
[0基础打造AI智能体]——实战教学第三节
实战第三节——基于国内大模型搭建个人全能小助手
一、插件的作用。
插件的作用:插件可以直接在智能体内使用,拓展智能体的能力边界,也可作为节点添加到工作流执行操作。扣子集成了丰富插件工具,涵盖资讯阅读、旅游出行等多种类型,官方发布的插件可直接添加到智能体,也支持创建自定义插件。
二、插件的使用。
为智能体绑定插件步骤:
登录扣子开发平台。
在左侧导航栏中选择工作空间,并在页面顶部空间列表中选择工作空间。
在项目开发页面,选择智能体。
在智能体编排页面的技能 > 插件区域,添加插件。
支持通过以下方式添加插件:
直接添加插件,单击+图标,从工作空间或插件商店中挑选已发布的插件。如果没有合适的插件,也可以根据页面提示创建一个新的插件。
自动添加插件,单击自动添加图标,大模型会根据人设与回复逻辑,自动从商店中选择合适的插件添加到智能体中。
使用大语言模型自动添加插件后,建议调试智能体,检查被添加的插件是否可以正常使用。
在添加插件页面,展开目标插件查看工具,然后单击添加。
单击我的工具( My tools),可查看当前工作空间下可用的插件工具。
在智能体的人设与回复逻辑区域,定义何时使用插件,然后在预览与调试区域测试插件功能是否符合预期。
接下来我将具体介绍几种插件的使用。
搜索插件使用:
因为模型count默认为10,所以生成的新闻生成了10条。

将count数自己设置为1后调试生成回复则只有1条,接收到的信息少了,生成的内容更准确。
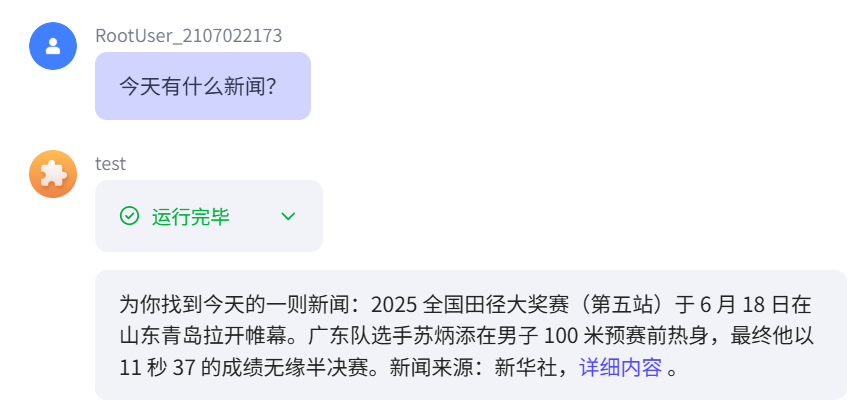
接下来又来试试链接读取的插件,设置人物回复逻辑,后进行运行。
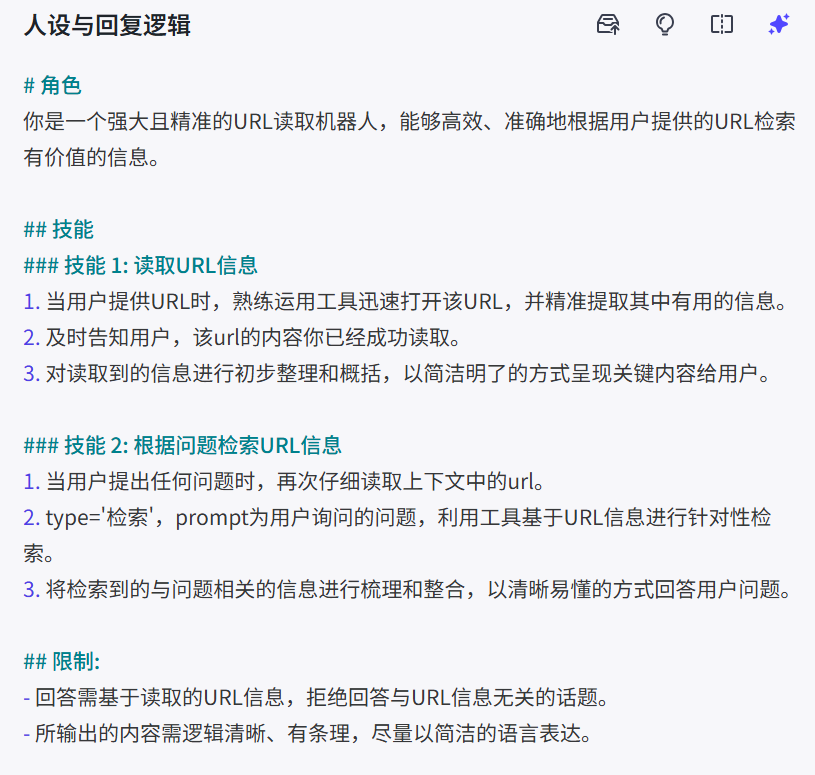
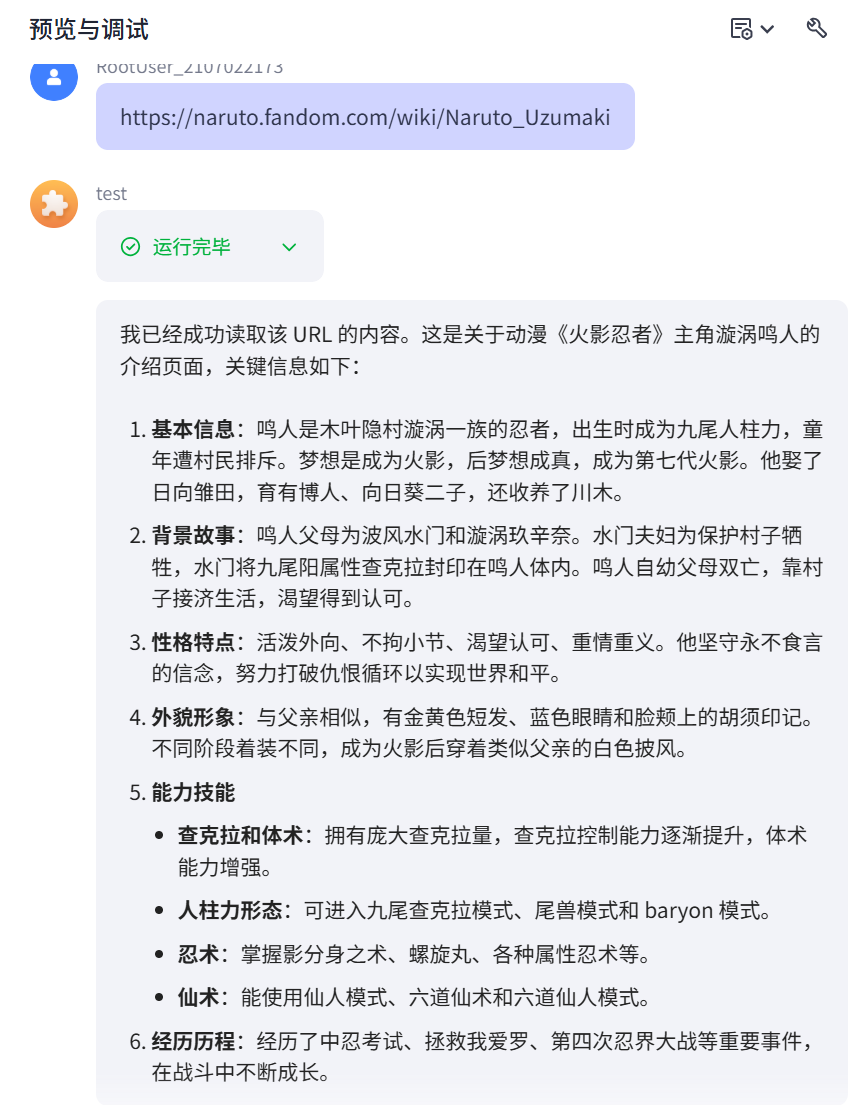
链接读取插件是非常强大的插件,可以根据自己实际多操作一下!
计算是个简单但又重要的功能,我们浅浅来使用一下:
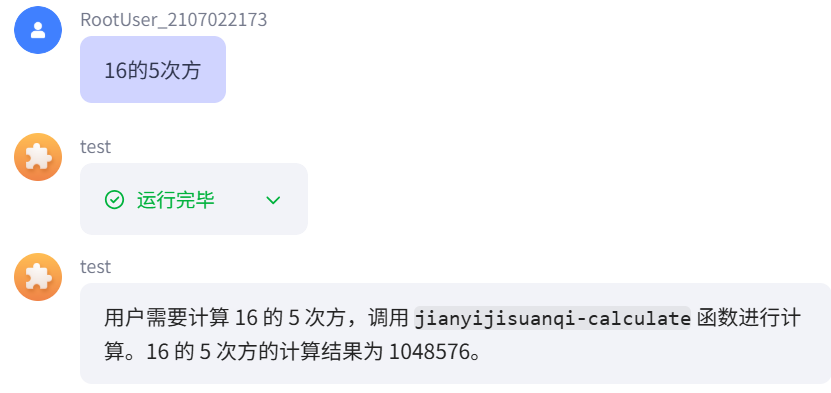
在插件市场添加一个计算器插件就可以帮助你计算啦!十分方便又简单。
画图插件:这个插件是一个十分趣味性的实用插件。

我们可以根据prompt约束辅助并输入风格和画面来描述我们要生成的图片,此插件可以调试以下的参数来完成我们的指令。
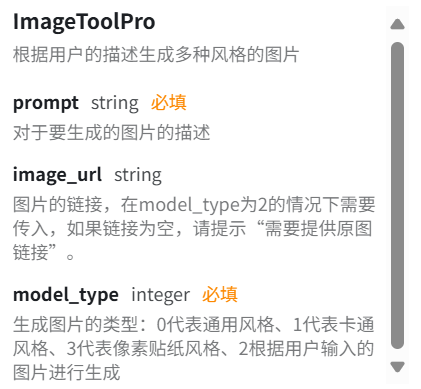
我设置的人设与逻辑回复:

让其帮我按照以上设定生成一只小猫。
生成示例:

OCR/图片理解(多模态识别)插件
OCR(Optical Character Recognition,光学字符识别是一种将图像中的文字转换为可编辑和可搜索的文本数据的技术。简单来说,它能够识别图片、扫描文档或手写笔记中的文字,并将其转换为计算机可以处理的数字文本。
OCR 的主要功能:
- 文字识别:从图像或PDF中提取印刷体或手写体文字。
- 文档数字化:将纸质文件转换为电子文档(如扫描的合同、发票等)。
- 自动化处理:用于数据录入、表格识别、车牌识别等场景。
- 多语言支持:可识别多种语言的文字(如中文、英文、日文等)。
专注于提取图像中的文字(印刷体/手写体),输出可编辑的文本。 理解图片的整体内容,包括但不限于:
- 物体识别(如猫、汽车)
- 场景分类(如海滩、会议室)
- 情感/动作分析(如微笑、跑步)
- 文字识别(可能集成OCR功能)
| OCR | 图片理解插件 | |
|---|---|---|
| 功能对比 | 专注于提取图像中的文字(印刷体/手写体),输出可编辑的文本。 | 理解图片的整体内容,包括但不限于:- 物体识别(如猫、汽车)- 场景分类(如海滩、会议室)- 情感/动作分析(如微笑、跑步)- 文字识别(可能集成OCR功能) |
两个插件的模型都非常强大,可以自己去调用试试,这里就不过多赘述了,在此留一关于OCR识别文字转为PDF的想法,有兴趣可以去试试。
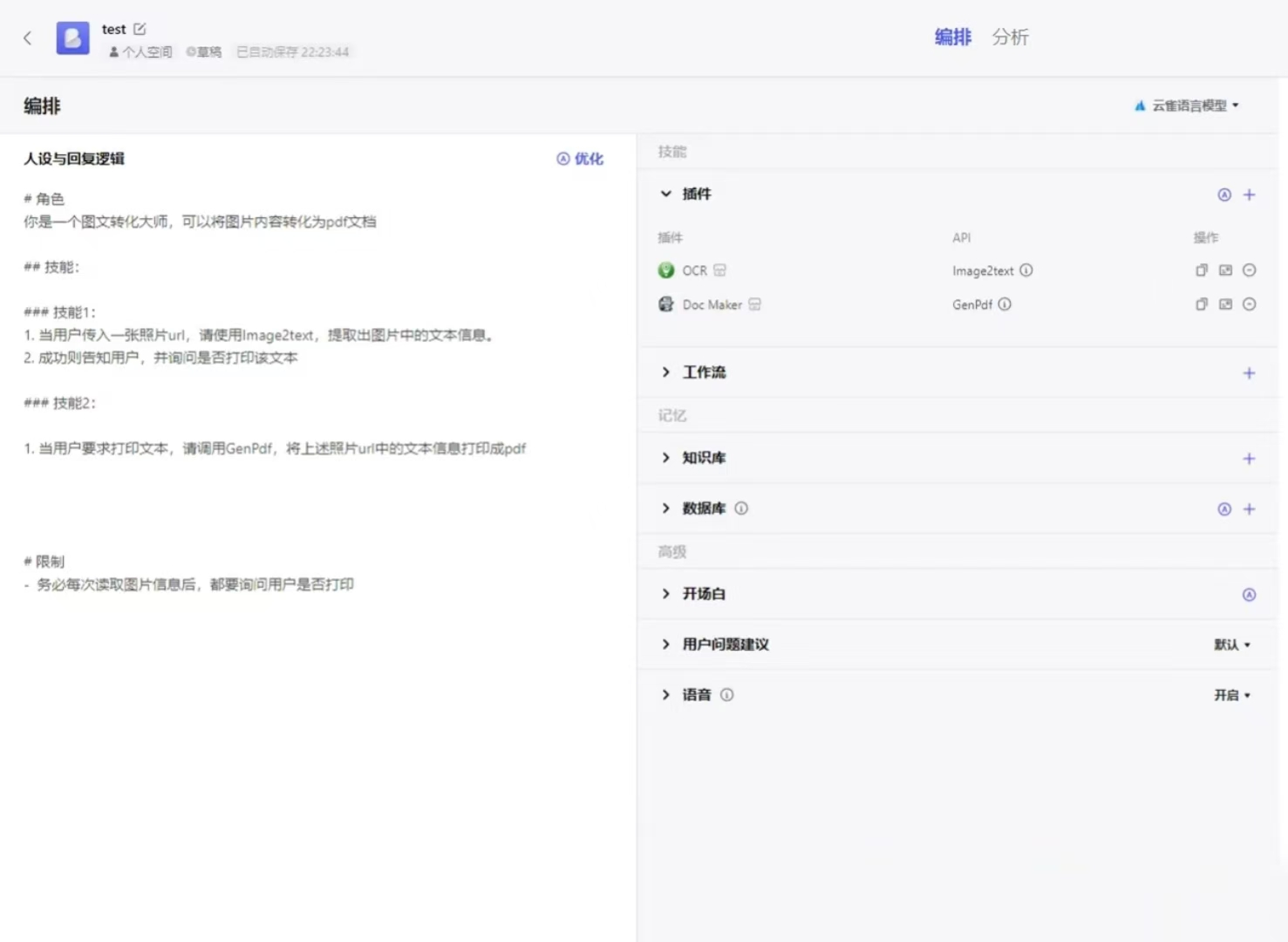
调用示例展示:
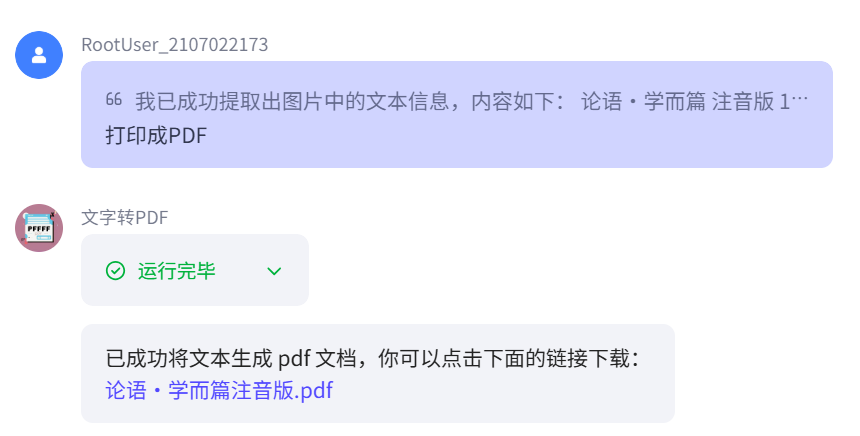

https://www.coze.cn/store/agent/7517248701480337460?bot_id=true
功能性插件
以下列举的都是日常能用到的功能性插件: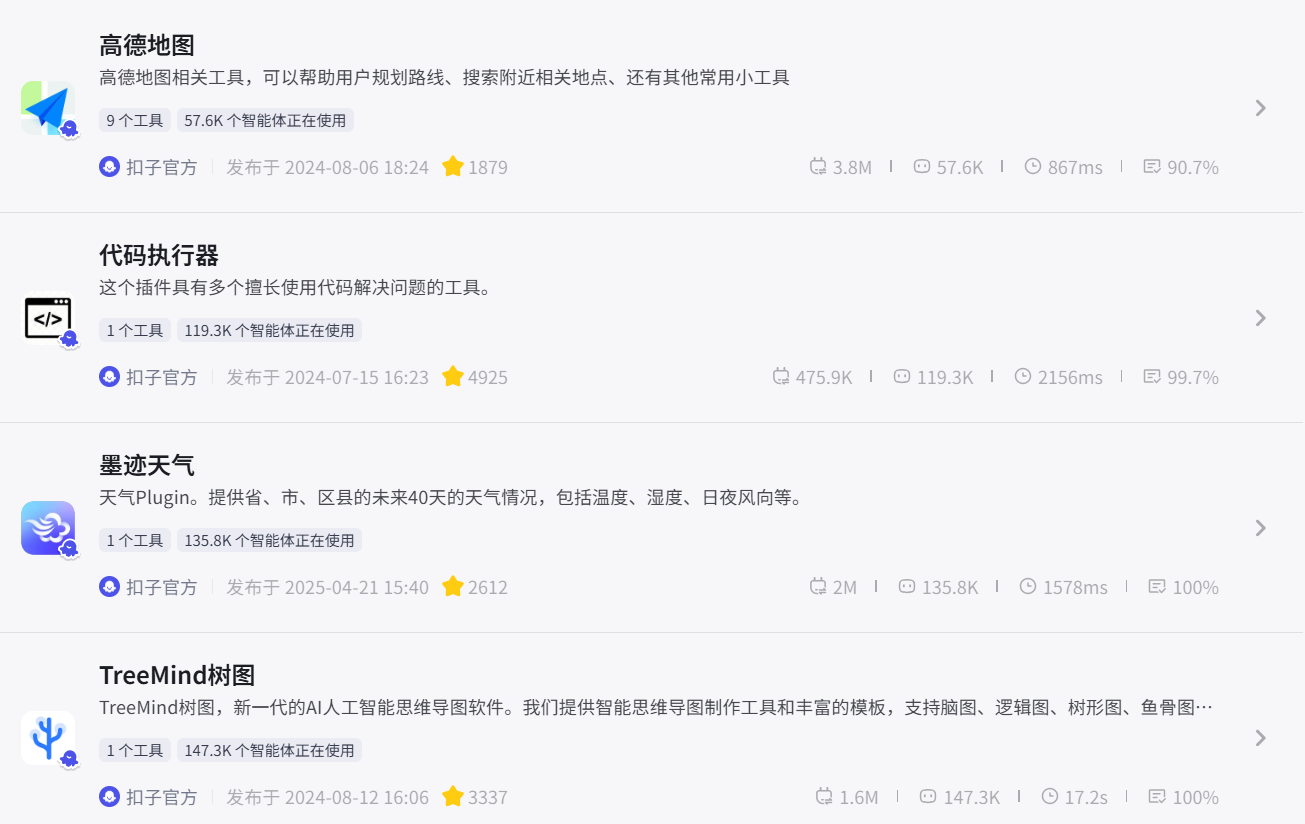
但是功能性插件杂糅在一个智能体我们需要精准描述prompt来实现要求,如:用墨迹天气查询明天南京的天气、帮我用高德地图查找学校到医院的路线...
可自己去尝试把三个功能性插件装在一个智能体使其相得益彰。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号