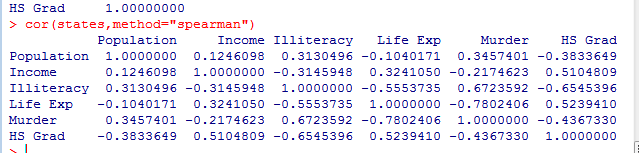
R可以计算多种相关系数,包括Pearson相关系数、Spearman相关系数、Kendall相关系数、偏相关系数、多分格(polychoric)相关系数和多系列(polyserial)相关系数。
Pearson积差相关系数衡量了两个定量变量之间的线性相关程度。Spearman等级相关系数则衡量分级定序变量之间的相关程度。Kendall’s Tau相关系数也是一种非参数的等级相关度量。
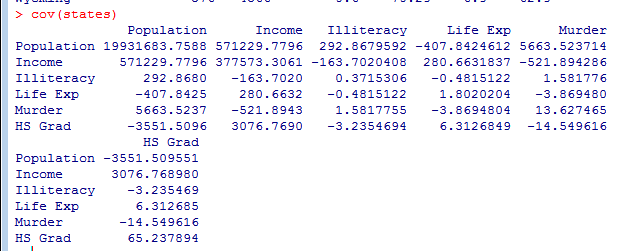
cor()函数可以计算这三种相关系数,而cov()函数可用来计算协方差。两个函数的参数有很多,其中与相关系数的计算有关的参数可以简化为:
cor(x,use=,method=)
states<-state.x77[,1:6]
cov(states)
cor(states)
cor(states,method="spearman")
a<-read.csv("土培11.csv")
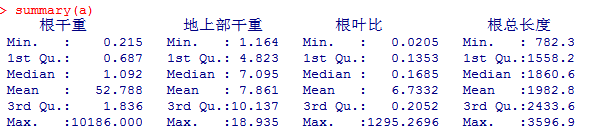
summary(a)
library(Hmisc)
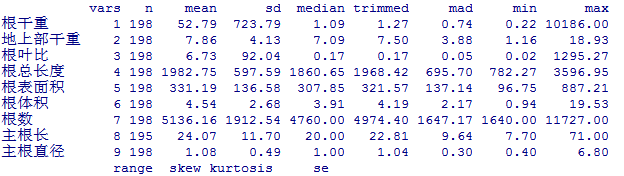
describe(a)
library(pastecs)
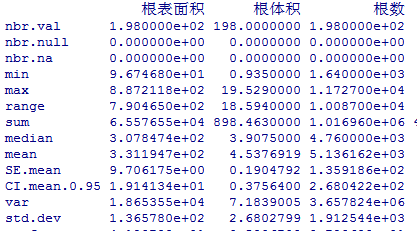
stat.desc(a)
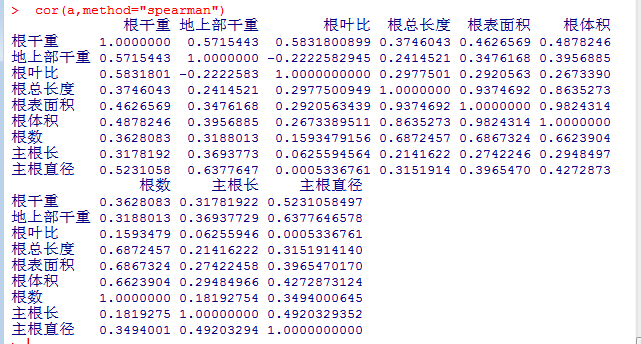
相关性
cor(a,method="spearman")
cor(a,method="pearson")


 浙公网安备 33010602011771号
浙公网安备 33010602011771号